- The paper systematically evaluates five LLMs using various quantization methods, showing that 8-bit formats preserve accuracy while 4-bit methods often lead to significant performance degradation.
- The study finds that quantization effects are highly model- and task-dependent, with Llama-3.1 models notably more sensitive than Qwen-2.5 and non-English languages suffering greater loss.
- Results highlight that increased context lengths exacerbate degradation, underscoring the need for context- and language-aware quantization calibration for robust LLM deployment.
Quantization Impact on Long-Context Tasks in LLMs
Motivation and Contributions
Recent advances in LLMs have enabled context windows exceeding 128K tokens, unlocking applications such as whole-book reasoning, codebase analysis, and full-document summarization. However, these capabilities incur significant memory and computational costs, impeding scalability and increasing inference latency. Quantization offers practical mitigation by reducing precision, yet its effects on LLM performance—especially in extreme long-context and multilingual settings—remain poorly understood. This work provides a systematic analysis by evaluating five models (Llama-3.1 8B/70B and Qwen-2.5 7B/32B/72B) across five quantization methods (FP8, GPTQ-int8/4, AWQ-int4, BNB-nf4), covering tasks with both long inputs (≥64K tokens) and long-form outputs, spanning 9.7K examples. The study establishes clear accuracy-memory tradeoffs and uncovers substantial context- and language-specific effects.
Experimental Design
Models—spanning Llama-3.1 and Qwen-2.5 families—were evaluated at BF16 baseline and quantized variants (4-bit and 8-bit formats) using widely adopted tooling and recipes. Inference was performed deterministically on A100/H100 GPUs via vLLM. Five benchmarks were employed:
- Ruler: NIAH retrieval in English (needle-in-a-haystack, multi-key, multi-value retrieval) at 8K/64K/128K context lengths.
- OneRuler: NIAH and NIAH-none across 26 languages, up to 128K context, including no-needle abstention scenarios.
- NoCha: Reasoning over book-length contexts (up to 128K tokens), requiring paired true/false claim verification.
- FActScore: Factuality in biography generation, measured by VeriScore with abstention penalized.
- CS4: Constrained story generation, increasing constraint levels (9/23/39) for comprehensive instruction-following assessment.
Each quantization recipe—FP8, GPTQ-int8/4, AWQ-int4, BNB-nf4—was sourced from popular repositories (HuggingQuants, Qwen, RedHat AI, vLLM) or produced via standard procedures. Task evaluation metrics included exact match, constraint satisfaction rates, narrative coherence (BooookScore), and factuality coverage.
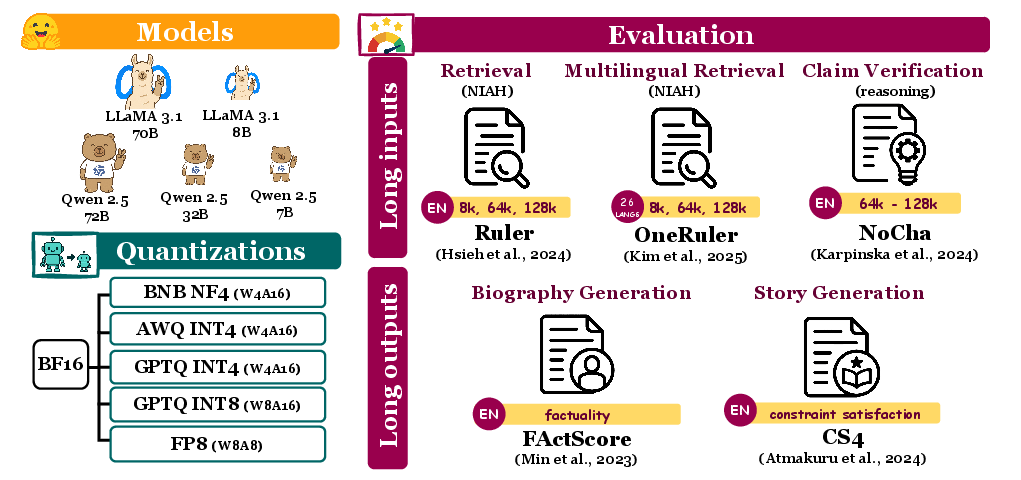
Figure 1: Evaluation pipeline overview: models, quantization, and long-context/long-form task composition.
Key Findings
Quantization Robustness
8-bit quantization (FP8, GPTQ-int8) demonstrates robust preservation of accuracy, with average performance drops of only 0.2–0.8% versus BF16; losses are statistically insignificant across most tasks. In contrast, 4-bit quantization methods (AWQ-int4, GPTQ-int4, BNB-nf4) incur larger degradations: AWQ-int4 (1.8%), GPTQ-int4 (2.7%), BNB-nf4 (6.9%). BNB-nf4 in particular exposes drastic task-specific losses—up to 59% drop for Llama-3.1 70B on OneRuler.
