- The paper introduces NeoDiff, which bridges discrete and continuous diffusion by employing a novel Poisson-based forward process and a dual time framework for fine-grained control.
- It leverages a bi-temporal approach with extrinsic and intrinsic times, along with a dynamic time predictor and Bayesian optimization, to enhance the contextual recovery of text.
- Evaluations show NeoDiff outperforms traditional models in NLP tasks like translation, paraphrasing, and text simplification, balancing improved quality with manageable complexity.
Unifying Continuous and Discrete Text Diffusion with Non-simultaneous Diffusion Processes
Introduction
The paper introduces a new diffusion model, NeoDiff, designed to improve text generation by integrating strengths from both discrete and continuous diffusion models. Discrete models independently apply categorical distributions to tokens, enabling variable diffusion progress but lacking in fine-grained control. Conversely, continuous models provide fine-grained noise control by operating in continuous spaces but apply uniform diffusion across tokens, limiting their contextual effectiveness. NeoDiff bridges these paradigms through a non-simultaneous continuous diffusion process, employing a novel Poisson-based noising strategy.
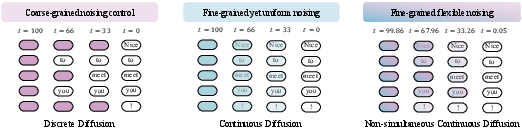
Figure 1: Comparison of the noising paradigms employed by Non-simultaneous Continuous Diffusion and two other diffusion models.
Unified Diffusion Framework
NeoDiff is built around a bi-temporal framework with extrinsic time t (global sentence progression) and intrinsic time τ (token-specific progression). This separation facilitates the introduction of independent, fine-grained control over diffusion, allowing for context-aware text generation.
NeoDiff introduces a Poisson process for the forward diffusion, supporting a variable, fine-grained token noise schedule. For the reverse process, a time predictor adaptable to token semantics modulates denoising, enhancing the contextual recovery of text.
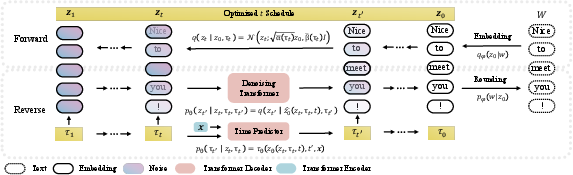
Figure 2: An overview of NeoDiff.
Implementation and Evaluation
A key component of NeoDiff is its time predictor, which dynamically estimates a token's intrinsic time τ. This predictor is trained using pseudo-labels derived from a combination of predicted text quality scores and rank-based transformations. The extrinsic time schedule is optimized post-training through Bayesian optimization, offering task-specific enhancements in generation quality.
NeoDiff demonstrates superior performance on multiple NLP tasks, including translation, paraphrasing, and text simplification, consistently outperforming non-autoregressive and autoregressive baselines. Its fine-grained control mechanism proves significantly effective in producing high-fidelity text generation results.
Improved Processes
The introduction of a Poisson-based forward process allows multi-token noising to capture more complex semantic structures. By integrating intrinsic time τ, NeoDiff can refine individual token noise while maintaining contextual coherence across the sentence.
The context-aware reverse process utilizes learned token-level noise distributions to better guide generation, leveraging information from less noisy tokens to refine more corrupted ones.
Trade-offs and Considerations
NeoDiff’s integration of discrete and continuous diffusion models improves text generation quality but introduces complexity, manifesting as increased model parameters due to the time predictor. Nevertheless, the computational overhead is offset by task-specific calibration achieved through the Bayesian optimization of the time schedule.
Inference speed and memory usage of NeoDiff remain competitive when juxtaposed with similar models, thanks to its efficient parallel decoding strategies and task-specific optimizations.
Conclusion
NeoDiff represents a significant advancement in diffusion-based text generation by effectively unifying discrete and continuous approaches. The model’s design, targeting fine-grained control at the token level, and the innovative Poisson-based forward process, equips it with superior capabilities across diverse text generation challenges, setting a new benchmark in the field.

