- The paper presents a novel single-page hard negative query generation approach that overcomes limitations of traditional document-level mining.
- It leverages a dual-stage pipeline using Pixtral-12B and Qwen models to generate and verify both positive and challenging unanswerable queries.
- The method demonstrates significant precision improvements in benchmarks like ViDoReV2 and Real-MM-RAG, with tailored applications in finance.
DocReRank: Single-Page Hard Negative Query Generation for Training Multi-Modal RAG Rerankers
The paper "DocReRank: Single-Page Hard Negative Query Generation for Training Multi-Modal RAG Rerankers" presents a novel approach to improving the efficacy of rerankers within the domain of Multi-Modal Retrieval-Augmented Generation (RAG). The focus is on a method for generating hard negative examples that refines the reranking process and enhances the retrieval quality of multimodal documents.
Introduction
The challenge in Retrieval-Augmented Generation frameworks lies in augmenting text with supplementary visual or structural elements while maintaining precision. First-stage retrieval models typically rely on embedding similarities that may falter in visually complex arenas. To address this, the study introduces a reranking strategy designed to optimize results beyond this initial retrieval.
Traditional methods for hard negative mining involve retrieving negative pages from the corpus, which tends to be passive, constrained by corpus content, and resource-heavy. This research reverses that process by initiating Single-Page Hard Negative Query Generation. Instead of focusing on negative pages, it produces queries that remain unanswerable based on current documents yet closely mimic positive iterations, thus broadening the difficulty and variety of training data.
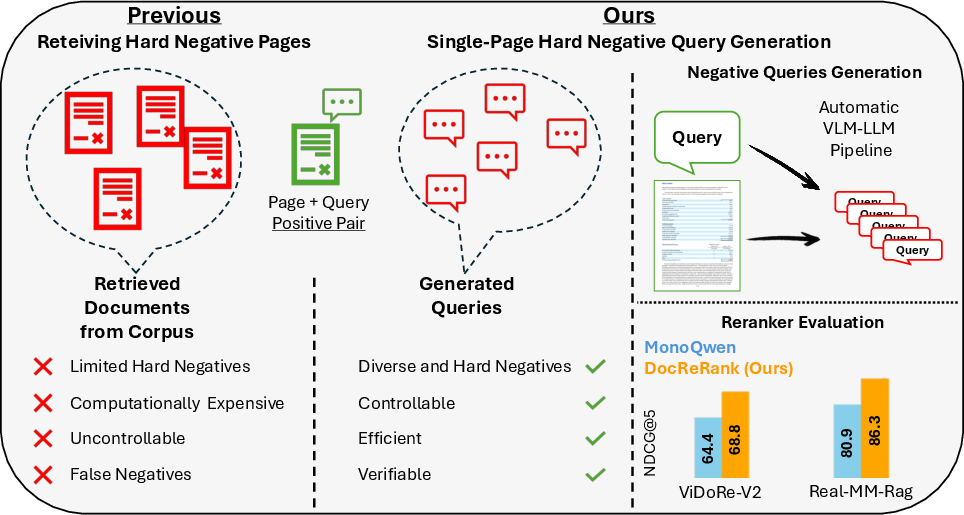
Figure 1: Proposed Single-Page Hard Negative Query Generation Approach.
Methodology
Query Generation Pipeline
- Positive Query Generation: Using Pixtral-12B VLM, the pipeline first generates candidate queries that may logically be derived from document content.
- Verification: Employing Qwen2.5-VL-7B-Instruct VLM, each query's potential to be directly answered by the document is tested, ensuring robustness through dual prompt strategies.

Figure 2: Query Verification Prompt.
- Hard Negative Query Generation: The approach uses Qwen2.5-7B-Instruct LLM to derive negative queries that maintain structural resemblance to positives but comprise unanswerable elements—culminating in a robust, controllable data set for reranking improvements.