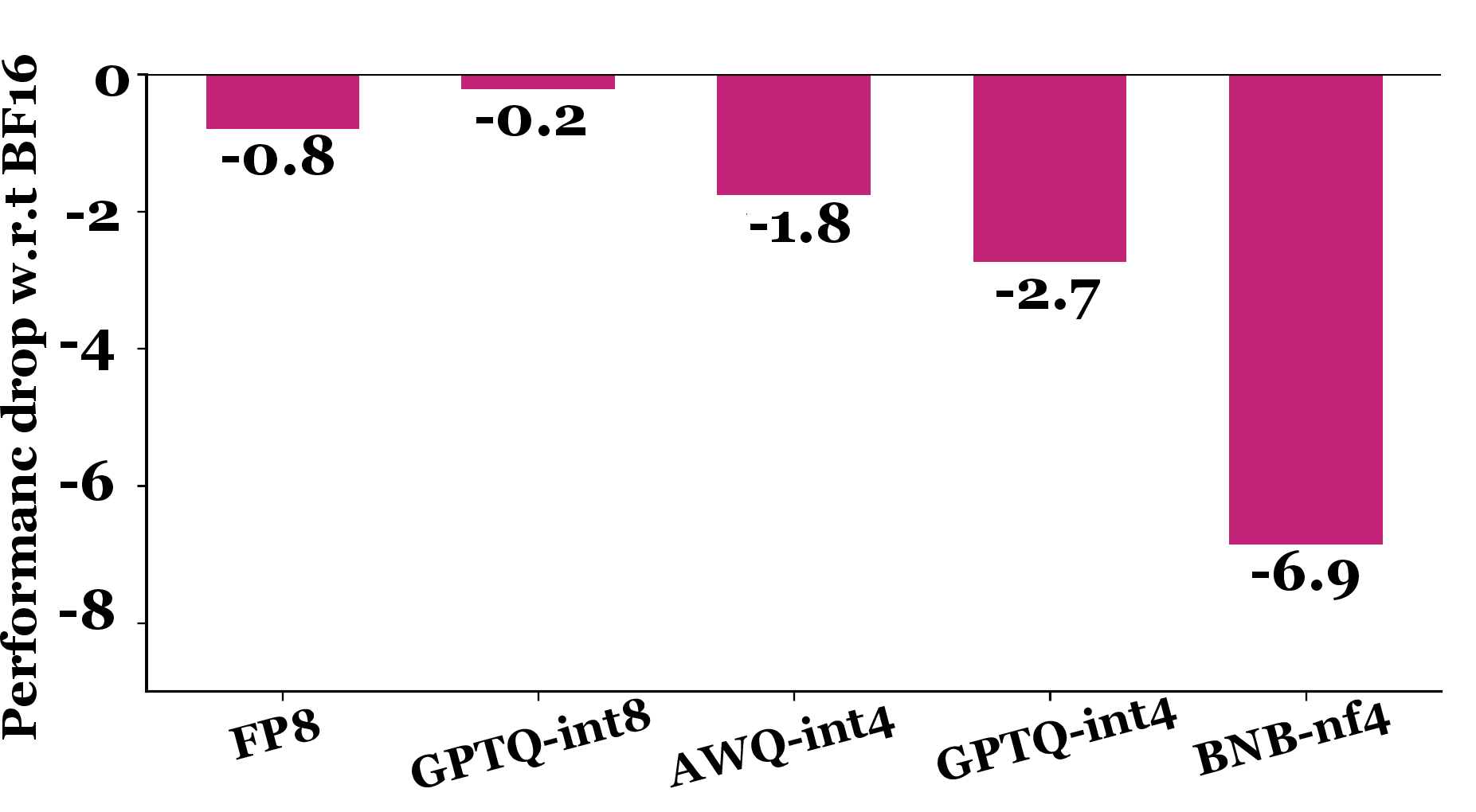
Figure 2: Average performance drop (percentage points) caused by quantization on long-context tasks relative to BF16 baseline.
Task and Model Dependency
Quantization effects are highly model- and task-dependent. While Qwen-2.5 72B remains robust under BNB-nf4, Llama-3.1 70B suffers substantial loss (>32% on long-context retrieval). Statistical analysis confirms that the variance in quantization sensitivity is pronounced even among similarly sized models and between task types (retrieval, reasoning, generation, instruction-following).
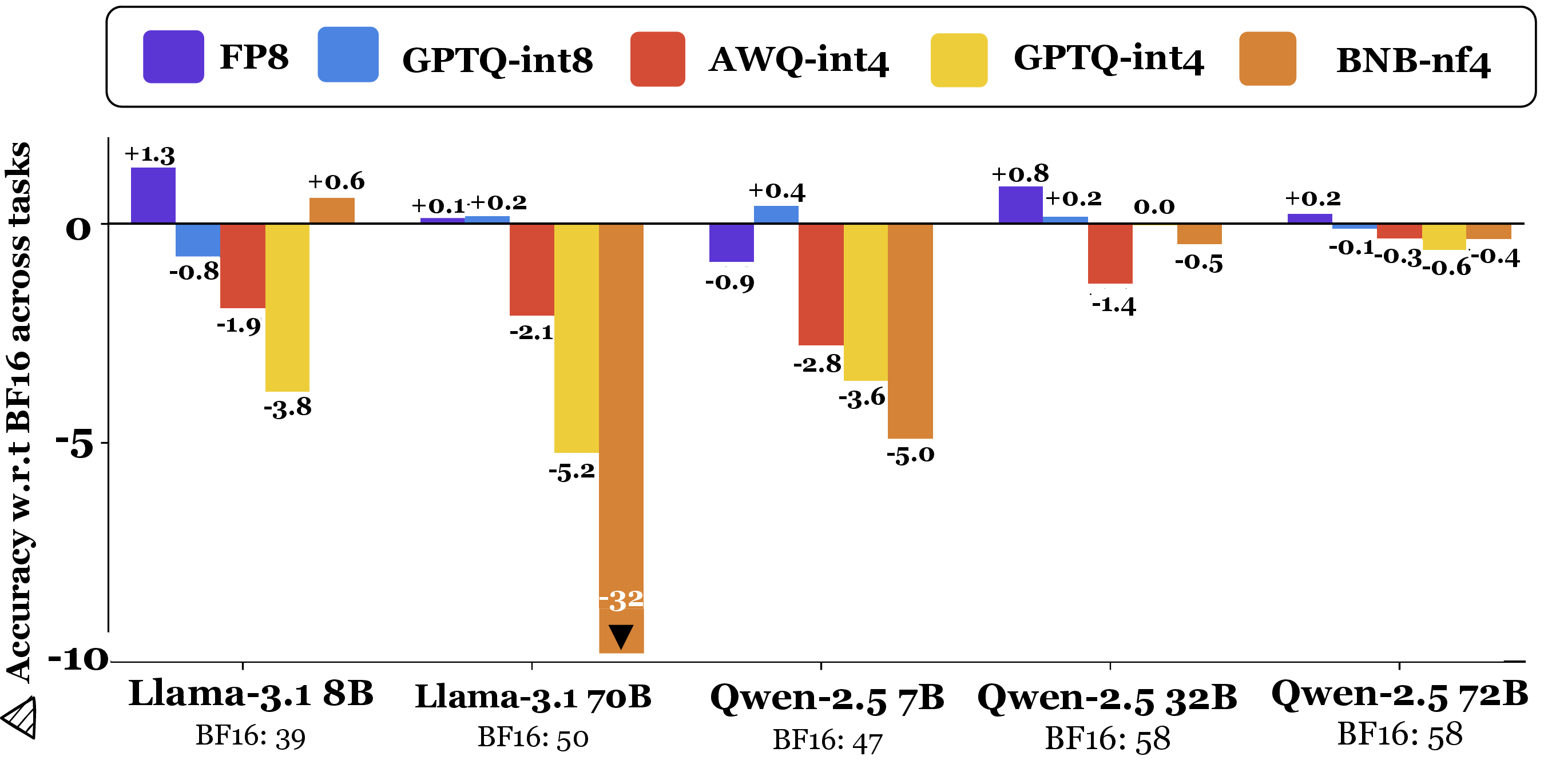
