- The paper introduces AutoCDSR, a plug-and-play module that minimizes negative transfer by dynamically regulating cross-domain self-attention.
- It employs a Pareto-optimal approach using MGDA and Frank-Wolfe optimization to balance recommendation loss and cross-domain attention regularization.
- Results show significant gains in Recall@10 and NDCG@10 with minimal computational overhead, enabling robust integration into transformer-based systems.
Revisiting Self-attention for Cross-domain Sequential Recommendation
Introduction and Motivation
This paper addresses the challenge of cross-domain sequential recommendation (CDSR), where user behavior sequences span multiple domains (e.g., products, videos, social interactions). The core difficulty in CDSR arises from two factors: (1) context length explosion due to concatenation of multi-domain behaviors, and (2) negative transfer, where cross-domain signals introduce noise and degrade performance. While prior works mitigate these issues by adding domain-specific modules or reweighting strategies, this paper posits that the self-attention mechanism in transformers is inherently capable of learning fine-grained correlations among heterogeneous behaviors, provided it is properly optimized.
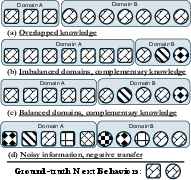
Figure 1: Cross-domain sequences exhibit asymmetric domain distributions and noise, precluding a universal static learning pattern for knowledge transfer.
Quantifying Cross-domain Knowledge Transfer
The authors empirically demonstrate that naive cross-domain sequence modeling with vanilla self-attention can sometimes improve CDSR performance, but often suffers from negative transfer. By analyzing attention scores in BERT4Rec trained on cross-domain sequences, they show that excessive cross-domain attention correlates with prediction errors when single-domain information suffices.
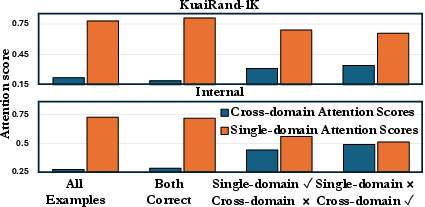
Figure 2: Excessive cross-domain attention in BERT4Rec leads to negative transfer when single-domain knowledge is sufficient.
To formalize this, the paper introduces a metric acd, quantifying the sum of attention scores between items from different domains. This metric serves as a proxy for cross-domain knowledge transfer, revealing that self-attention can facilitate positive transfer when beneficial, but fails to suppress harmful interactions.
AutoCDSR: Pareto-optimal Self-attention for CDSR
The central contribution is AutoCDSR, a plug-and-play module for transformer-based recommenders that automates cross-domain knowledge transfer by dynamically regulating cross-domain attention. The approach frames CDSR as a multi-objective optimization problem, reconciling two losses:
- Lrec: Standard recommendation loss (e.g., masked token prediction).
- Lcd−attn: Auxiliary loss minimizing cross-domain attention scores.
Rather than statically weighting these losses, AutoCDSR employs a preference-aware Pareto-optimal solution, leveraging Multiple Gradient Descent Algorithm (MGDA) and Frank-Wolfe optimization to adaptively balance the two objectives per sequence. The preference vector is chosen to favor recommendation performance, increasing cross-domain attention only when it demonstrably improves predictions.
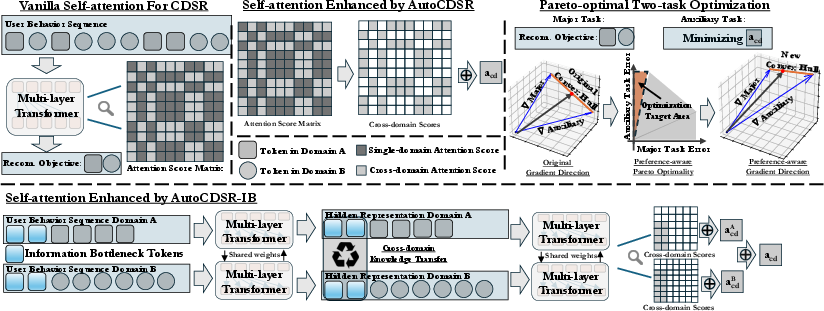
Figure 3: Systematic overview of AutoCDSR and AutoCDSR+, showing dynamic minimization of cross-domain attention and structured bottlenecking via IB tokens.
AutoCDSR+ extends AutoCDSR by injecting information bottleneck (IB) tokens into multi-domain sequences. These tokens act as controlled conduits for cross-domain communication, restricting information flow to Pareto-optimal bottlenecks. This design further reduces the risk of information dilution or conflict, at the cost of slightly increased computational overhead and sensitivity to domain labeling accuracy.
