- The paper introduces a skeleton-agnostic diffusion model using a UNet architecture that processes joints independently to generate diverse motion sequences.
- It employs spatial and temporal attention modules along with a cosine noise scheduler to enhance computational efficiency and reduce motion artifacts.
- Experimental results on the 100style and LAFAN1 datasets show lower FID scores and reduced foot sliding, indicating superior motion realism and trajectory control.
UniMoGen: Universal Motion Generation
UniMoGen introduces a skeleton-agnostic approach for generating diverse and realistic motion sequences using an auto-regressive diffusion framework. Built upon advancements in diffusion models, UniMoGen efficiently handles multiple skeleton types, ensuring broad applicability across various domains such as animation, gaming, and robotics.
Motivation and Background
Traditional motion generation models generally rely on fixed skeletal structures, which restrict their versatility and adaptability across diverse characters. Recent advancements in motion diffusion models, such as MDM and CAMDM, have improved controllability by leveraging past motion and trajectory inputs. Despite this progress, these methods often necessitate training for each specific skeleton, limiting generalization. AnyTop addresses skeleton agnosticism but incurs overhead by requiring padding for skeletons with fewer joints.
UniMoGen overcomes these constraints by utilizing a UNet-based architecture with attention modules designed to process joints independently. This setup eliminates the need for padding and enables efficient training across diverse skeletons.
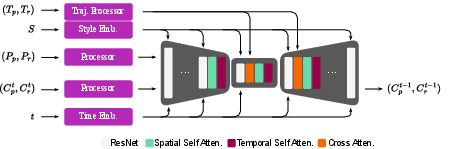
Figure 1: Overview of the UniMoGen denoising architecture. During training, the model receives style index S, past motion inputs as root positions P_p and joint rotations P_r, trajectory (T_p, T_r), and diffusion time step t. Dedicated modules process each input, and their representations are fused in a UNet-based diffusion network. The network leverages temporal and joint-level self-attention, cross-attention to inject trajectory information, and Feature-wise Linear Modulation (FiLM).
Methodology
UniMoGen leverages a U-Net architecture for temporal downsampling and employs attention modules for joint dimensions, improving computational efficiency without limiting the model to specific skeletal configurations.
Diffusion Process
UniMoGen operates under a diffusion paradigm, where Gaussian noise is incrementally added to motion data, which is then denoised by the model. The inclusion of a style index and trajectory data alongside past frames enhances the model's ability to generate meaningful and stylistically accurate motion sequences.
Attention Mechanisms
The key innovation of UniMoGen is its dedicated attention modules for spatial (joint-level) and temporal dimensions, which facilitate precise information processing without conflating frame sequences.
Training Procedure
UniMoGen employs a cosine noise scheduler with a reduced denoising step count, optimizing computational demands while maintaining quality. Regularization techniques, including auxiliary losses and min-max normalization, further improve the generated motions' physical fidelity and diversity.
Experimental Evaluation
UniMoGen is evaluated on the 100style and LAFAN1 datasets, showcasing superior performance metrics such as Fréchet Inception Distance (FID) and foot penetration rates, outperforming state-of-the-art models like MDM, CAMDM, and AnyTop.
UniMoGen's results demonstrate lower FID scores and significantly reduced foot sliding distances compared to CAMDM. It exhibits better trajectory adherence and diversity, highlighting its potential for real-time applications.

Figure 2: Style blending with UniMoGen. Visualization of motions generated by blending two styles: Aeroplane and Arms Above Head.


Figure 3: Onion skinning visualization of UniMoGen and CAMDM results. The top and bottom figures compare motion outputs from UniMoGen and CAMDM, given the same past frames, style, and trajectory.
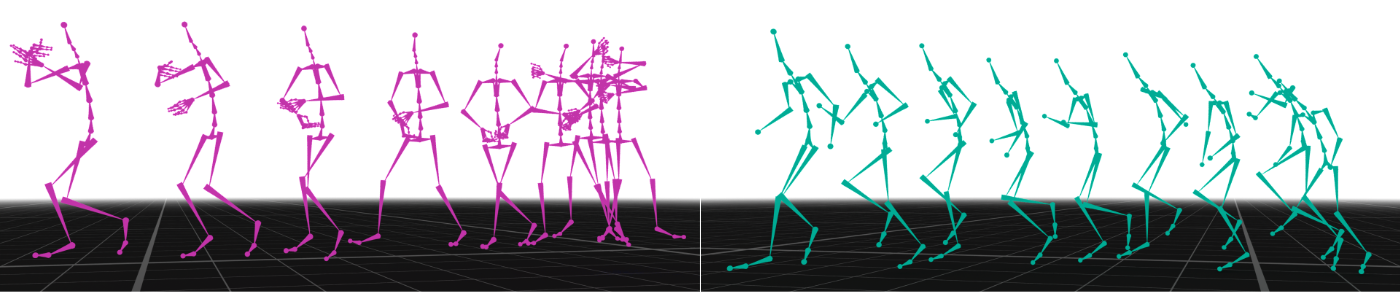
Figure 4: Multi-Skeleton Generation. Left: a motion generated for the skeleton of LAFAN1. Right: a motion generated for the skeleton of 100Style.
Conclusions and Future Directions
UniMoGen addresses critical challenges in motion generation by enabling skeleton-agnostic generation with high efficiency and controllability. Its design facilitates training on multiple skeletal types without computational overheads, distinguishing it significantly from prior models.
Future research could investigate integrating further conditioning signals and multi-modal inputs to expand UniMoGen's utility. Additionally, the exploration of more extensive datasets and real-world applications promises further enhancements in motion realism and interaction fidelity. UniMoGen sets a new benchmark in universal motion generation, paving the way for innovation in digital character animation and beyond.