- The paper introduces a centralized RL-driven orchestrator ('puppeteer') that dynamically activates agents to optimize task performance and reduce computational overhead.
- It demonstrates significant performance improvements across multiple datasets, with notable gains such as a Titan subspace score increase from 0.6893 to 0.7731 while lowering token usage.
- Emergent collaboration structures like compaction and cyclicality reveal how adaptive agent activation can enhance scalability and efficient resource allocation.
Multi-Agent Collaboration via Evolving Orchestration: A Technical Overview
Motivation and Problem Statement
LLMs have demonstrated success in complex reasoning and planning tasks. However, as the scope of tasks expands—particularly with increased heterogeneity and specialization—monolithic LLM paradigms become inefficient for scalable, compositional intelligence. Much recent work focuses on multi-agent LLM systems, but prevalent approaches either employ static agent topologies or delegate orchestration via naïve or rigid protocols, both failing to adaptively optimize collaboration overhead as the agent pool and task complexity escalate. The paper "Multi-Agent Collaboration via Evolving Orchestration" (2505.19591) presents a rigorous framework in which agent collaboration is governed by a dynamic, reinforcement-learned centralized orchestrator ("puppeteer"), yielding both substantial performance and efficiency gains across diverse task domains.
Methodology
The core proposition is encapsulated in a puppeteer-style paradigm: a centralized orchestrator observes the evolving global system state and, at each step, determines which agent ("puppet") to activate and with which context and tools. This process is formalized as a sequential decision problem—each orchestration step constitutes a Markov Decision Process (MDP) action—addressing both scalability of agent selection and adaptability to real-time reasoning needs.
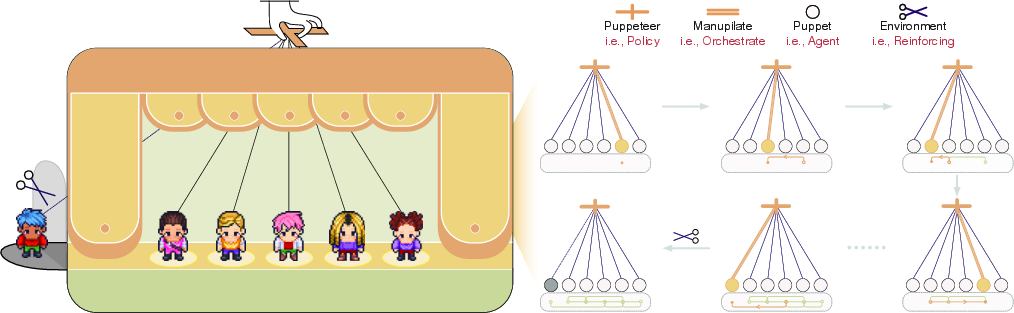
Figure 1: Architectural depiction of the centralized orchestrator adaptively determining agent activations and culling ineffective agents, forming an implicitly evolving inference graph.
Policy Learning and Evolution
A critical design aspect is reinforcement learning (RL)-driven policy optimization. The orchestrator’s policy πθ(at∣St,τ) is updated using REINFORCE with returns reflecting both task reward (solution quality) and computational cost (proxied chiefly by token usage). The reward function is explicitly formulated to penalize inefficiency, thus driving the policy towards agent chains that are both accurate and cost-minimal. The agent pool is instantiated as tuples of foundation models, prompting strategies, and external tools, supporting high compositional expressiveness.
Upon each episode (task-solving attempt), a terminal reward combines correctness (or graded response for open tasks) with negative terms scaled by aggregate FLOPs/token expense. The orchestrator progressively learns to activate only those agents and tool-augmented strategies that demonstrably contribute to final performance, suppressing or culling redundant trajectories.
