- The paper introduces STeP, a novel training methodology that uses synthetic self-reflected trajectories to improve LLM agent performance.
- It employs a partial masking strategy during supervised fine-tuning to prevent error propagation and mitigate catastrophic forgetting.
- Experimental results on ALFWorld, WebShop, and SciWorld show that STeP outperforms traditional expert trajectory training methods.
Training LLM-Based Agents with Synthetic Self-Reflected Trajectories and Partial Masking
The paper "Training LLM-Based Agents with Synthetic Self-Reflected Trajectories and Partial Masking" introduces STeP, a novel training methodology for improving the performance of LLM-based agents. This approach is designed to overcome the limitations of naive distillation methods, which often result in performance plateauing and the propagation of errors in agent trajectories.
Introduction
STeP aims to enhance the self-reflective capabilities of LLM-based agents using synthetic self-reflected trajectories coupled with a partial masking strategy. By integrating reflections and corrections of error steps, STeP empowers LLM agents to effectively learn from teacher models and develop self-reflective and corrective behaviors. Experiments demonstrate that STeP significantly improves agent performance in tasks such as ALFWorld, WebShop, and SciWorld, contrasting with the stagnation observed using traditional expert trajectory training methods.
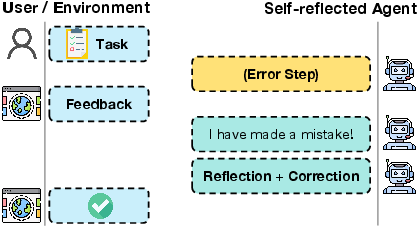
Figure 1: A self-reflected agent could autonomously identify, reflect on and correct errors based on interaction history.
Methodology
Agent Initialization
The first stage involves creating a base LLM agent via supervised fine-tuning (SFT) on a subset of successful expert trajectories, improving fundamental instruction-following skills. This sets a solid foundation for subsequent advanced learning stages.
Synthesizing Self-Reflected Trajectories
In this stage, interactions between the base LLM agent and its environment are guided by a stronger LLM teacher model. The teacher evaluates actions on-the-fly, providing real-time reflections and corrections for errors detected in the trajectories. This approach minimizes error propagation and facilitates the generation of refined, task-completing trajectories, which are then converted to the ReAct format.
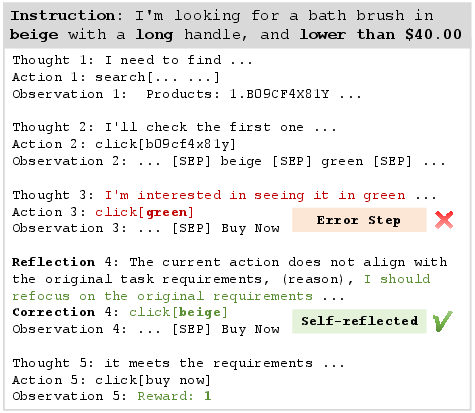
Figure 2: Self-Reflected Trajectories on WebShop.
SFT with Partial Masking
To prevent the learning of erroneous steps, Partial Masking is utilized during the training phase. This technique masks incorrect thoughts and actions, thereby ensuring the agent internalizes only accurate steps and reasoning from the training trajectories. This mitigation strategy counters the effects of catastrophic forgetting that can occur post-SFT.