Figure 3: Model-wise performance across quantization methods, aggregated over all tasks, showing sharp heterogeneity in degradation as a function of quantization and architecture.
Long-Context Sensitivity
Degradation worsens as input length increases. At higher context lengths (64K/128K), 4-bit quantization leads to relative drops up to 16–23% on retrieval tasks, with error accumulation likely exacerbated by RoPE embedding rounding errors. The effect is muted on tasks (e.g., NoCha) where BF16 already performs near chance, yet the trend remains.
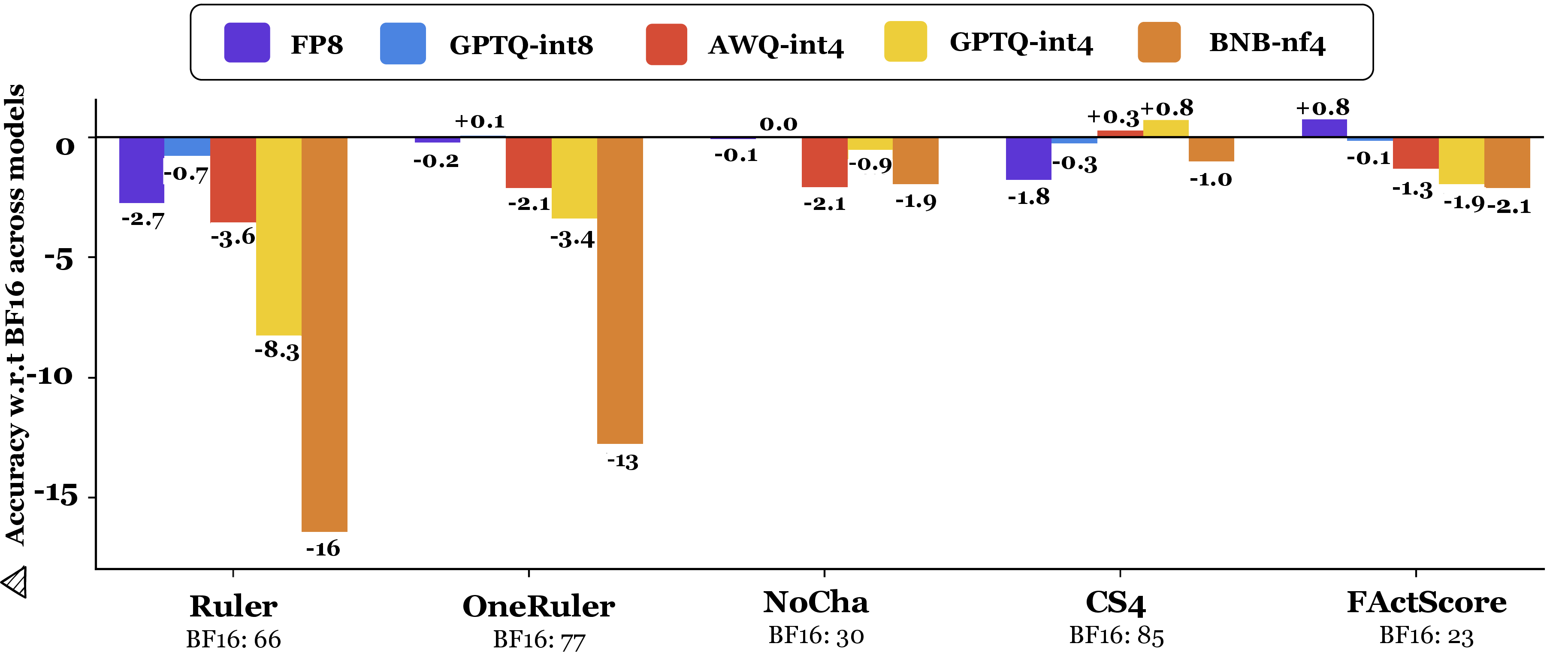
Figure 4: Performance degradation of quantization methods by task category; peak losses on long-context retrieval.
