- The paper introduces Ra-DPO, a method integrating nested risk measures for token-level optimization to improve LLM alignment and reduce model drift.
- It employs a risk-aware advantage function and token-level Bellman equations to refine preference-based policy optimization within large language models.
- Experimental results on datasets like IMDb show Ra-DPO’s superior performance over traditional methods, with improved reward accuracy and reduced sequential KL divergence.
Risk-aware Direct Preference Optimization under Nested Risk Measure
Introduction
The paper introduces Risk-aware Direct Preference Optimization (Ra-DPO), a novel approach designed to enhance LLMs by incorporating nested risk measures for more sensitive alignment with human preferences. The Ra-DPO technique addresses the inadequacies observed in conventional KL divergence constraints prevalent in LLM optimization processes, especially in applications demanding stringent risk management.
Methodology
Risk-aware Objective Function
Ra-DPO formulates a risk-aware advantage function that integrates nested risk measures into token-level generation, ensuring finer granularity and control. The method analyzes the characteristics of nested risk measures, transforming the risk-sensitive optimization problem into a sequence conducive to policy improvements.
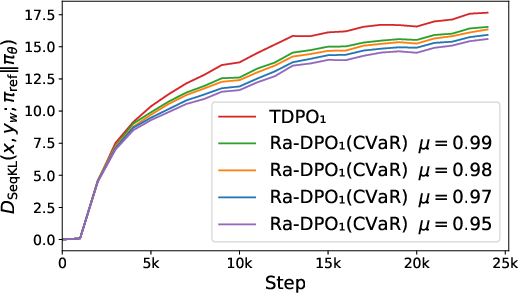
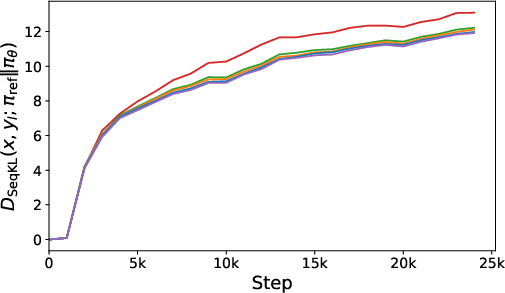
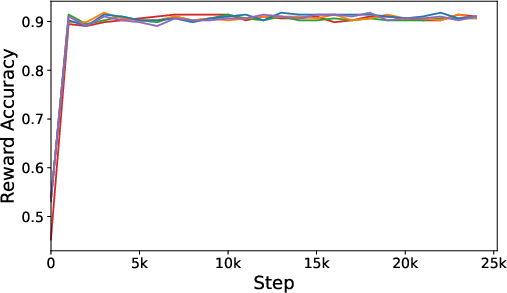
Figure 1: The experiment on the IMDb dataset with GPT-2 Large serving as the base model. (a) and (b) present the progression of sequential KL divergence (the lower the better) for both preferred and dispreferred responses. (c) illustrates the reward accuracy curves (the higher the better).
Preference-based Policy Optimization
The study positions Ra-DPO within the larger framework of Preference-based Markov Decision Processes (Pb-MDP), employing a token-level Bellman equation for enhanced sequential modeling. The risk-aware advantage function is rigorously defined, factoring in a risk control parameter μ, aligning with CVaR and ERM risk functions for broad application coverage.
Optimization Objective
The paper derives the mapping from the risk-aware state-action functions to optimal policies, emphasizing the Bradley-Terry model's equivalence with Regret Preference Models. This allows Ra-DPO to establish categorical alignment probabilities reflecting human preference data effectively.
Experiments
Setup
Ra-DPO was experimentally evaluated using open-source datasets such as IMDb, Anthropic HH, and AlpacaEval, coupled with models like GPT-2 Large and Pythia series, under varied risk measure configurations.
Results
The experimental results showcase Ra-DPO’s superior performance compared to traditional methods like DPO and PPO, demonstrating reduced model drift and improved reward accuracy. Figures illustrate the method’s advantage in sequential KL divergence optimization, vital for stable and consistent LLM alignment.

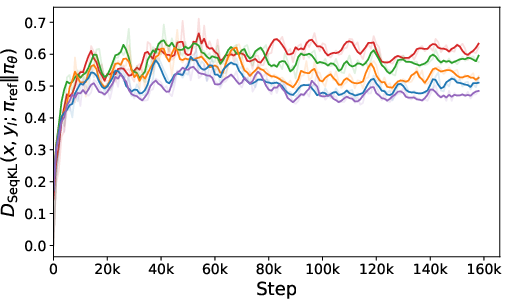


Figure 2: The experiment on the Anthropic HH dataset with Pythia-1.4B serving as the base model. Left and Middle present the progression of sequential KL divergence (the lower the better) for both preferred and dispreferred responses. Right illustrates reward accuracy curves (the higher the better).
Conclusion
Ra-DPO introduces a structured approach to minimizing risks in LLM alignment by leveraging nested risk measures in token-level optimization. It provides theoretical validation for policy improvement steps and empirically proves its applicability across diverse language generation scenarios.
This work suggests potential future developments in risk-sensitive LLM optimization, emphasizing continuous improvement in LLM alignment with human preferences while ensuring robust risk management. The framework and methodology proposed offer substantial contributions to the domain, especially in applications requiring nuanced decision-making and precise alignment criteria.