Experimental Results
Extensive experiments on Amazon Reviews, KuaiRand-1K, and a large-scale industrial dataset validate the efficacy of AutoCDSR and AutoCDSR+. Key findings include:
- Performance: AutoCDSR improves Recall@10 for SASRec and BERT4Rec by 9.8% and 16.0%, and NDCG@10 by 12.0% and 16.7%, respectively. In many cases, simple models enhanced with AutoCDSR match or surpass state-of-the-art CDSR methods.
- Efficiency: AutoCDSR introduces minimal computational overhead (∼9% for BERT4Rec), and is ∼4× faster than leading CDSR models with additional domain-specific modules.
- Robustness: AutoCDSR is robust to domain label noise, whereas AutoCDSR+ is more sensitive due to its reliance on accurate domain partitioning.
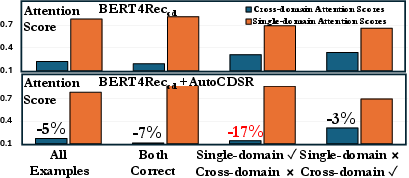
Figure 4: AutoCDSR significantly reduces cross-domain attention scores for samples suffering from negative transfer.
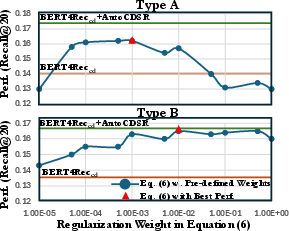
Figure 5: Base transformers are highly sensitive to static attention loss weights; no single optimal value exists across domains.
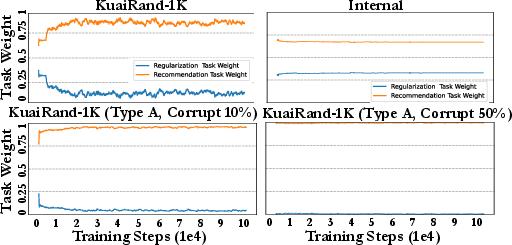
Figure 6: AutoCDSR dynamically adjusts task weights, reducing attention regularization as domain corruption increases.
Analysis and Implementation Considerations
AutoCDSR is straightforward to implement atop existing transformer-based recommenders. The key steps are:
- Attention Score Extraction: Compute cross-domain attention scores acd at each training step.
- Multi-objective Optimization: Use MGDA and Frank-Wolfe to derive Pareto-optimal gradients, prioritizing recommendation loss while adaptively minimizing acd.
- Plug-and-play Integration: No architectural changes are required; AutoCDSR operates as an auxiliary loss and optimizer wrapper.
For AutoCDSR+, additional preprocessing is needed to inject IB tokens and mask attention matrices according to domain boundaries. The combination function for IB token aggregation can be element-wise summation or more advanced strategies.
Trade-offs:
- AutoCDSR is lightweight and robust, suitable for production deployment where domain labels may be noisy.
- AutoCDSR+ offers more structured transfer but requires accurate domain information and incurs higher computational cost.
Scaling:
- Both methods scale linearly with sequence length and number of domains, as attention score extraction and Pareto optimization are efficient.
- For large-scale industrial systems, embedding table parameters can be excluded from Pareto optimization to further reduce overhead.
Theoretical and Practical Implications
The paper demonstrates that self-attention, when properly regularized, is sufficient to automate cross-domain knowledge transfer in sequential recommendation. This challenges the prevailing paradigm of adding domain-specific modules, suggesting that architectural simplicity and dynamic optimization can yield comparable or superior results.
Practically, AutoCDSR enables rapid deployment of CDSR capabilities in existing transformer-based recommenders with minimal engineering effort and resource consumption. The Pareto-optimal framework generalizes to other multi-objective learning scenarios, offering a principled approach to balancing competing signals.
Theoretically, the work deepens understanding of negative transfer in multi-domain learning, highlighting the role of attention dynamics and adaptive regularization. Future research may explore more granular preference vectors, advanced bottlenecking strategies, and applications to multimodal or multi-task recommendation.
Conclusion
This paper introduces AutoCDSR and AutoCDSR+, two efficient, plug-and-play modules for transformer-based cross-domain sequential recommendation. By dynamically regulating cross-domain attention via Pareto-optimal multi-objective optimization, these methods mitigate negative transfer and encourage beneficial knowledge exchange, achieving state-of-the-art performance with lower computational cost. The findings advocate for leveraging and optimizing core self-attention mechanisms rather than proliferating domain-specific modules, with broad implications for scalable, adaptive recommendation systems.