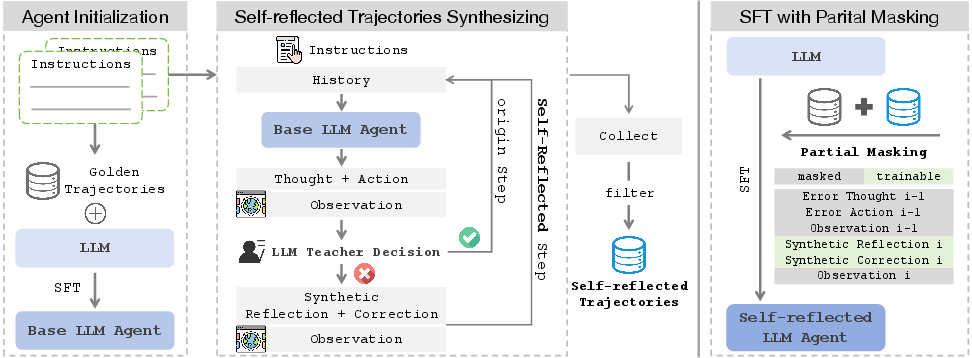
Figure 3: STeP utilizes golden trajectories and corresponding instructions to train a Self-reflected LLM-based agent through three stages. Stage 1: Agent Initialization; Stage 2: Self-Reflected Trajectories Synthesizing; Stage 3: SFT with Partial Masking.
Experimental Results
Dataset and Evaluation
Experiments were conducted on three tasks: ALFWorld, WebShop, and SciWorld, using datasets filtered to include only successful trajectories. These tasks test agents on simulated household, shopping, and science experiment environments. Evaluation metrics included average reward and task completion rate, showcasing STeP’s effectiveness in improving LLM agent performance.
Comparison and Analysis
The agent trained using STeP consistently outperformed models trained solely on expert trajectories and other meta-methods. Compared to the baseline models, STeP provides substantial performance gains across all tasks, demonstrating improved learning efficiency with fewer trajectories required.
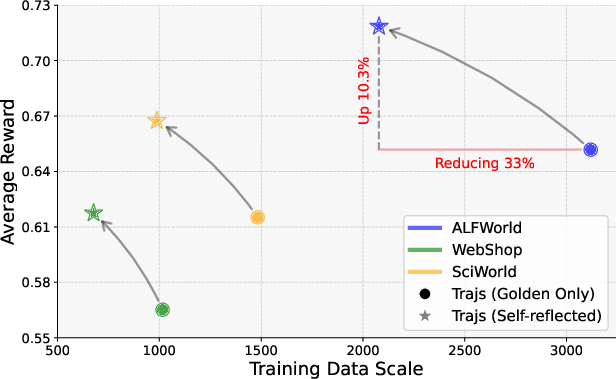
Figure 4: Compared to golden only, self-reflected trajectories help LLMs learn more effectively and efficiently.
Additionally, several ablation studies verified the necessity and effectiveness of both self-reflected trajectories and the partial masking strategy. For example, the exclusion of partial masking leads to decreased performance in error-prone task environments.
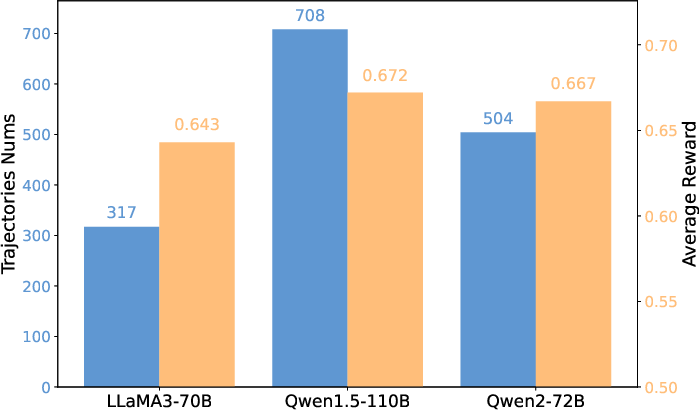
Figure 5: The number of Self-Reflected Trajectories generated by different teacher models, along with the average reward of the LLM-based agent trained on them.
Conclusion
The STeP methodology detailed in this paper provides a significant advancement in the training of LLM-based agents. By integrating self-reflected trajectories and employing partial masking, the capability of agents to reflect on and correct errors is notably enhanced. Future research could explore further refinement of trajectory synthesis procedures and partial masking techniques, aiming to reduce reliance on powerful teacher models and increase the autonomy and robustness of open-source LLM agents.