- The paper presents a novel OS framework that elevates memory as a primary resource in LLMs.
- It introduces the MemCube, a unified abstraction enabling dynamic scheduling, version control, and adaptive memory evolution.
- MemOS enhances LLM performance through structured, cross-layer memory management that supports sustained knowledge evolution.
MemOS: An Operating System for Memory-Augmented Generation in LLMs
This paper introduces MemOS, a novel architectural framework designed to address deficiencies in the memory handling capabilities of LLMs. Traditional LLMs rely heavily on parametric memory embedded in model weights, which poses challenges in terms of interpretation, updating, and transferability. Despite the introduction of Retrieval-Augmented Generation (RAG) methods, existing frameworks lack robust lifecycle management, limiting their potential for sustained knowledge evolution. MemOS is proposed as a solution, elevating memory to a primary operational resource across three types: parametric, activation, and plaintext memory.
Background and Memory Challenges in LLMs
LLMs form a crucial component in advancing AGI but face significant challenges in memory capability. Current methods primarily focus on parametric memory, encapsulated within weights that require significant efforts for understanding or modification. Ephemeral activation memory operates during runtime states, but lacks persistence and continuity for long-term interactions. The RAG techniques utilize external knowledge sources but do not integrate comprehensive memory management mechanisms. MemOS aims to systematically manage memory as a first-class resource, enabling the transition from mere linguistic interaction to structured, adaptive, and intelligent systems.

Figure 1: Memory (Mem) in LLMs.
MemOS Design Philosophy and Core Concepts
MemOS is foundationally structured around the concept of treating memory as an integral component of LLM operation. The system introduces a controllable, evolvable infrastructure, leveraging the MemCube—an abstraction standardizing heterogeneous memory types, ensuring traceability, governance, and fusion capabilities. MemOS's framework reimagines LLM architecture with memory-centric execution paradigms, promoting continual adaptation and long-term reasoning.
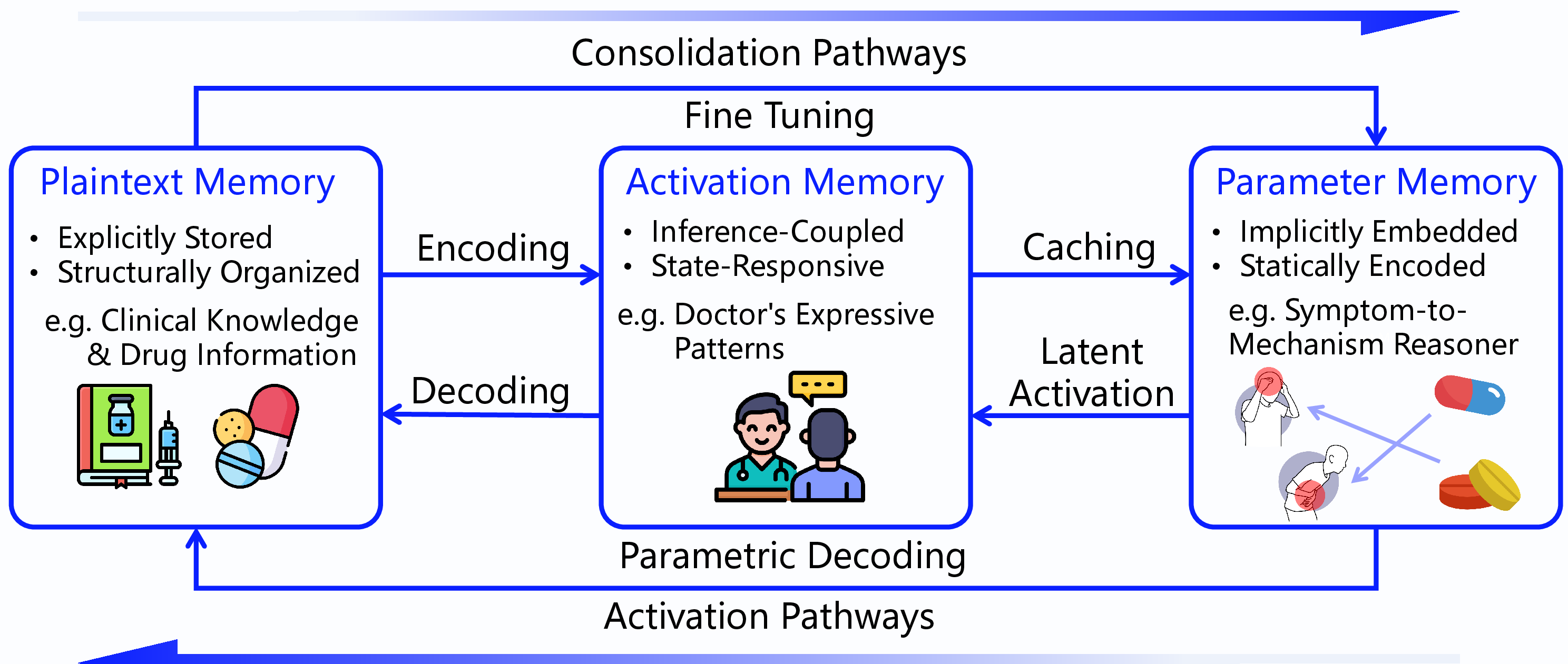
Figure 2: Transformation paths among three types of memory, forming a unified, controllable, and evolvable memory space.
