- The paper introduces OpenVLA-7B, a framework that integrates scalable reinforcement learning with VLA models to master robotic manipulation tasks.
- It employs a transformer-based policy and pseudo reward labeling to overcome sparse reward challenges on the LIBERO benchmark.
- Experimental results show significantly higher success rates over imitation learning baselines across 40 diverse manipulation tasks.
VLA-RL: Towards Masterful and General Robotic Manipulation with Scalable Reinforcement Learning
Introduction
The paper "VLA-RL: Towards Masterful and General Robotic Manipulation with Scalable Reinforcement Learning" (2505.18719) addresses the limitations of Vision-Language-Action (VLA) models currently utilized in robotic manipulation tasks. Traditional high-capacity VLA models have demonstrated impressive capabilities by imitating extensive human demonstrations, yet they often falter in out-of-distribution (OOD) scenarios due to their reliance on offline data. This paper proposes a novel framework, OpenVLA-7B, leveraging scalable reinforcement learning to enhance these models further and achieve superior results in robotic manipulation tasks.
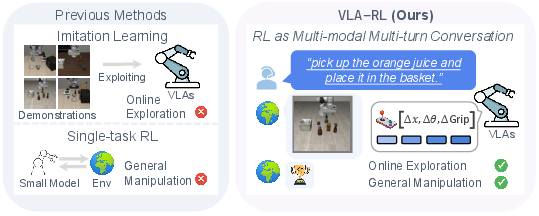
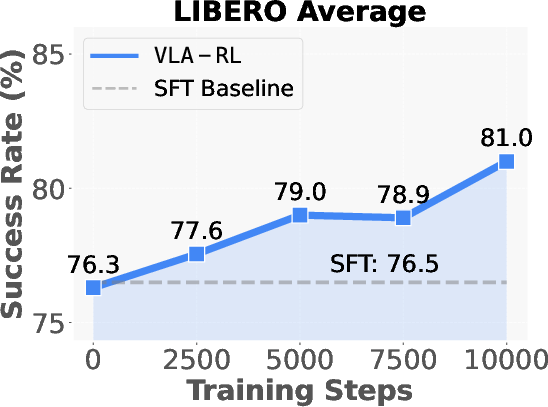
Figure 1: Previous VLAs focus on imitation learning that exploits the offline demonstrations, while explores improving high-capacity VLAs with scalable reinforcement learning. For evaluation, we train OpenVLA-7B to master 40 challenging robotic manipulation tasks in LIBERO, and show a notable consistent improvement over the imitation learning baseline.
Framework Overview
OpenVLA-7B introduces a systematic approach, combining a transformer-based policy with a homogeneous value model, a frozen robotic process reward model, and vectorized environments. The framework aims to improve VLA model performance by adopting online reinforcement learning protocols, which address the challenges posed by sparse rewards in robotic manipulation environments.
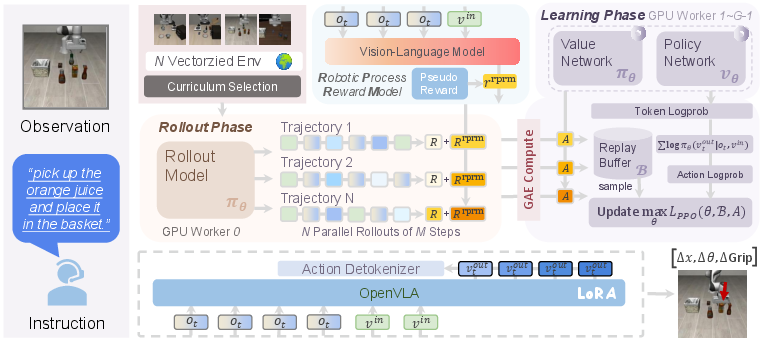
Figure 2: The overall pipeline of , which is composed of a transformer-based policy, a homogeneous value model, a frozen robotic process reward model, and the vectorized environments.
Methodology
OpenVLA-7B utilizes a trajectory-level RL formulation for training, transforming robotic manipulation trajectories into multi-modal, multi-turn conversations. This approach enables the model to perform complex tasks effectively by optimizing trajectories through reinforcement learning. The framework incorporates a robotic process reward model, fine-tuned to densify sparse rewards using pseudo labels, enhancing the RL training efficiency.
Experimental Setup
The model is evaluated using the LIBERO benchmark, a multi-suit robotic manipulation test comprising four task suites: LIBERO-Spatial, LIBERO-Object, LIBERO-Goal, and LIBERO-Long. The OpenVLA-7B demonstrated superior performance over imitation learning baselines, improving success rates significantly and matching the capabilities of advanced commercial models.