Empirical Evaluation
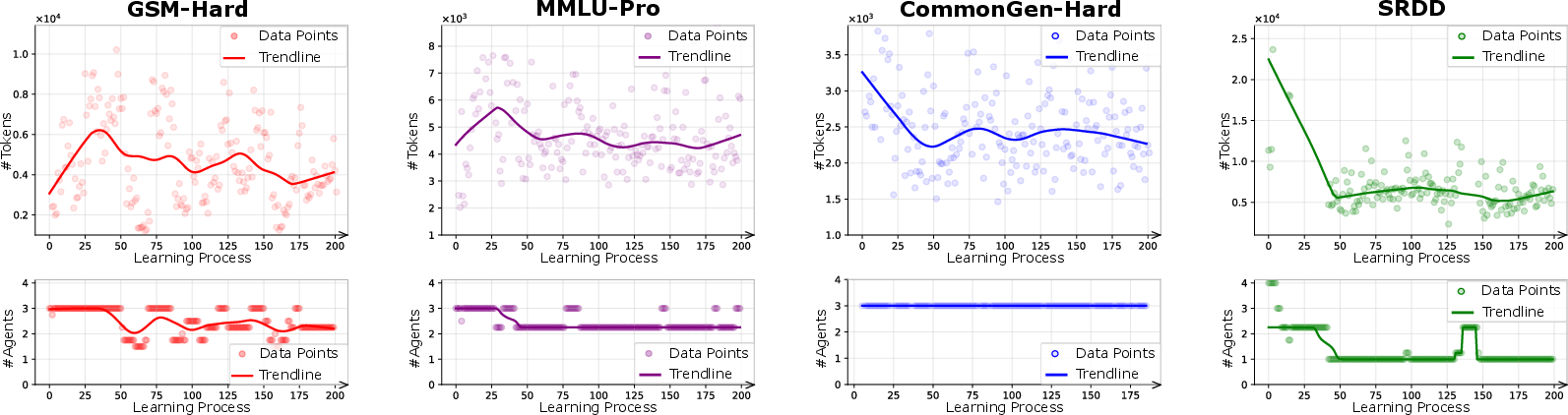
The framework is evaluated on a suite of closed-domain (GSM-Hard, MMLU-Pro) and open-domain (SRDD, CommonGen-Hard) datasets, using both homogeneous (identical base LLM per agent) and heterogeneous (diverse LLMs) agent pools, stratified into Titan (large models) and Mimas (smaller models) subspaces. Baselines encompass single-agent (Self-Refine, AFlow), multi-agent static graph (MacNet), and code-evolution-based orchestration (EvoAgent).
Key claims, directly supported by results:
Analysis of Emergent Collaboration Structures
Dynamic orchestration invigorates the expressiveness of agent interaction topologies, producing organizational structures far richer than canonical trees/chains. Initial episodes yield exploratory, loosely coupled topologies with multi-branch expansion. RL-driven evolution, however, leads to two striking emergent phenomena:
- Compaction: The interaction graph densifies, with orchestration concentrating on a recurring subset of high-utility agents. Communication channels become focused, reducing overall path length and agent participation.
- Cyclicality: Closed loops and feedback cycles become common, supporting recursive critique, consensus formation, and robust iterative refinement—a marked departure from acyclic, hand-designed multi-agent graphs.
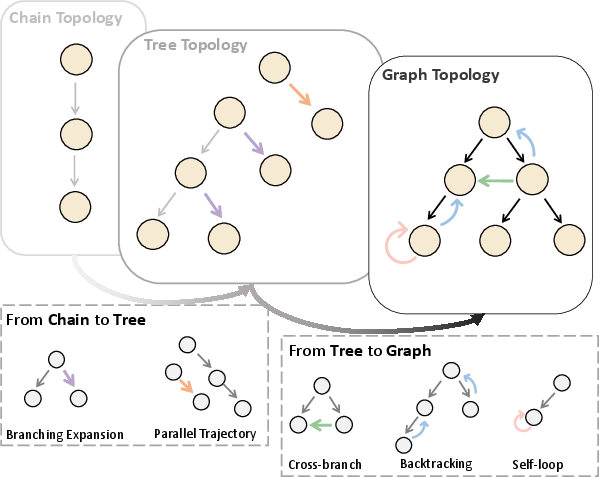
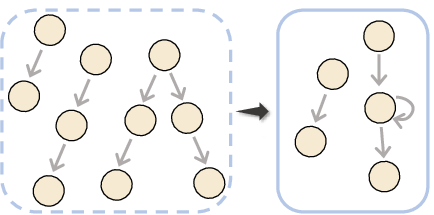
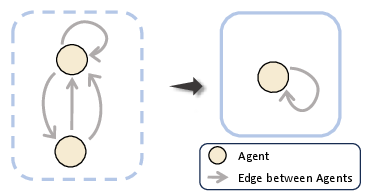
Figure 3: Illustration of evolved interaction topologies—a general directed graph reflecting flexible re-activation and feedback.