MemCube: A Unified Memory Abstraction
The MemCube represents the smallest execution unit in MemOS, providing a unified abstraction for disparate memory types. It comprises a metadata header and a semantic payload, designed to support high-level operations like scheduling, version control, and transformation pathways among memory types. Descriptive metadata, governance attributes, and behavioral indicators ensure structured memory management, facilitating adaptive memory transformation and lifecycle governance.
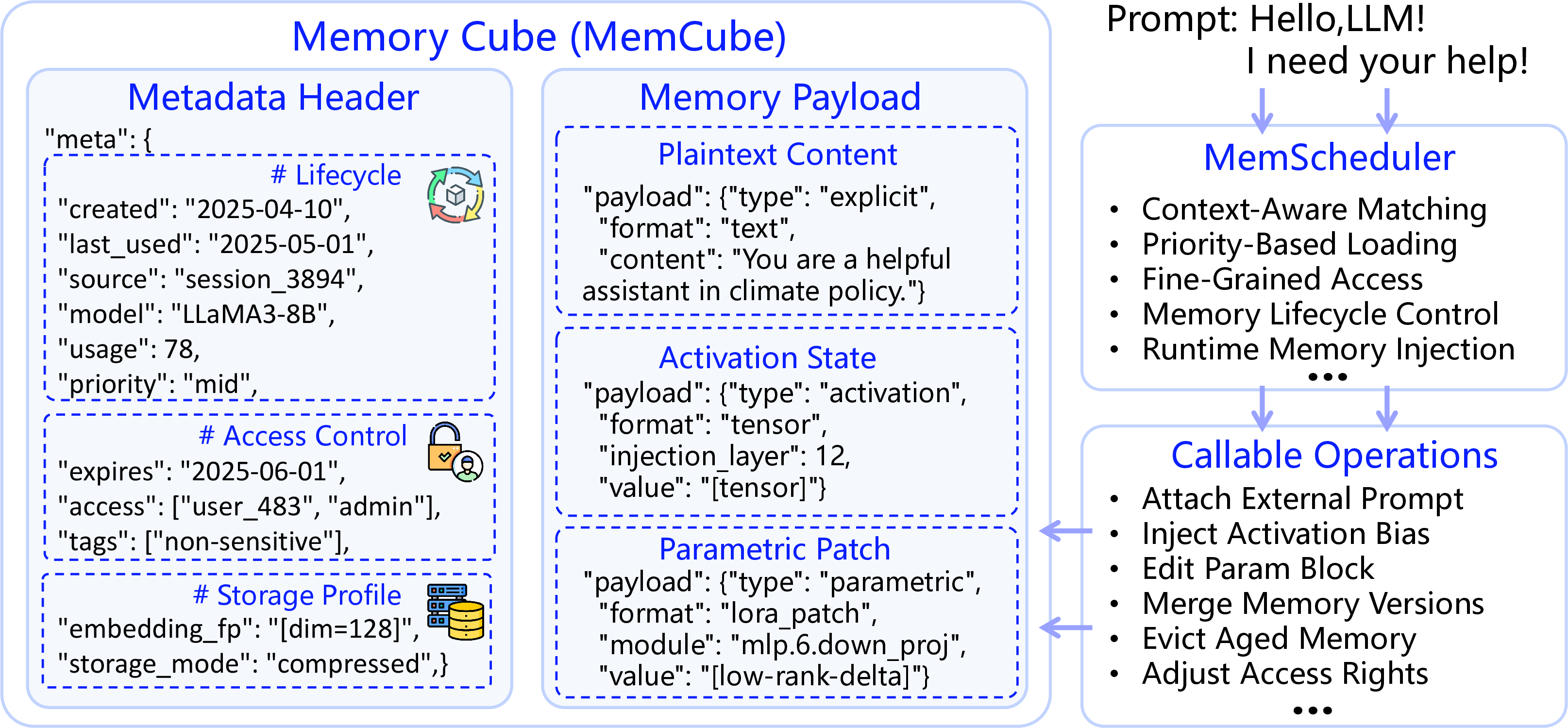
Figure 3: MemCube: a unified abstraction for heterogeneous memory, comprising a metadata header and semantic payload—serving as the smallest execution unit of memory in MemOS.