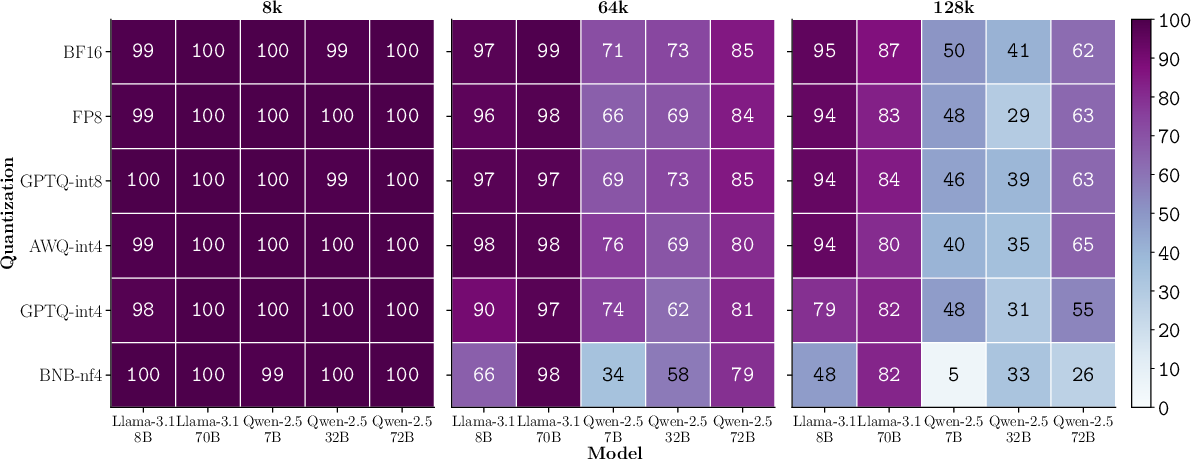
Figure 5: Needle task accuracy in Ruler, showing performance decline across context lengths and quantization methods.
Multilingual Degradation
Non-English languages in OneRuler exhibit up to 5× greater performance loss upon quantization compared to English. Low-resource and high-resource languages individually are highly susceptible, especially with 4-bit variants.
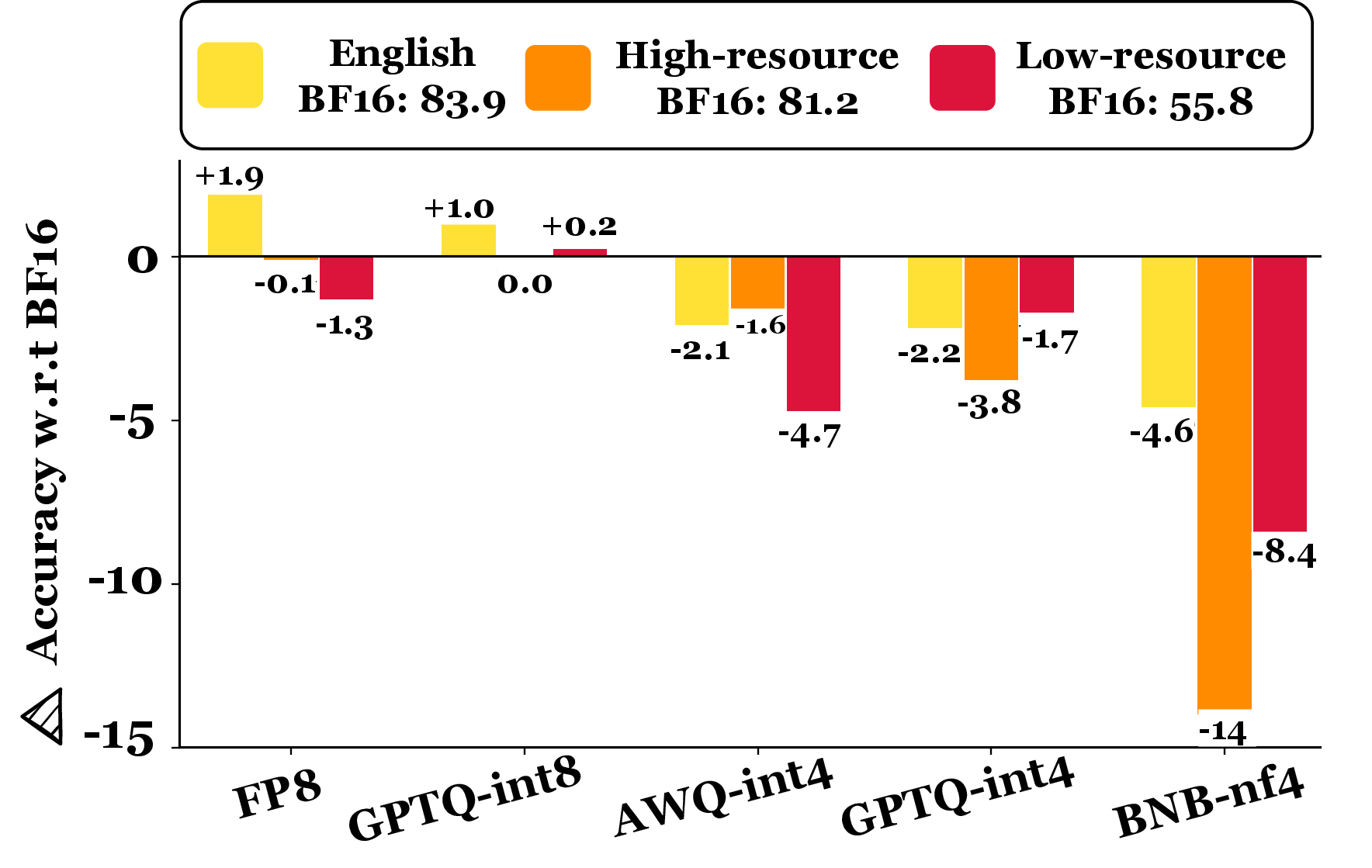
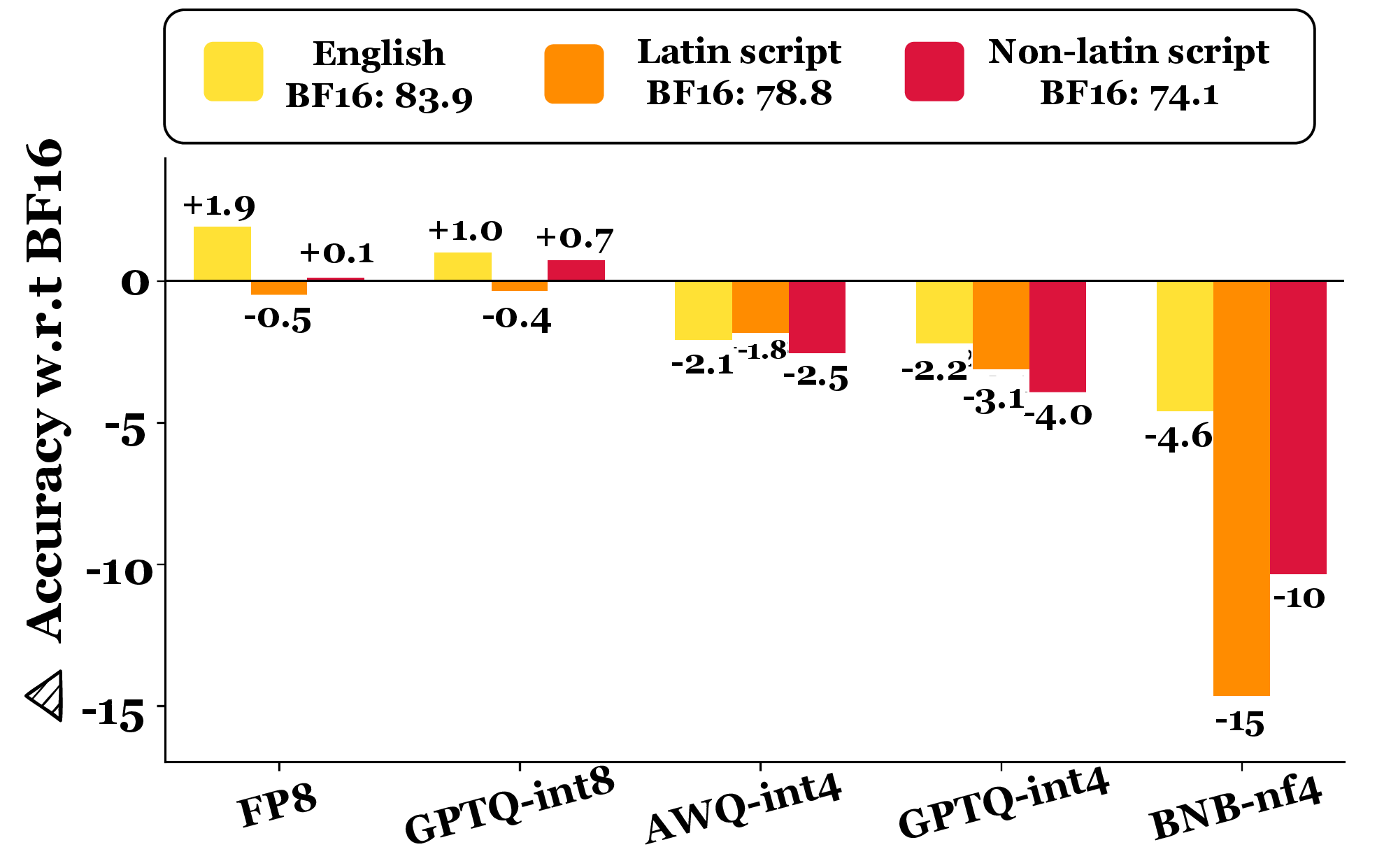
Figure 6: OneRuler—performance drop by language resource level under quantization.
For factual biography generation (FActScore), 8-bit quantization is nearly lossless. 4-bit quantization increases abstain rates (no verifiable claims) and induces modest factuality drops (up to 2.1%), particularly for frequent entities. For CS4 constrained story generation, FP8 and BNB-nf4 degrade constraint satisfaction as constraints increase, whereas AWQ-int4 and GPTQ variants largely preserve instruction-following.