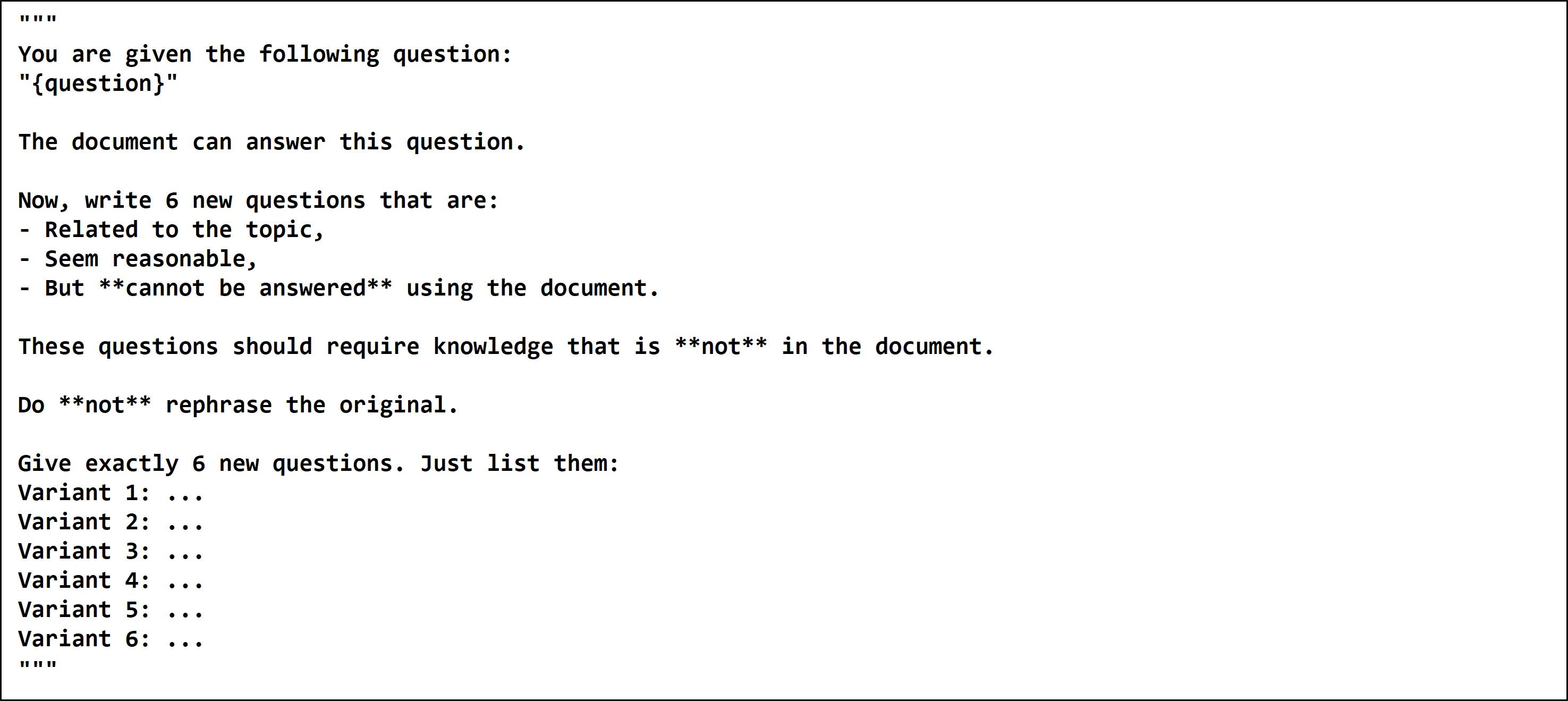
Figure 3: Negative Generation Prompt.
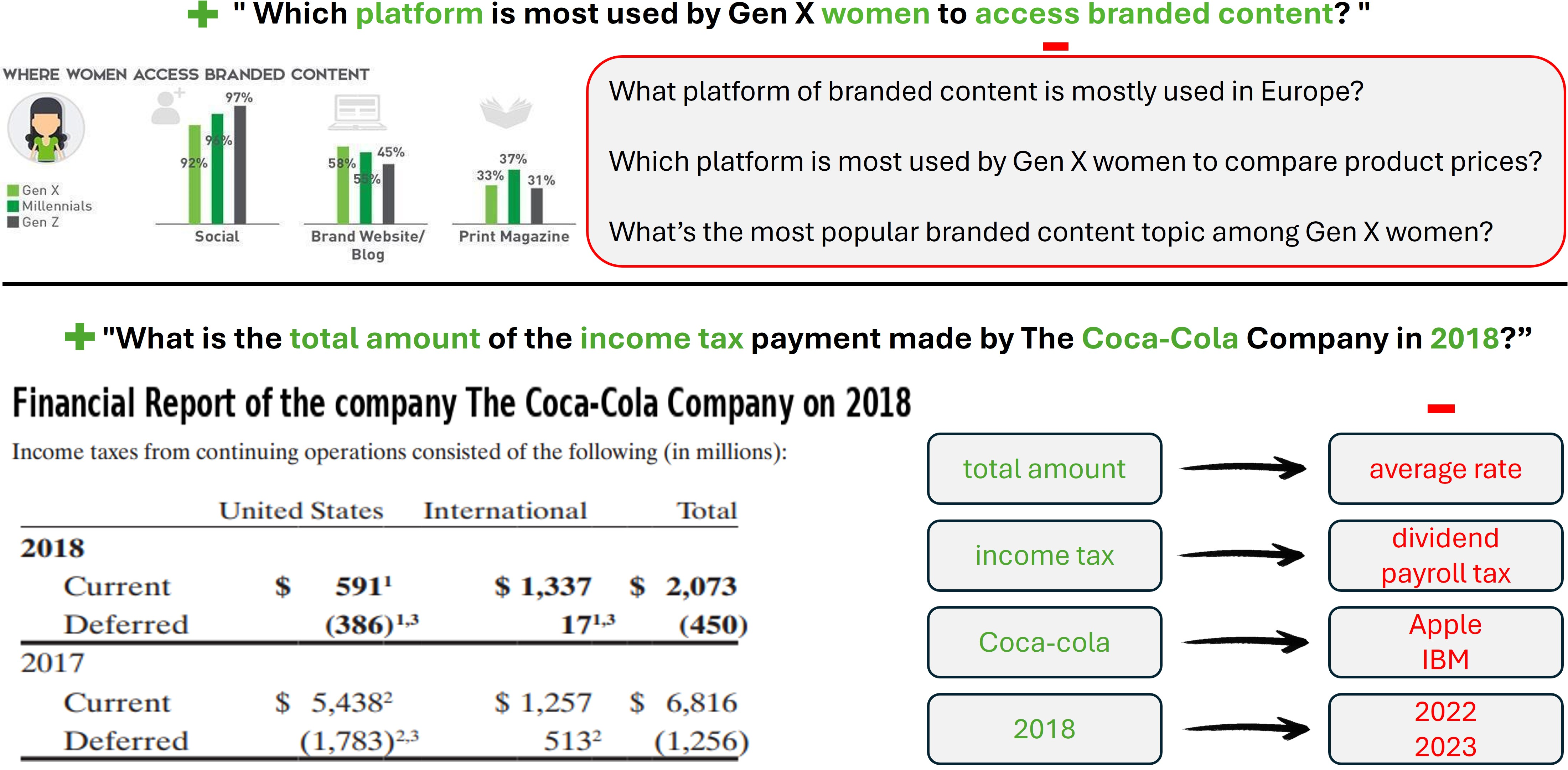
Figure 4: Examples of Our Generated Negative Queries.