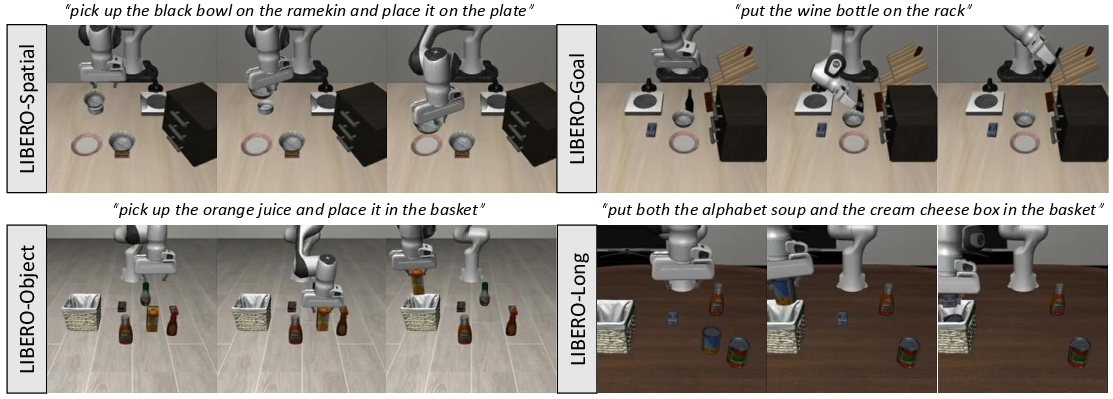
Figure 3: Environments and Tasks. For simulation, we evaluate on a commonly-used robotic manipulation benchmark named LIBERO with four task suites that focus on different challenges.
Test-Time Optimization and Scaling
OpenVLA-7B's training leverages test-time optimizations, illustrating the emergence of inference scaling laws in robotics. The success rates continue to improve with test-time processing, indicating robust adaptability and potential for online data optimization.
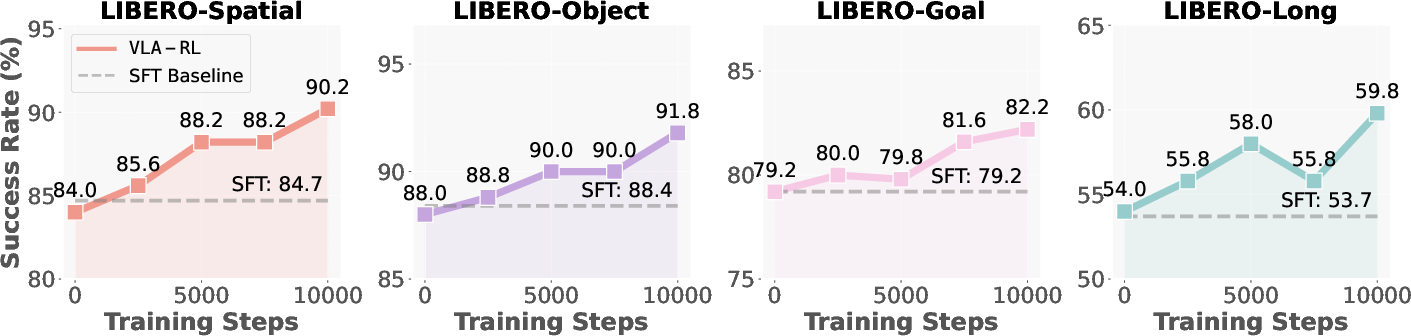
Figure 4: Test-time Scaling Curve. We evaluate the fine-tuned OpenVLA-7B every 2500 training steps on the complete suite and report the average task success rates.
Training Dynamics
The training dynamics of OpenVLA-7B reveal insights into episode lengths, reward dynamics, and policy entropy during the reinforcement learning process. These metrics underscore the model's ability to adapt and refine its strategies to maximize performance efficiently.

Figure 5: Training Dynamics. We draw the length of generated episodes, reward dynamics and rollout entropy along the training process on LIBERO-Long.
Conclusion
The OpenVLA-7B framework demonstrates a significant improvement in robotic manipulation tasks by integrating scalable reinforcement learning with high-capacity VLA models. Despite its achievements, the framework faces challenges, such as effectively extracting pseudo reward labels for more nuanced tasks. Future research will focus on expanding these methodologies to include model types beyond auto-regressive VLAs and leverage real-world experiences for further progress.