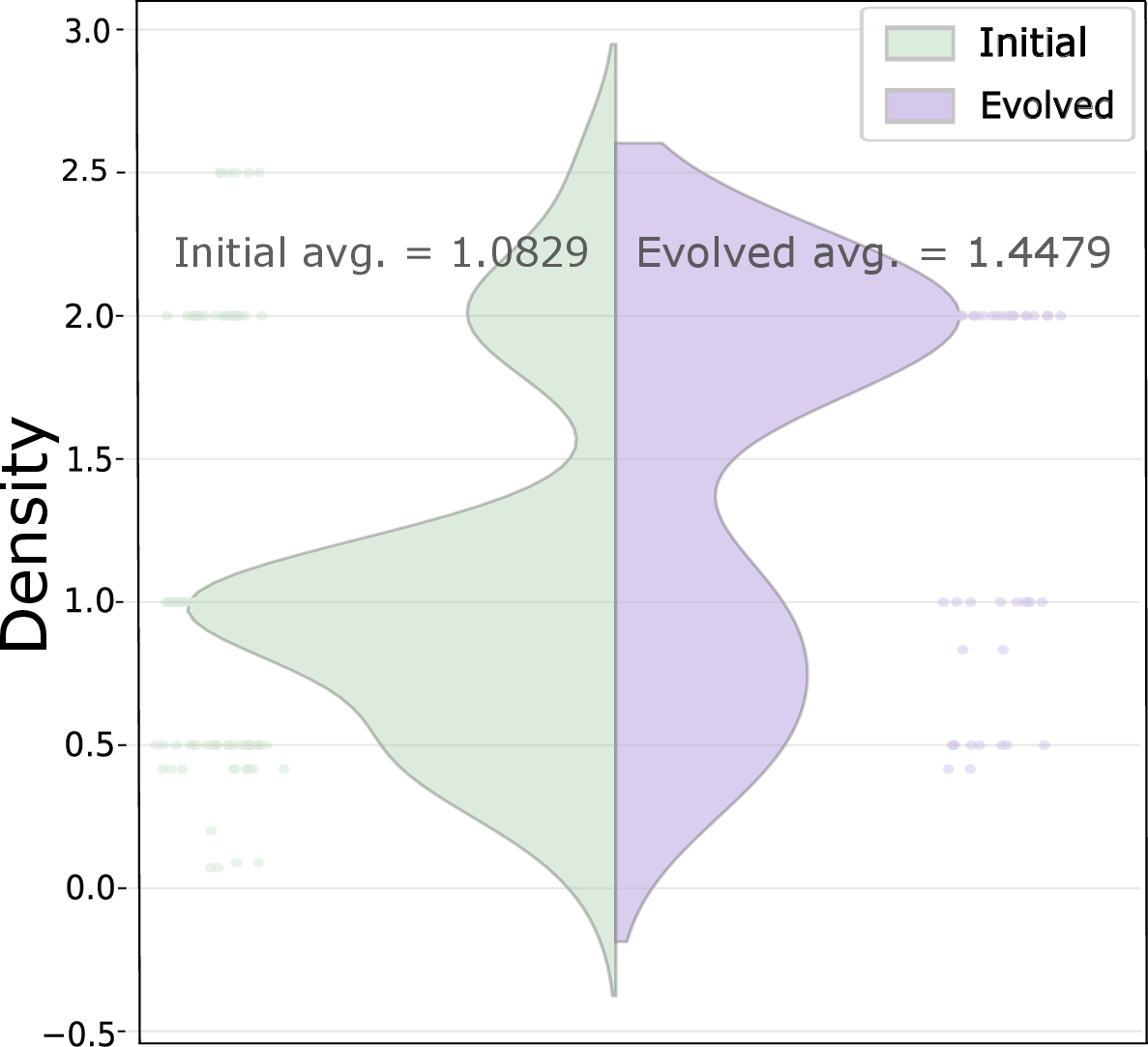
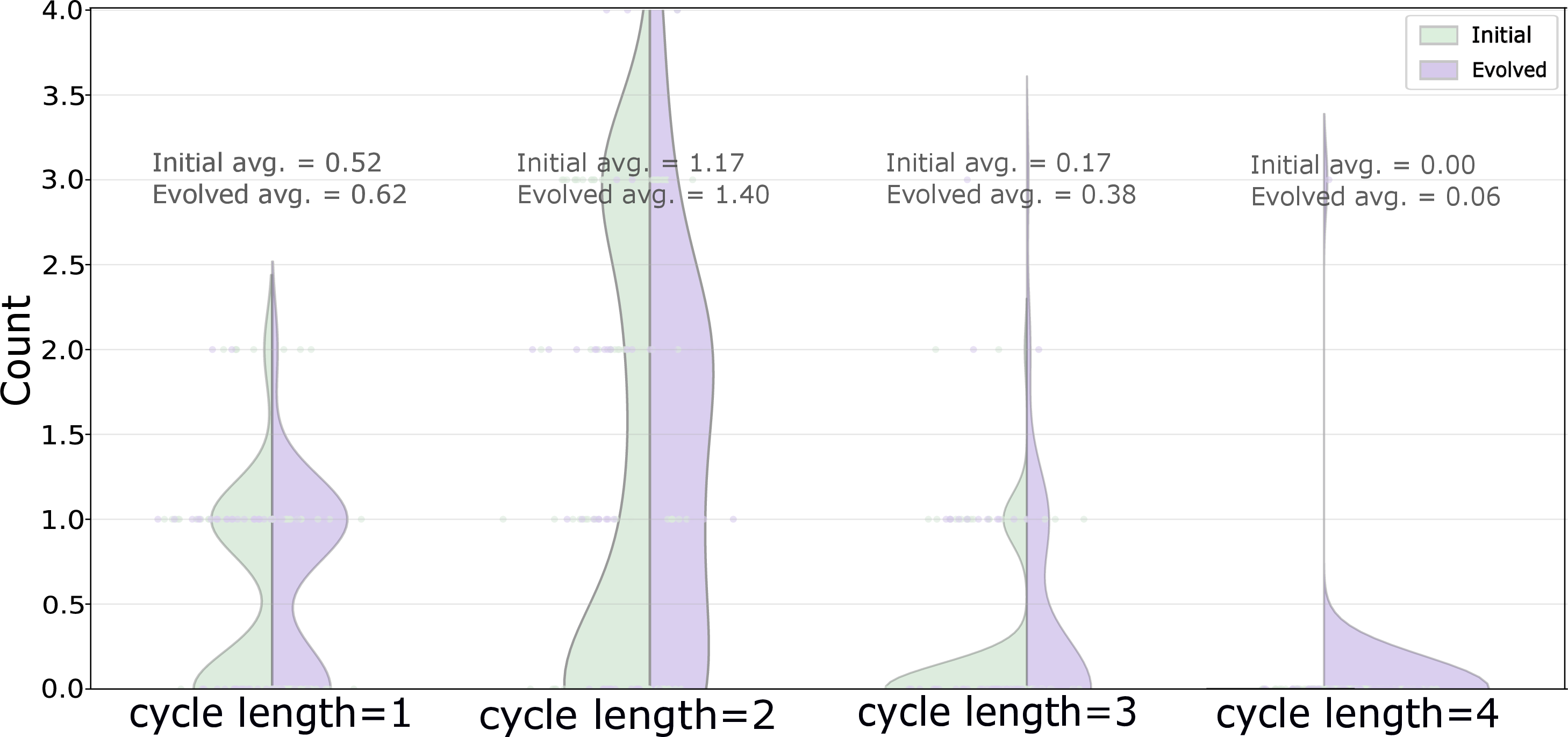
Figure 4: Distributional shift towards increased graph density (compaction) and cycle prevalence (cyclicality) over training epochs.
These motifs, especially compaction and cyclicality, are fundamental to the system's ability to balance expressiveness with parsimony, supporting robust and high-throughput inference.
Efficiency Controls and Topological Constraints
The framework supports topological hyperparameterization to further regularize computational budget. Constraints on chain depth (reasoning length) and exploration width (parallel agent path count) influence the token/performance trade-off. Empirically, default moderate settings yield optimal performance-to-cost ratios, whereas excessive width/depth induce redundancy and degraded return per token.
Theoretical and Practical Implications
The results demonstrate that expressiveness in multi-agent reasoning need not sacrifice efficiency; with RL-driven orchestration, multi-agent LLM systems can break the classical trade-off between coordination overhead and solution quality. This carries implications for both scalable agent deployment (tasks with growing workflow complexity) and the design of practical compound AI systems—where diverse agent pools, each endowed with specialized skills and tool APIs, must be leveraged dynamically.
From a theoretical lens, the work connects organizational topology evolution (a classic theme in MARL and organizational theory) to the emergence of specialization and consensus mechanisms in decentralized AI collectives. The learning-based, centralized orchestration mechanism provides a robust alternative to evolutionary search or hand-crafted agent workflow, ensuring both adaptability and tractability.
Conclusion
"Multi-Agent Collaboration via Evolving Orchestration" rigorously establishes the feasibility and benefits of RL-driven, centralized multi-agent orchestration for LLMs. The methodology achieves state-of-the-art task performance with concurrent reductions in computation; it naturally induces compact, cyclic organizational structures that underpin both effectiveness and efficiency; and it supports practical extensibility via topological and reward-shaping controls.
Future directions include integrating fine-grained intermediate rewards, enabling online agent/tool pool adaptation, and extending orchestrator observation granularity for richer context-aware decision making. These advances are poised to facilitate robust, scalable, principled LLM-based collectives suitable for a wide variety of real-world, open-ended reasoning and control tasks.