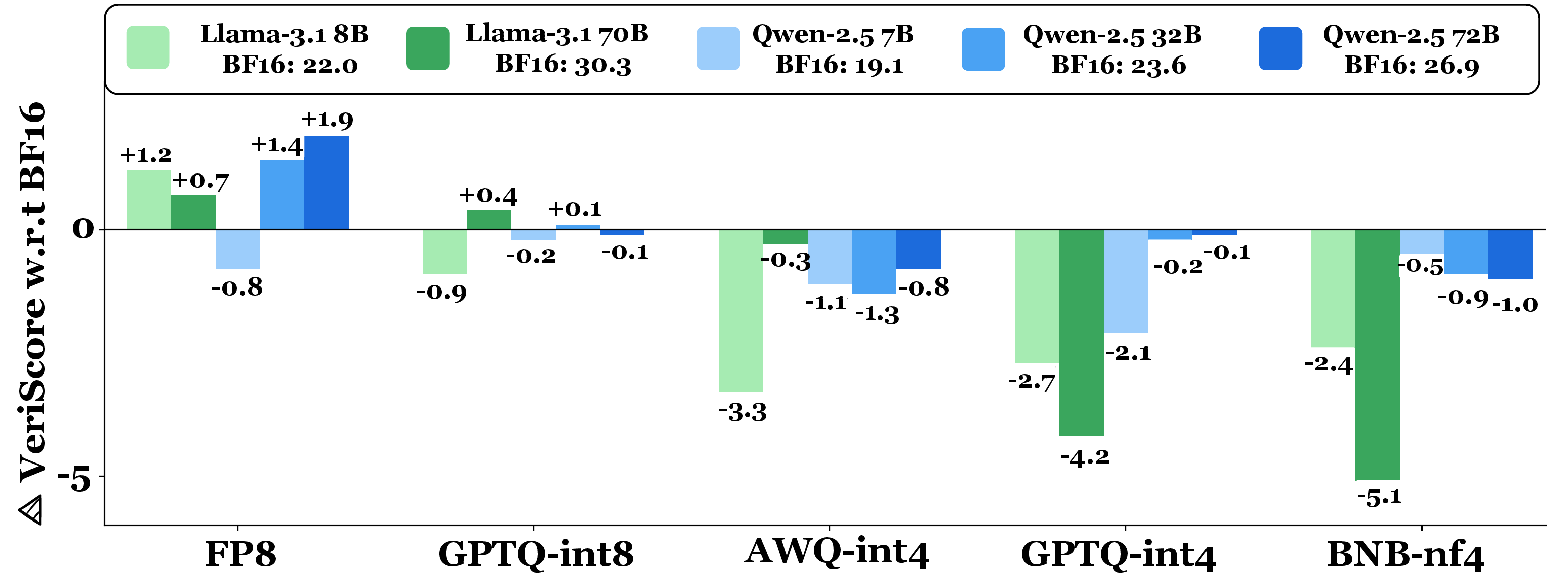
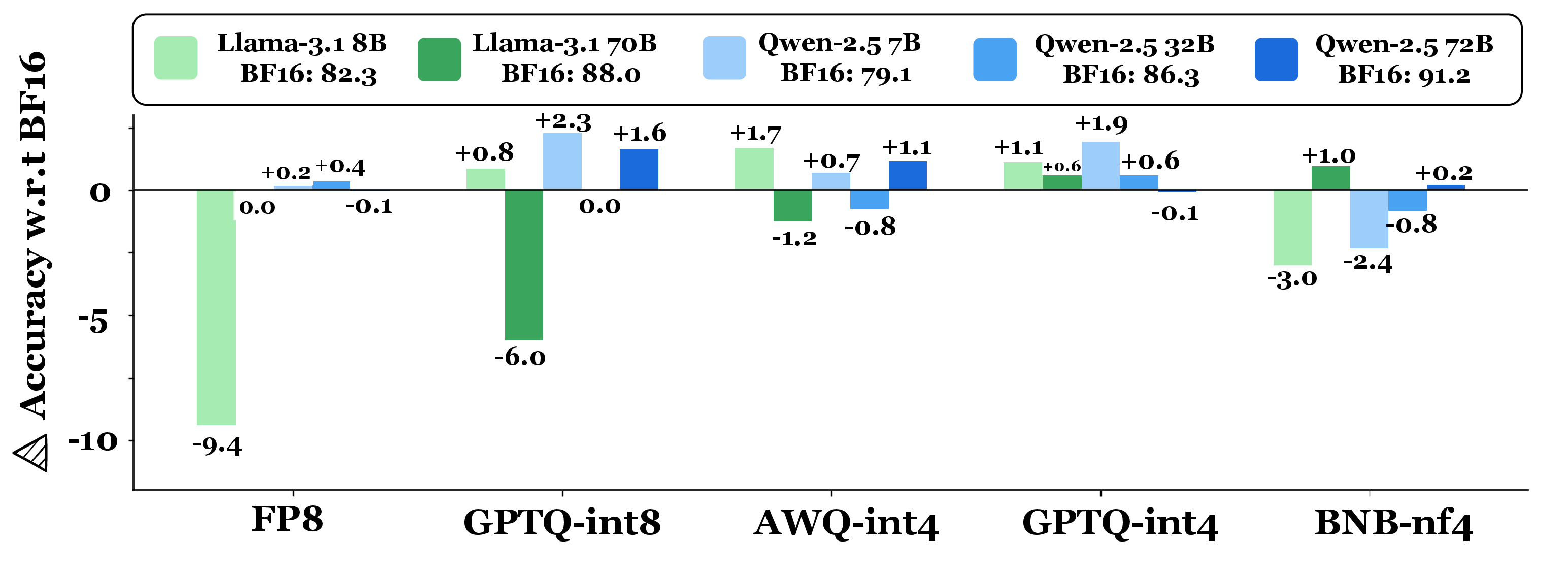
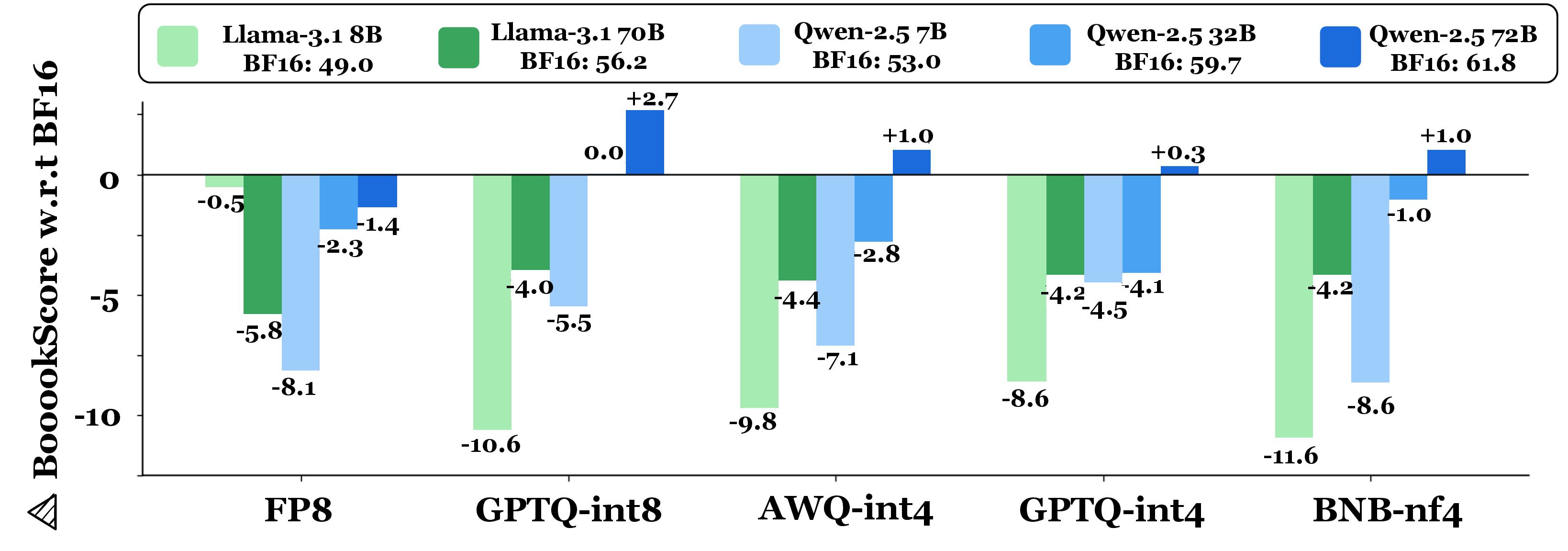
Figure 7: FActScore—average factuality Delta-VeriScore, indicating