Finance-Specific Adaptation
Leveraging data variability inherent in financial documents, a finance-tailored dataset was constructed. This set employs fine-grained negative query generation to tackle prevalent challenges, such as distinguishing temporal identifiers or financial metrics.
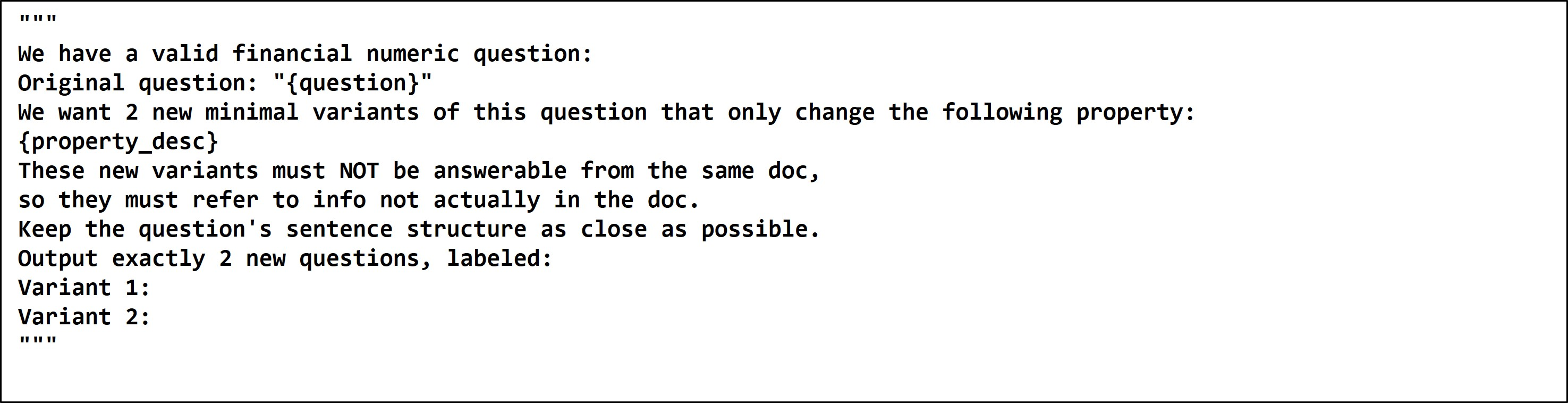
Figure 5: Finance Negative Generation Prompt.
Results and Evaluation
Datasets and Benchmarks
DocReRank's effectiveness was validated across benchmarks like ViDoReV2 and Real-MM-RAG, emphasizing its retrieval and precision capabilities. The datasets harnessed include Col-HNDoc for document mining and novel datasets like Col-HNQue for procedural negatives.
Model Training
A multimodal reranker based on Qwen2-VL-2B-Instruct, DocReRank capitalizes on LoRA to maintain relevance throughout document evaluation and query matching. Performance enhancements were pronounced when DocReRank data was introduced, eclipsing models reliant solely on document-level negatives.
The reranker demonstrates superior learning, employing tripartite (query, image, label) training parameters, bolstered by efficient data division into negatives and rephrasings.
Conclusion
The Single-Page Hard Negative Query Generation method outlined provides a substantial leap forward for refining RAG frameworks. In doing so, it unearths new paradigms in retrieval precision, affording significant cross-domain adaptability. Future developments are projected to extend this query generation model, cultivating more finely-tuned and application-specific datasets for enhanced balanced output. The rigorous generation and validation processes prescribed could serve as a benchmark for future endeavors into document-centric retrieval frameworks.
In addressing the inherent inflexibility and computational intensiveness of traditional document-level mining, the methodology demonstrated promises discernible in its measured improvements over extant models. This positions it as a vital tool for contexts necessitating finely nuanced data discrimination, notably in domains rich with intricate detail, such as financial documentation.