- The paper presents a data-driven survey analyzing LLM limitations using semi-automated filtering and dual clustering methodologies.
- It reveals a significant focus on reasoning, hallucinations, and safety risks, with LLLMs constituting over 30% of LLM-related papers by 2024.
- Findings emphasize the need for improved LLM reliability using techniques like RLHF and multimodal approaches for safety-critical applications.
Evolving Research on the Limitations of LLMs (LLLMs)
The research paper "LLLMs: A Data-Driven Survey of Evolving Research on Limitations of LLMs" (2505.19240) presents an extensive survey of the burgeoning field of research dedicated to understanding the limitations of LLMs. This survey paper leverages a semi-automated, data-driven approach to analyze research papers published from 2022 to 2024, providing a comprehensive overview of the trends and focal points within the domain of LLLMs. It extracts insights from a massive dataset comprising 250,000 papers, compiling a curated subset of 14,648 papers specifically addressing limitations in LLMs.
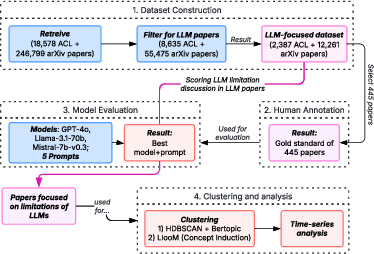
Figure 1: Overview of the pipeline for our systematic literature review.
Data-Driven Approach and Methodology
The authors implemented a robust multi-step methodology to filter and analyze literature on LLLMs from the ACL and arXiv repositories. The filtering process started with keyword extraction, followed by LLM-based abstract classification and expert validation to ensure accuracy. Two clustering methods were employed to categorize the papers: HDBSCAN+BERTopic and LLooM.
Keyword Extraction and Filtering: Using TNT-KID, the study identified significant keywords to curate papers pertinent to LLM limitations. The authors iteratively refined the keyword set through a combination of statistical methods and expert annotation to ensure comprehensive coverage.
LLM-Based Classification: The study employed advanced LLMs, such as Llama-3.1-70b-Instruct, for filtering. These models rated abstracts on their relevance to LLLMs and identified specific evidence related to limitations. The chosen models demonstrated high accuracy in capturing nuanced discussions of LLM limitations.
Clustering Methods: Two distinct clustering methods revealed complementary insights. HDBSCAN+BERTopic provided density-based clusters, while LLooM allowed for multi-label classification and more granular topic identification. This dual approach ensured robustness and credibility in identifying core research themes and trends.
Major Findings and Interpretations
Growth of LLM and LLLM Research:
The study records a dramatic increase in LLM publication volume, with LLLMs constituting a growing proportion of this work. By the end of 2024, LLLMs accounted for over 30% of LLM-related papers, reflecting a significant research interest in addressing the limitations of these models.
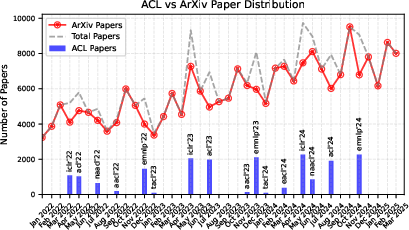
Figure 2: Distribution of papers over time in the crawled dataset, showing ACL papers, arXiv papers, and the total count (ACL + arXiv).
Dominant Topics in LLLM Research:
The analysis identifies key themes such as reasoning limitations, hallucinations, generalization issues, and security risks as dominant topics of concern. Reasoning, in particular, emerged as the most frequently addressed topic across both ACL and arXiv datasets.
