- The paper introduces a novel point-and-copy mechanism enabling continuous dynamic referencing of visual tokens in multimodal reasoning.
- Evaluation on benchmarks like MathVista and MathVision shows substantial improvements in visual grounding and inference precision.
- The v1g dataset, with 300,000 multimodal reasoning traces, supports robust training and lays the groundwork for extending dynamic visual grounding to diverse applications.
v1: Learning to Point Visual Tokens for Multimodal Grounded Reasoning
This paper introduces "v1: Learning to Point Visual Tokens for Multimodal Grounded Reasoning," which addresses the challenge of dynamic visual referencing in multimodal LLMs (MLLMs). The core innovation is a point-and-copy mechanism enabling MLLMs to revisit visual tokens dynamically, thereby maintaining grounded reasoning with perceptual evidence throughout the inference process. This mechanism counters the issue of visual grounding decay as reasoning chains lengthen, a common limitation in existing MLLMs.
Methodology
Point-and-Copy Mechanism
The v1 model incorporates an extended architecture to enable pointing to continuous input representations. At each reasoning step, v1 generates a probability distribution over input image positions via a pointing head, which operates alongside the traditional vocabulary logits.
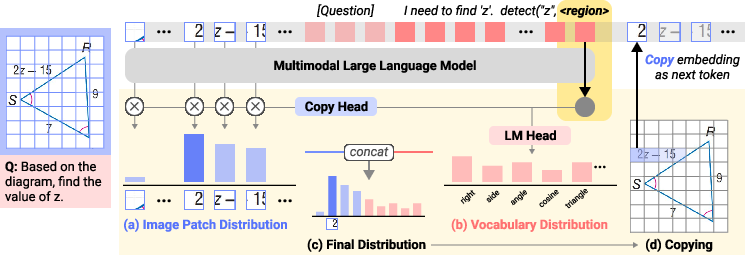
Figure 1: Inference process of v1 with multimodal context encoding and the integration of visual and textual logits.
This pointing distribution allows the model to select specific image regions, inserting their embeddings into the reasoning stream dynamically. This mechanism facilitates repeated and precise visual references, sustaining attention on relevant image regions over extended reasoning chains.
Dataset Construction
The authors created v1g, a comprehensive dataset comprising 300,000 multimodal reasoning traces with interleaved visual grounding annotations. The dataset was constructed through a multi-step pipeline involving oversampling diverse reasoning paths, decomposing them with LLM-guided processes, and grounding visual references by associating them with image bounding boxes.
Empirical Evaluation
v1 was evaluated across established multimodal mathematical reasoning benchmarks like MathVista, MathVision, and MathVerse. The results indicate that v1 outperforms existing models, particularly on complex tasks necessitating precise visual grounding and iterative reference.
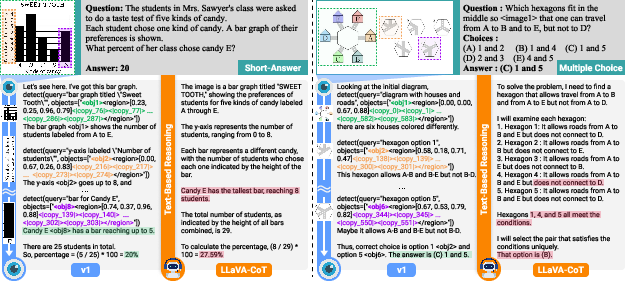
Figure 2: Qualitative comparison on MathVision, where v1 effectively solves both bar graph and spatial reasoning tasks.
Notably, v1's dynamic grounding demonstrated a significant advantage over models like LLaVa-CoT, which misinterpreted visual content in tasks demanding intricate interpretive skills.
Attention Dynamics
The study also analyzed attention patterns showing that v1 maintains focus on relevant visual tokens, utilizing them effectively for reasoning. This is evidenced by the higher attention scores directed to referenced visual content versus the baseline's visual token attention.
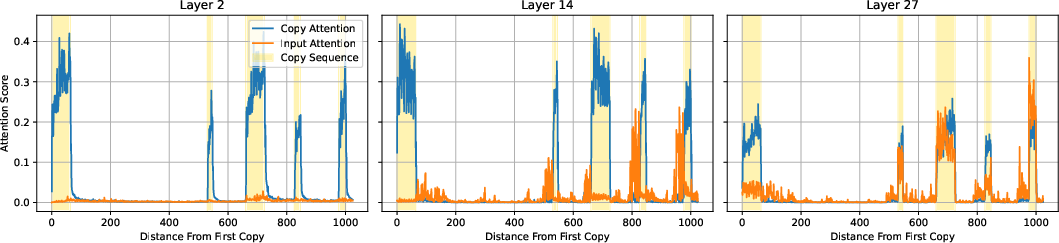
Figure 3: Attention analysis comparing v1's focus on copy tokens versus original visual tokens, highlighting the selective use of the pointing mechanism.
Conclusion
The introduced point-and-copy mechanism in v1 offers a lightweight yet robust solution to preserve visual grounding in multimodal reasoning, enhancing performance on benchmarks significantly without substantial computational overhead. The construction of the v1g dataset further supports this capability, showing potential for broader applications across modalities and tasks.
While v1's approach has proven beneficial in mathematical reasoning contexts, there is room for extending this mechanism to more diverse domains, potentially involving weak supervision and reinforcement learning methodologies. This paper provides a framework that encourages future research in dynamic multimodal reasoning, offering insights into architectures that integrate visual and textual information more effectively.
Future Directions
The point-and-copy strategy can potentially be adapted beyond text modalities, such as integrating speech and video, extending dynamic reference capabilities to include flexible region retrieval and facilitating applications in controllable generation scenarios.
In summary, v1 represents a substantial improvement in the domain of multimodal reasoning, providing a foundational approach that could be built upon to tackle more complex tasks requiring intricate visual grounding and reasoning capabilities.