- The paper introduces MetaBox-v2, a unified platform that abstracts diverse MetaBBO paradigms through a single interface for rigorous, reproducible algorithm evaluation.
- It incorporates scalable test suites with over 1,900 problem instances and vectorized, parallel training techniques achieving 10x–40x throughput improvements.
- Empirical findings highlight trade-offs between strong in-distribution performance and fragile out-of-distribution generalization, emphasizing the need for balanced efficiency metrics.
Introduction and Motivation
Meta-Black-Box Optimization (MetaBBO) operationalizes automated optimizer design using meta-learning, where policies are trained to maximize BBO performance over distributions of tasks. Although initial work on MetaBBO—exemplified by the original MetaBox—focused mainly on RL-driven single-objective algorithm design, rapid advances in the field have diversified both methodological paradigms (to include RL, SL, NE, and ICL) and application domains (including multi-objective, multi-modal, large-scale, and multi-task optimization). Existing benchmarks fail to capture this breadth, hampering rigorous comparative analysis and the discovery of robust generalization patterns.
MetaBox-v2 addresses this deficit via unified interfaces, scalable parallelization frameworks, and an extensive suite of synthetic and realistic benchmarks, providing the means for systematic, reproducible, and extensible evaluation of MetaBBO techniques.
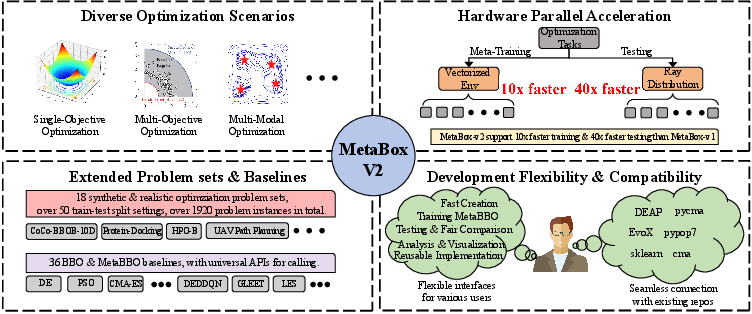
Figure 1: The four novel and user-friendly features of MetaBox-v2.
MetaBox-v2 introduces a single, paradigm-agnostic interface supporting MetaBBO-RL, MetaBBO-SL, MetaBBO-NE, and MetaBBO-ICL. Algorithmic workflows for all approaches—whether requiring reward signals (RL), differentiable gradients (SL), evolvable policy parameters (NE), or in-context learning over text sequences (ICL)—are abstracted through a universal agent and problem class design. The baseline library is expanded to 23 MetaBBO and 13 traditional BBO algorithms, facilitating comprehensive cross-technique comparisons.
Scalable Test Suites and Extensibility
Benchmarking is generalized far beyond single-objective cases: 18 test suites aggregate over 1,900 problem instances spanning all major BBO subfields (SOO, MOO, LSGO, MMO, MTO), derived from established open-source benchmarks covering both theoretical landscapes and application-centric domains (AutoML, protein docking, UAV path planning, and robotics). The platform’s modular design allows seamless integration with external tools such as DEAP, PyCMA, PyPop7, and EvoX.
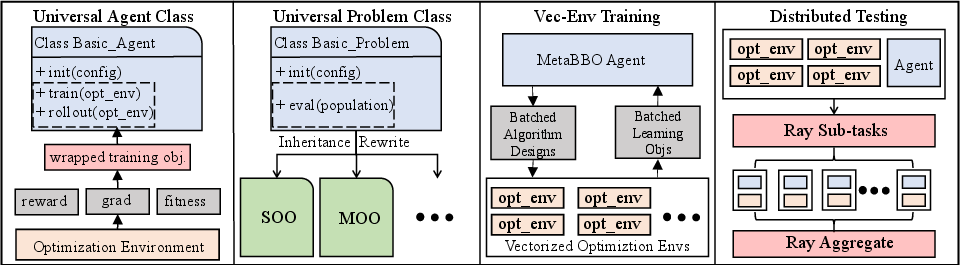
Figure 2: Major architecture adjustments in MetaBox-v2.
Parallelization and Efficiency
MetaBBO’s bi-level nesting incurs expensive compute costs. MetaBox-v2 enables vectorized environments (via Tianshou) for batched, parallel policy updates—substantially accelerating meta-training. Distributed test execution leverages Ray-based multi-core scheduling, supporting four nested-parallelization schemes for optimal hardware utilization, yielding $10$x–$40$x end-to-end throughput improvements relative to the original serial workflows.
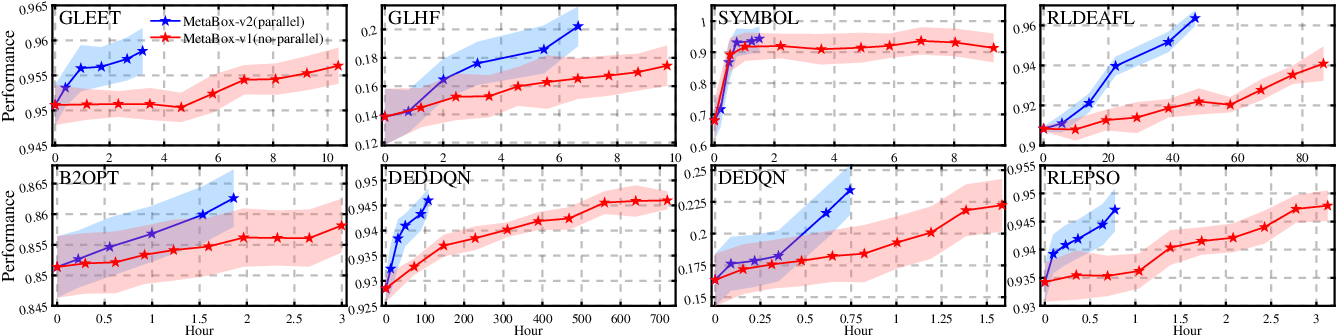
Figure 3: Training improvement curves of baselines on Metabox-v2 and MetaBox, highlighting substantial training efficiency gains.