minimal loss for 8-bit quantization.
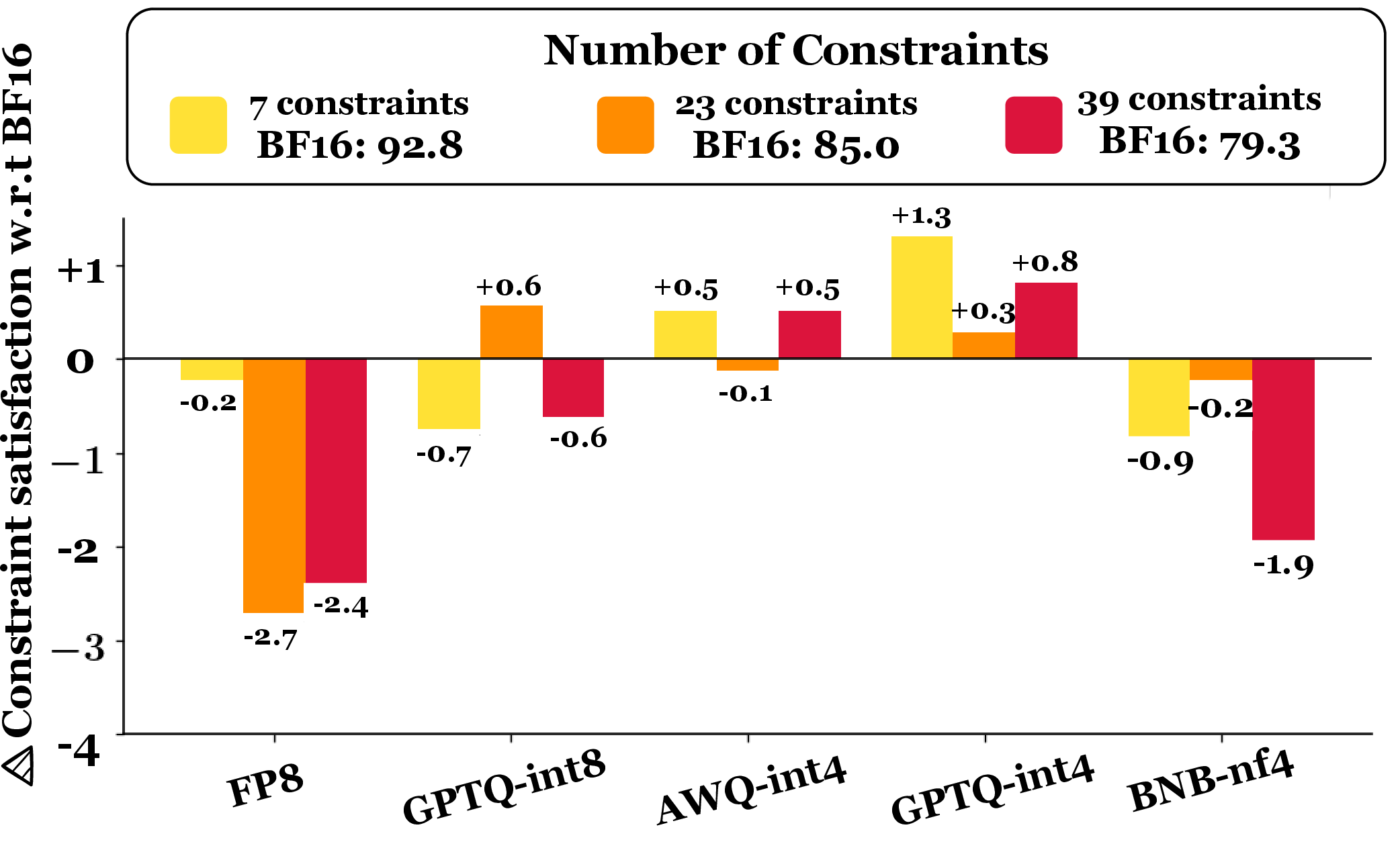
Figure 8: CS4 constraint satisfaction—quantization-induced drop as input constraints increase.