MemOS Architecture
MemOS employs a three-layer modular architecture comprising Interface, Operation, and Infrastructure layers, forming a robust closed-loop memory governance framework. The Interface Layer provides Memory APIs parsing and operation chain management. The Operation Layer orchestrates dynamic scheduling, lifecycle evolution, and semantic-structural memory organization. The Infrastructure Layer guarantees secure, accountable memory operations across multi-user environments through cohesive governance and cross-platform interoperability.
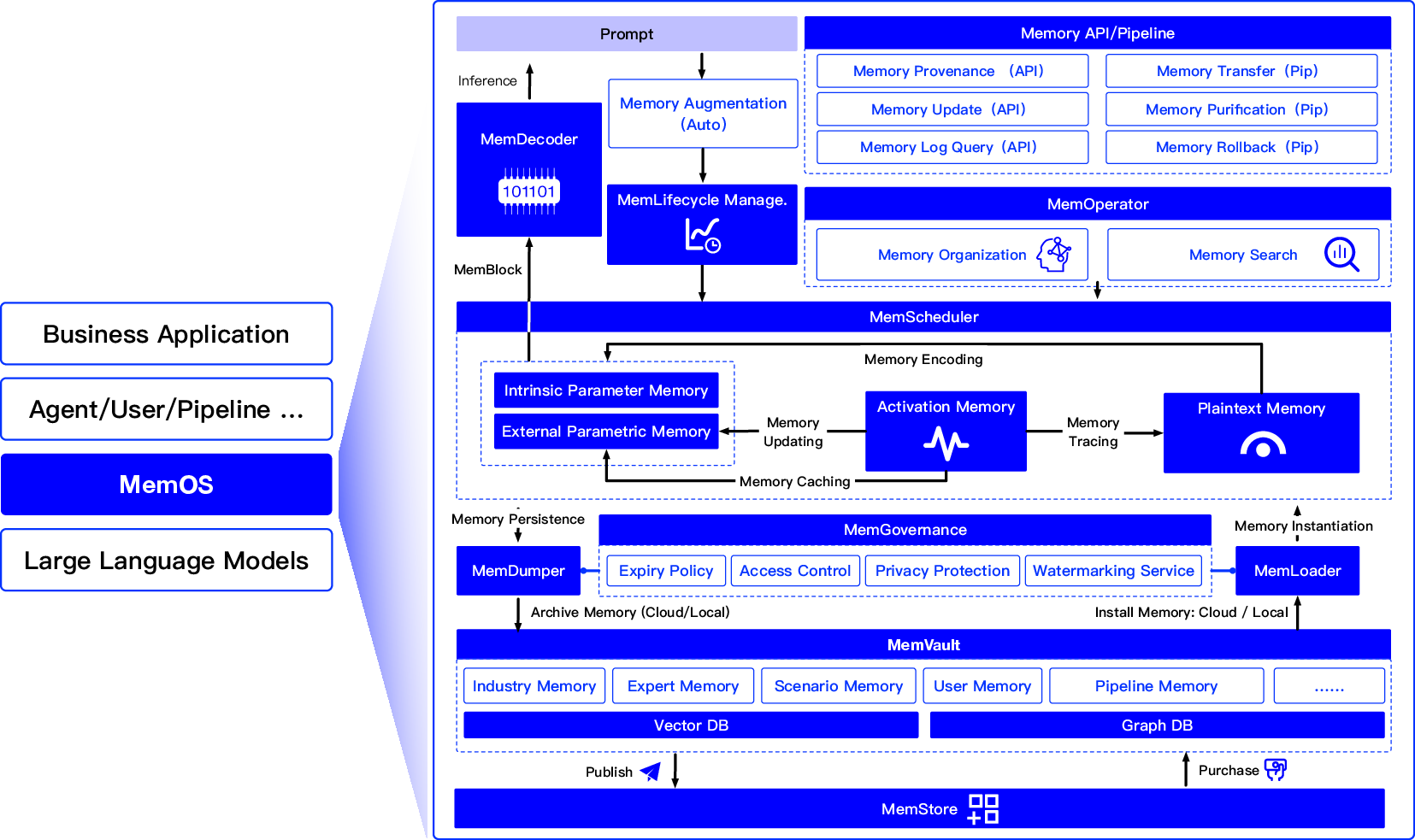
Figure 4: Overview of the MemOS architecture: showing the end-to-end memory lifecycle from user input to API parsing, scheduling, activation, governance, and evolution—unified via MemCube.
Practical Implications and Future Directions
MemOS addresses critical limitations in LLM architecture by promoting coherent reasoning, adaptability, and enhanced scalability. This paradigm shift transforms LLMs into intelligent agents capable of continuous evolution—supporting memory reuse, cross-task collaboration, and complex inter-agent intelligence.