Figure 4: Testing efficiency comparison of MetaBox-v2 (multiple parallel modes) and MetaBox, showing order-of-magnitude evaluation acceleration.
Beyond standard post hoc analysis, MetaBox-v2 logs detailed trajectory data per episode—solution sequences, objective traces, wall-clock timings—enabling user-defined metric computation. Two critical metrics are built-in: (a) learning efficiency, normalizing test performance by actual meta-training time, and (b) Anti-NFL, measuring out-of-distribution generalization as a normalized drop across disparate test suites. These metrics materially advance the objective comparison and fair ranking of MetaBBO algorithms.

Figure 5: Left: Comparative learning efficiency for MetaBBO baselines. Middle: Anti-NFL indicator (generalization robustness). Right: Non-domination plot for baselines (learning efficiency vs generalization).
Empirical Benchmarking and Insights
Experiments deploy 20 baselines over multiple in- and out-of-distribution test regimes, all using standardized compute protocols and independent replications with controlled random seeds. Training on a portion of bbob-10D, the evaluation covers generalization both to held-out problem instances and diverse external suites (noisy functions, protein-docking, UAV path planning, HPO tasks).
In-Distribution Results
MetaBBO approaches, especially RL-driven variants, display strong performance on held-out synthetic functions, often exceeding traditional BBO optimizers by orders of magnitude in convergence quality within limited evaluation budgets. However, significant variance emerges between different RL formulations—e.g., DEDDQN achieves top ranking on most tasks, while other recent methods lag.
Out-of-Distribution Generalization
Generalization performance is less robust. Traditional BBO algorithms like DE and SHADE maintain stable results on novel suites, while most MetaBBO policies exhibit sharp drops and instability, indicating overfitting to training distributions. Certain algorithms that excel in-distribution (e.g., DEDDQN) underperform when problem features shift significantly, revealing structurally brittle generalization.

Figure 6: Out-of-distribution generalization performance across major baselines for (a) bbob-noisy-30D, (b) protein, (c) uav, and (d) hpob test suites.
Learning Efficiency and Dominance Analysis
Learning efficiency, when normalized by real compute time, does not always correlate with test performance or generalization. RL strategies such as RLDAS achieve balanced improvements per unit resource, whereas heavy-weight methods (e.g., DEDDQN, LES, OPRO) incur prohibitive cost with diminishing returns. Notably, Anti-NFL indicators reveal that some methods (GLHF, LES) generalize better in relative terms even when their absolute performance is inferior, challenging the reliance on raw convergence as a sole benchmark.
No single baseline dominates in (efficiency, robustness) space; trade-offs between overfitting, sample efficiency, and generalization persist. Transformer-based meta-policies (e.g., GLEET) show relative resilience to dimension scaling and domain shift compared to MLP (RLEPSO) or LSTM (LDE) policies during transfer to high-dimensional robotics/NE tasks.
Theoretical and Practical Implications
The systematic evaluation afforded by MetaBox-v2 exposes several critical ramifications:
- Benchmarks limited to in-distribution scenarios offer an overly optimistic view of MetaBBO capabilities; broad-spectrum assessment surfaces overfitting and fragility obscured in prior work.
- Absolute performance alone is insufficient; metrics reflecting sample efficiency and domain transfer capacity are essential for rigorous model comparison—criteria now operationalized via the platform’s extensible metadata.
- The architectural complexity of the meta-policy can be a key determinant of out-of-distribution generalization, raising questions about the inductive biases most conducive to transfer in heavy-tailed optimization domains.
- BBO/MetaBBO benchmarking must move beyond pointwise rankings to multi-objective, non-dominated sorting strategies reflecting cost, robustness, and scaling phenomena.
Conclusion
MetaBox-v2 provides a critical, extensible foundation and empirical lens for the study of MetaBBO algorithm design. Its combination of unified interfaces, robust parallelization, comprehensive benchmarks, and advanced metrics enables thorough, reproducible evaluation of design trade-offs in both traditional and learning-driven algorithm configuration. Large-scale experiments reveal persistent gaps between in-distribution performance and real-world generalization, highlighting the importance of fairness, efficiency, and robustness in future automated optimizer development. The platform’s continued evolution—expanding baselines, refining parallelization, and lowering accessibility barriers—will be instrumental for both research and educational growth in the field.