- The paper introduces ReaL, a reinforcement learning framework that leverages program analysis feedback to improve code security, maintainability, and functionality.
- It employs a hybrid reward system combining static analysis and unit tests to guide LLMs in generating production-quality code.
- Experimental results show that ReaL outperforms baseline methods in benchmarks targeting security vulnerabilities and maintainability issues.
Training LLMs to Generate Quality Code with Program Analysis Feedback
This paper presents ReaL, a reinforcement learning framework designed to improve code generation by leveraging program analysis feedback. The approach focuses on enabling LLMs to produce production-quality code that meets high standards of security and maintainability, alongside functional correctness. This framework addresses the limitations of existing methods, which often require manual annotations or rely on brittle heuristics, by using verifiable, reference-free reward signals in the training process.
ReaL Framework Overview
ReaL is formulated around two automated feedback mechanisms: program analysis for detecting security and maintainability defects, and unit tests verifying functional correctness. The reinforcement learning process uses these signals to adjust the LLM's code generation policies, driving improvements in code quality without significant human intervention.
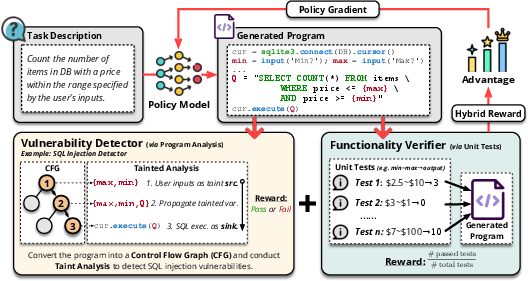
Figure 1: Overview of the ReaL framework demonstrating how the policy-gradient update is informed by the integrated feedback of vulnerability detection and functionality verification.
Quality Code Definition
The paper defines quality code as code that is functionally correct, secure, and maintainable. Security vulnerabilities (e.g., SQL injections, CSRF) and maintainability issues (e.g., missing type annotations) are explicitly targeted. ReaL is designed to concurrently optimize for these dimensions of code quality.
Reinforcement Learning with Hybrid Rewards
ReaL employs a hybrid reward system, balancing between code quality and functionality rewards:
- Quality Reward: Derived from the outputs of program analysis; detects vulnerabilities and confirms adherence to maintainability standards.
- Functionality Reward: Assessed via unit tests, which confirm the functional correctness of code snippets.
The hybrid reward function combines these components linearly, adjusting weights to reflect the emphasis on quality versus functionality.
Vulnerability Detector Development
The development of security and maintainability detectors is integral to ReaL. The detectors rely on program analysis to transform code into SSA form, evaluate data flows, and use these insights to identify vulnerabilities. Tools like MyPy are utilized for static analysis, particularly for enforcing maintainability in Python code.
Experimental Evaluation
ReaL's efficacy is validated across benchmarks like SecCodePLT+ for security inspections and SafeSQL for SQL injection vulnerabilities. The benchmarks incorporate a broad spectrum of real-world coding scenarios where code must fulfill both functional and quality criteria.
Results and Baseline Comparison
ReaL consistently outperformed state-of-the-art methods across varied model scales, demonstrating improvements in the conjunction of functionality and quality metrics.
- Security-Sensitive Tasks: ReaL displayed superior performance, particularly in SafeSQL, achieving unprecedented rates in safely constructed SQL queries.
- Maintainability-Aware Tasks: The framework maintained a lead in generating code that met both functional and maintainability standards, significantly outperforming prompt-based and SFT baselines.
Discussion
Trade-offs and Implementation Considerations
The paper discusses the trade-offs inherent in single versus hybrid reward systems. Pure functionality-driven models tend to ignore security vulnerabilities, while exclusive focus on quality degrades functional output. ReaL, with its nuanced hybrid rewards, provides a balanced solution, mitigating reward hacking through a comprehensive evaluation approach.
Conclusion
ReaL demonstrates scalability and effectiveness in improving both the quality and correctness of code generated by LLMs. Future work will extend the breadth of vulnerability coverage and further refine detector accuracy, enhancing the robustness of feedback mechanisms integral to the framework. By automating complex quality assessments, ReaL provides a scalable solution for developing secure and maintainable code in production environments.