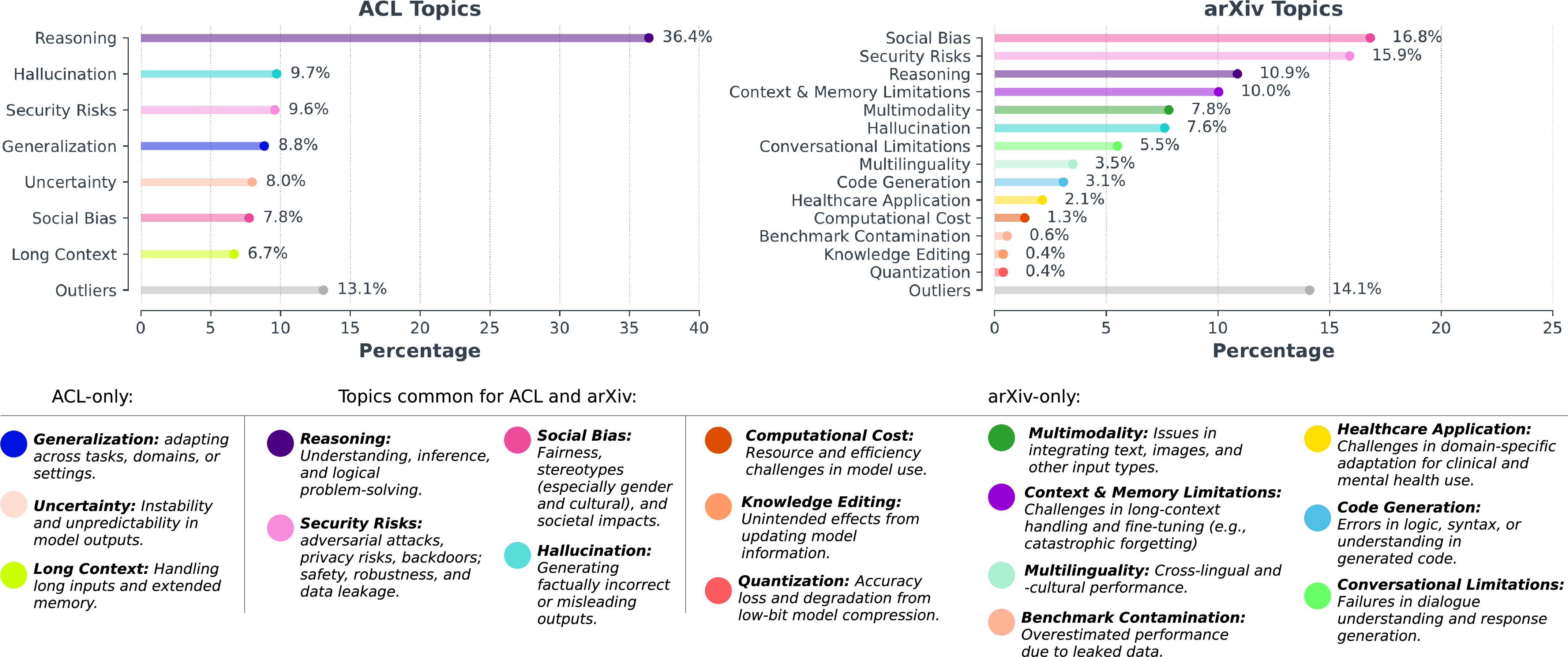
Figure 3: Topics in ACL Anthology and arXiv, clustered using HDBSCAN + BERTopic.
Emerging Trends in ArXiv vs. ACL:
The research highlights differences between ACL and arXiv in topic distribution and trend dynamics. While reasoning remained central in ACL, arXiv showed a marked rise in discussing safety and controllability issues, such as security risks and alignment. This suggests a broader engagement with LLLMs in diverse research communities reflected within arXiv.
Implications for Future LLM Development:
The study underscores the importance of addressing limitations to make LLMs more reliable and trustworthy, particularly in safety-critical applications. It points to an evolving landscape where advanced techniques like RLHF and multimodal capabilities are both promising and challenging, requiring ongoing research to mitigate inherent risks like hallucinations and misalignment.
Methodological Considerations and Limitations
The paper discusses potential biases in LLM-based filtering and clustering techniques due to the reliance on the same models whose limitations are under review. However, the study mitigates these risks via expert validation and by utilizing multiple clustering approaches.
The period analyzed spans from 2022 to early 2025, providing a snapshot that captures the rapid evolution in LLM research and the emergence of new focus areas like multimodality and sophisticated safety mechanisms.
Conclusion
The paper "LLLMs: A Data-Driven Survey of Evolving Research on Limitations of LLMs" provides a comprehensive and nuanced analysis of the research trajectory focusing on LLM limitations. By highlighting key trends, dominant themes, and the dynamics between ACL and arXiv repositories, the study sets the stage for future research on improving LLMs' capabilities while effectively addressing their limitations. It advocates for a balanced approach that considers both scientific advancements and potential risks associated with deploying LLMs in real-world, high-stakes environments.