- The paper demonstrates that integrating weight re-initialization with structured pruning significantly reduces performance degradation in LLMs under aggressive compression.
- The methodology introduces innovative techniques such as CLAP and SLNP, optimizing attention and normalization layers for efficient model compression.
- Experimental results show that Pangu Light-32B outperforms Qwen3-32B in accuracy and throughput on Ascend NPUs, highlighting its practical impact.
Pangu Light: Structured Pruning and Acceleration of LLMs
Introduction
The work titled "Pangu Light: Weight Re-Initialization for Pruning and Accelerating LLMs" (2505.20155) addresses the issue of the immense computational demands associated with LLMs. The paper acknowledges that while LLMs achieve state-of-the-art performance across various tasks, their size poses substantial challenges in terms of inference costs, impacting their practical deployment. Thus, the paper introduces Pangu Light, a framework that integrates structured pruning with novel weight re-initialization strategies to mitigate performance degradation commonly associated with aggressive pruning.
Methodology
The Pangu Light framework advances structured pruning by addressing critical challenges in model compression. Existing methods often fail to cope with performance drops resulting from simultaneous pruning of model width and depth. The authors posit that weight re-initialization is a critical, often overlooked, step in successfully recovering from aggressive pruning. To this end, Pangu Light introduces techniques like Cross-Layer Attention Pruning (CLAP) and Stabilized LayerNorm Pruning (SLNP). CLAP allows for the retention of important attention signals across pruned layers, while SLNP addresses the instability induced by pruning RMSNorm layers.
Additionally, Pangu Light leverages specialized optimizations such as absorbing Post-RMSNorm computations and tailors its pruning techniques to leverage the Ascend NPU architecture's capabilities.
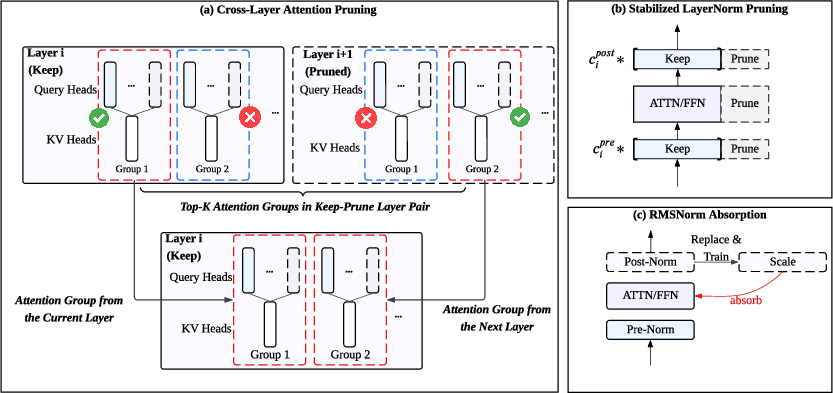
Figure 1: Conceptual overview of the Pangu Light methodology, illustrating its integrated approach that combines importance-based structural pruning with novel weight re-initialization strategies (a)(b) and specialized normalization layer optimization (c).
Experimental Results
The framework's practical effectiveness is evaluated on the Pangu-38B model, resulting in the Pangu Light series. These models demonstrate superior accuracy-efficiency trade-off metrics compared to established models like the Qwen3 series. For instance, Pangu Light-32B achieves an average score of 81.6 and a throughput of 2585 tokens/s on Ascend NPUs, surpassing Qwen3-32B's 80.9 average score and 2225 tokens/s throughput.
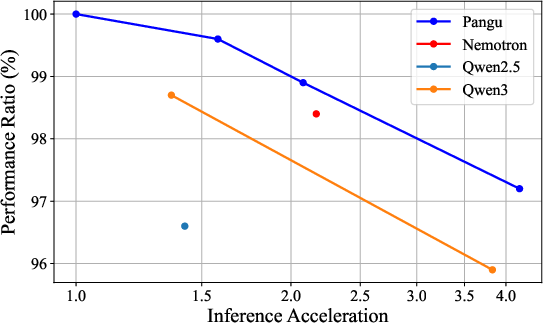
Figure 2: Performance ratio with respect to pruning ratio and acceleration ratio, illustrating the accuracy-efficiency trade-off. The Pangu Light series exhibits a more favorable curve than those of both the Qwen3 series.
Pangu Light enhances model compression techniques by expanding beyond traditional structural pruning and knowledge distillation approaches. It effectively combines these methods with novel re-initialization strategies, offering a robust alternative to existing models like Nemotron and Minitron. By enabling efficient LLM deployment on specialized hardware while preserving performance, Pangu Light broadens the applicability of LLMs in resource-constrained environments, potentially influencing future research in AI hardware-software co-design.
Conclusion
Pangu Light represents a significant step forward in LLM optimization, offering a comprehensive framework that combines importance-driven pruning with innovative re-initialization techniques. This research not only enhances model efficiency but also paves the way for wider adoption of LLMs by overcoming the challenges posed by large-scale architectures. Future developments could extend these methodologies to incorporate other model architectures and further explore the integration with quantization techniques to achieve even higher efficiency gains.
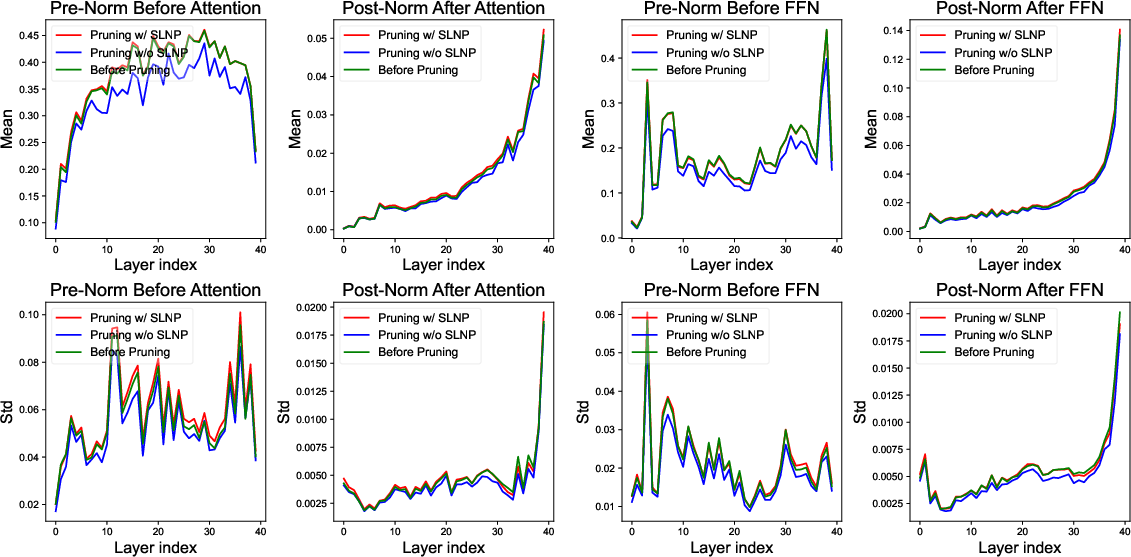
Figure 3: Distribution of the Sandwich-Norm's affine scale parameters γ before and after pruning, highlighting the stability of the method in preserving learned parameter characteristics post-pruning.