Looking forward, MemOS could evolve towards decentralized memory marketplaces and self-evolving memory blocks, fostering sustainable AI ecosystems and enhancing agent personalizations.
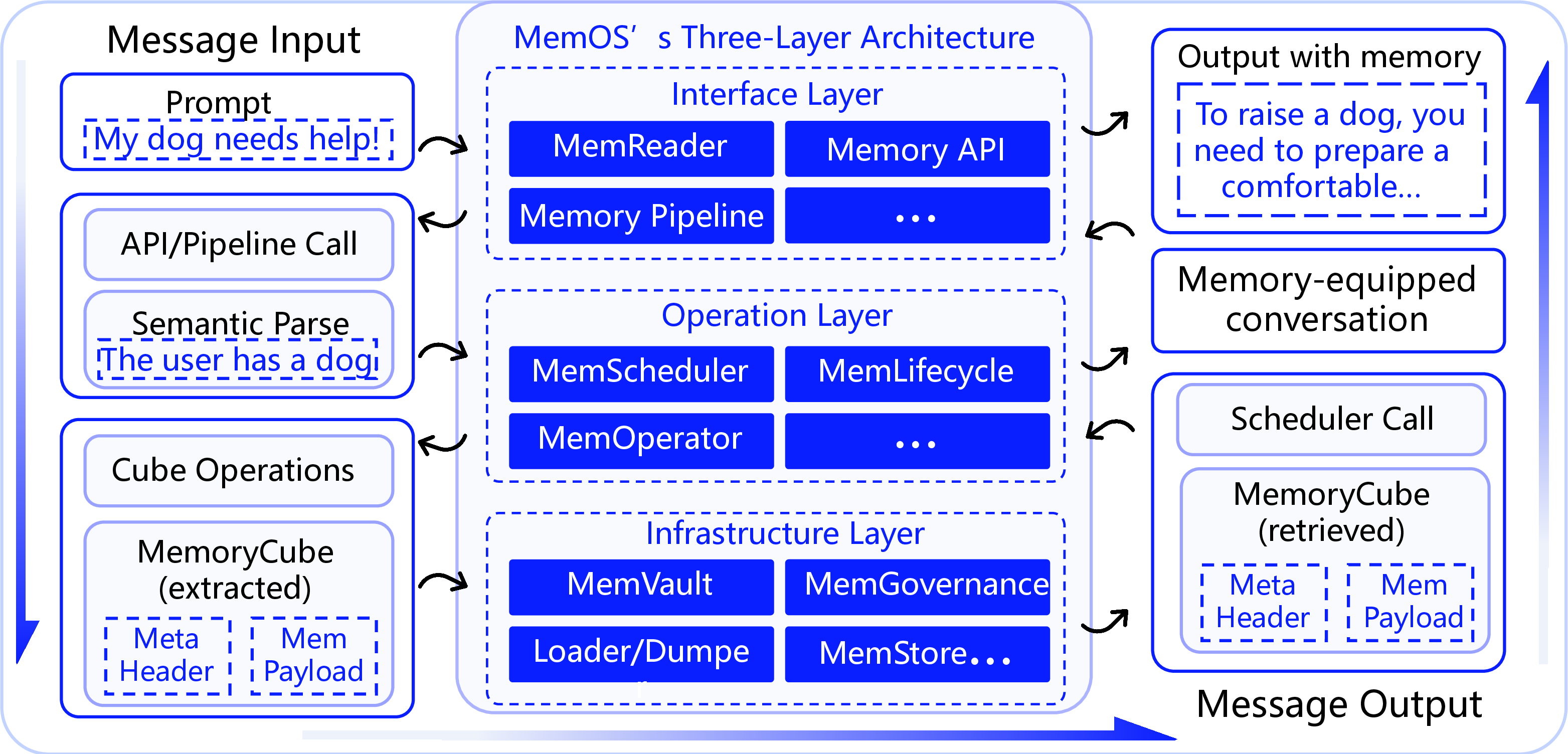
Figure 5: The three-layer architecture and memory I/O path of MemOS. From user input to scheduling and memory injection to response generation, each phase is executed via standardized MemoryCube structures that enable traceable and structured memory lifecycle management.
Conclusion
MemOS introduces a transformative approach to LLM memory management, revolutionizing how memory resources are treated within AI systems. By standardizing memory as a core operational asset, MemOS facilitates enhanced adaptability, structured evolution, and long-term reasoning in AI, paving the way for future advances in intelligent system design.
The adoption of MemOS could significantly advance LLM capabilities, enabling tailored, dynamic, and efficient AI solutions that are memory-centric and evolution-ready. This represents the next frontier in AI, promising to unlock new possibilities in collaborative intelligence and sustainable learning.
The paper lays the groundwork for LLMs to transition from static generation systems to dynamic intelligent agents, setting the stage for further research and development in memory-augmented AI frameworks.