- The paper introduces APE, a novel method that fine-tunes LLMs incrementally to achieve task-specific improvements with minimal compute.
- APE employs small data perturbations and selective updates based on metrics like BLEU and ROUGE, preserving pre-trained knowledge.
- Experimental results show significant gains, including a 33.9% improvement in BLEU score, highlighting APE's efficiency in resource-constrained settings.
APE: Selective Fine-tuning with Acceptance Criteria for LLM Adaptation
Introduction to APE
The paper introduces Adjacent Possible Exploration (APE) as an innovative approach to fine-tuning LLMs for specific tasks under computational constraints. APE leverages small, iterative data perturbations, enabling task-specific adaptations without extensive retraining. This method stands out for its simplicity, effectiveness, and low resource requirements, which contrast with more complex techniques like LoRA. APE accomplishes significant performance improvements using minimal compute resources, demonstrating conceptual clarity by drawing inspiration from evolutionary theories such as Stuart Kauffman's "adjacent possible."
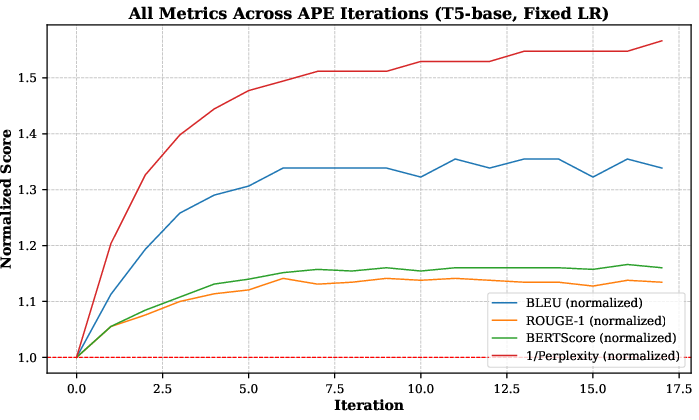
Figure 1: Performance trends for the full experiment (4,000 training samples, 17 iterations with a fixed learning rate lr=3.10−6).
Methodology
APE’s core methodology involves selectively fine-tuning LLMs on small batches of data (around 200 examples per batch), with each iteration focusing on retaining only beneficial updates. This incremental, data-centric approach is both adaptive and efficient, exploiting "adjacent" possibilities within the parameter space akin to evolutionary niche expansions. APE applies evolutionary epistemology principles, viewing LLM adaptation as an ecosystem where controlled data tweaks ensure focused exploration and mitigate risks such as catastrophic forgetting. This enables preserving pre-trained knowledge while precisely steering the model towards enhanced task-specific outcomes.
To model the iterative performance growth, APE utilizes a logistic equation, capturing the constrained trajectory towards a theoretical maximum Smax, with the performance represented by S(t) at iteration t. Such formalization structures and guides the data exploration process systematically rather than predicting exact outcomes, guiding dynamic adjustments through evidence-backed heuristics.
Implementation Details
Implementing APE requires a pre-trained LLM and involves the following steps:
- Initial Setup: Begin with a baseline evaluation using task-specific metrics such as BLEU, ROUGE, and perplexity on a specified dataset.
- Perturbation Process: Iteratively fine-tune using selected data subsets while maintaining a minimal learning rate (e.g., lr=3.10−6) to ensure consistency and reproducibility.
- Performance Evaluation: Retain model updates only if there's a measurable improvement in performance metrics, maintaining task focus and computational efficiency.
- Iterative Refinement: Complete multiple cycles to solidify performance gains through incremental and controlled data adjustments.
This process is computationally efficient, demonstrated on a T4 GPU for the CNN/DailyMail dataset, reflecting the method's accessibility in resource-constrained environments.
Experimental Results
Quantitative results exhibit a significant BLEU score improvement (33.9%), alongside enhancements in ROUGE, BERTScore, and Pliperxity metrics. Human evaluations on qualitative measures such as fluency, factual accuracy, and informativeness further affirm APE's effectiveness, suggesting robust real-world applicability.
The controlled experimental setup maximizes the benefits of small perturbations, confirming through ablation studies that the chosen perturbation size strikes a balance between task improvement and computational constraints. Despite minor limitations in capturing fine detail consistently, the method remains practical and highly relevant for researchers seeking efficient LLM adaptations without high-end hardware.
Conclusion
APE establishes itself as a practical framework for LLM adaptation, leveraging data-centric methods to achieve substantial task-specific improvements. It differentiates from conventional strategies by maintaining full-parameter updates while optimizing through structured, data-driven exploration. Future research should explore scaling APE to larger models and diverse tasks across various domains, confirming its scalability and robustness further. Overall, APE provides a strategic, resource-efficient alternative, broadening the utility of LLMs in computationally limited scenarios.