Contradictory and Bold Claims
- The popular BNB-nf4 quantization—widely used by default in libraries (HuggingFace, vLLM)—yields pronounced degradation, contradicting prior literature that reports only marginal accuracy loss for 4-bit quantization.
- Model architecture exerts greater influence over quantization robustness than previously assumed; Llama-3.1 is consistently more sensitive than Qwen-2.5, even at similar parameter scales.
- Task-level and context-length-specific breakdowns reveal meaningful performance loss masked in aggregate scores; coarse averages are insufficient for deployment risk assessment.
Numerical and Statistical Highlights
- 8-bit quantization: <1% average loss, statistically indistinguishable from BF16 (p>0.05).
- 4-bit quantization: up to 59% loss (BNB-nf4 on Llama-3.1 70B); average 6.9% drop.
- Multilingual context: up to 8.4% drop for low-resource languages (BNB-nf4).
- Long-context retrieval: 16–23% accuracy reduction at 128K tokens (4-bit quantization methods).
Implications and Future Directions
Practically, quantization for memory/concurrency efficiency must be employed judiciously in applications requiring extreme context lengths, high language diversity, or secure factuality. Popular 4-bit formats in production pipelines pose deployment risks unless validated per model/task configuration. Attention calibration strategies, context-aware quantization calibration, and embedding error mitigation (e.g., RoPE scaling) warrant further study.
Theoretically, results challenge established scaling laws regarding precision, underscoring the interplay between context length, positional encoding, quantization format, and architecture-specific characteristics. Evaluations must extend beyond standard short-form benchmarks, utilizing fine-grained breakdowns across input length, language, and task constraints. Further research into precision-position interaction and adaptive quantization protocols is needed to realize robust resource-efficient LLM deployment.
Conclusion
Systematic analysis reveals that while 8-bit quantization is consistently robust for long-context and long-form tasks, 4-bit quantization induces substantial performance degradation, particularly as context length grows and when operating in multilingual settings. Task-specific and architecture-driven heterogeneity mandates comprehensive evaluation before practical deployment; aggregate scores are insufficient for operational assurance. The study indicates the necessity for context- and language-aware quantization selection, calibration, and possible architectural adaptation in future LLMs.
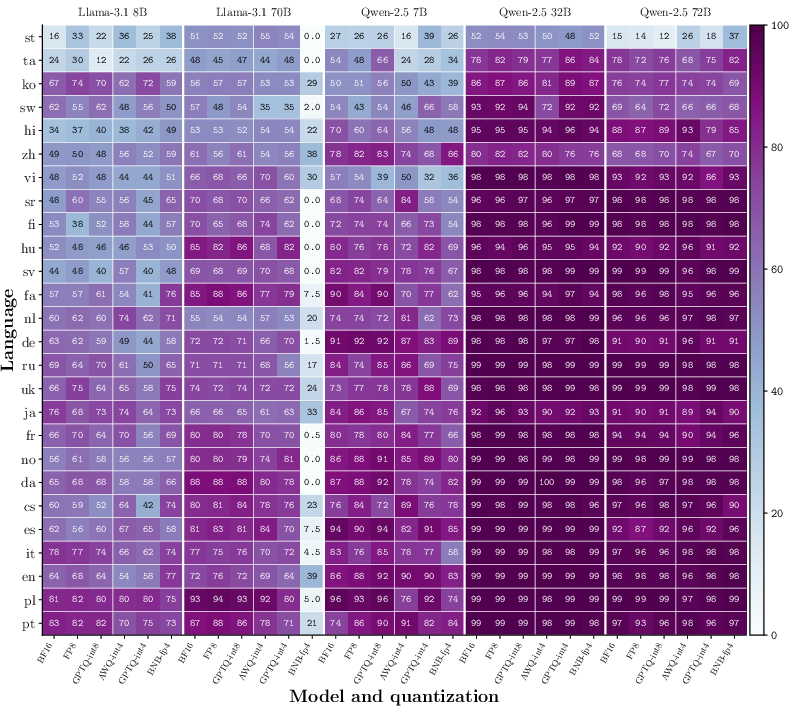
Figure 9: OneRuler—language-wise long-context accuracy, illustrating heterogeneous quantization effects across languages and models.