- The paper introduces MedHELM, a framework built on a clinician-validated taxonomy covering 121 tasks in 5 medical categories to assess LLM real-world performance.
- It integrates 35 benchmarks, blending existing and newly created datasets with an innovative LLM-jury evaluation to enhance accuracy over traditional metrics.
- Results show top models excel in tasks like Clinical Note Generation while highlighting challenges in structured reasoning and cost-efficient deployment.
Holistic Evaluation of LLMs for Medical Tasks
The paper "MedHELM: Holistic Evaluation of LLMs for Medical Tasks" addresses the gap between high performances of LLMs on medical exams and their applicability in real-world clinical settings. The study introduces MedHELM, an evaluation framework aimed at assessing LLM performance on medical tasks through a clinician-validated taxonomy and comprehensive benchmarks, providing insights into the cost-performance trade-off and scalability of medical applications.
Framework of MedHELM
The MedHELM framework encompasses three primary components:
- Clinician-Validated Taxonomy: The taxonomy was developed with input from 29 clinicians, organizing 121 tasks into 5 main categories and 22 subcategories. This structure allows comprehensive evaluation across the spectrum of medical activities. The categories include Clinical Decision Support, Clinical Note Generation, Patient Communication, Medical Research Assistance, and Administration.
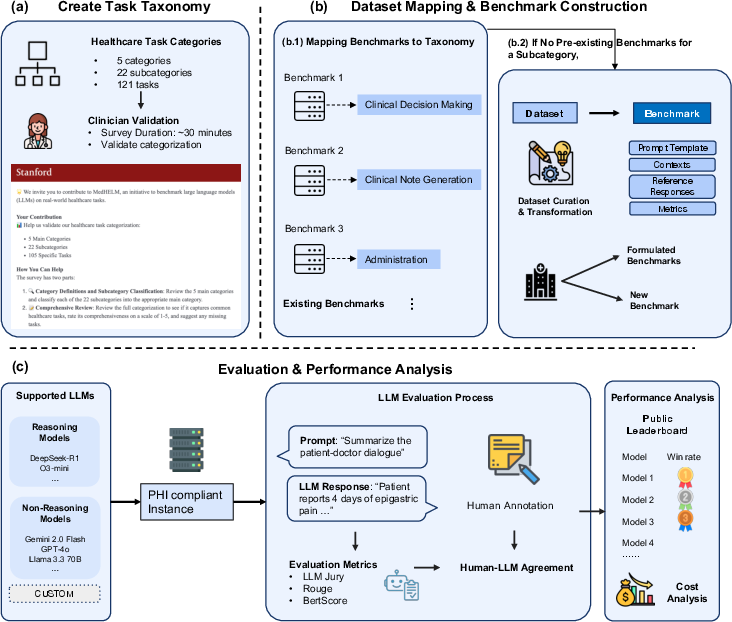
Figure 1: This figure illustrates: (a) a clinician-validated taxonomy organizing 121 medical tasks into 5 categories and 22 subcategories; (b) a suite of benchmarks that map existing benchmarks to this taxonomy and introduces new benchmarks for complete coverage; and (c) an evaluation comparing reasoning and non-reasoning LLMs, with model rankings, LLM jury-based evaluation of open-ended benchmarks, and cost-performance analysis.
- Benchmark Suite: A total of 35 benchmarks span all subcategories, composed of 17 existing benchmarks and 18 newly developed ones, providing exhaustive coverage of tasks. Benchmarks are divided into open-ended and closed-ended types, with a mix of existing, reformulated, and newly created datasets. This suite ensures that models are evaluated on real-world tasks rather than just exam questions.
- Evaluation Methodology: MedHELM employs an LLM-jury evaluation method for open-ended benchmarks, where the outputs of models are assessed by LLMs themselves, ensuring agreement with clinician ratings. This method demonstrated superior accuracy compared to traditional evaluation metrics like ROUGE-L and BERTScore.
The evaluation of nine frontier LLMs reveals significant performance variability:
- Top Performers: DeepSeek R1 and o3-mini stood out as reasoning models with win-rates of 66% and 64% respectively, particularly excelling in Clinical Note Generation and Medical Research Assistance.
- Cost-Efficiency: The Claude 3.5 Sonnet model was notably cost-effective, achieving competitive performance at about 40% less computational cost compared to leading models.
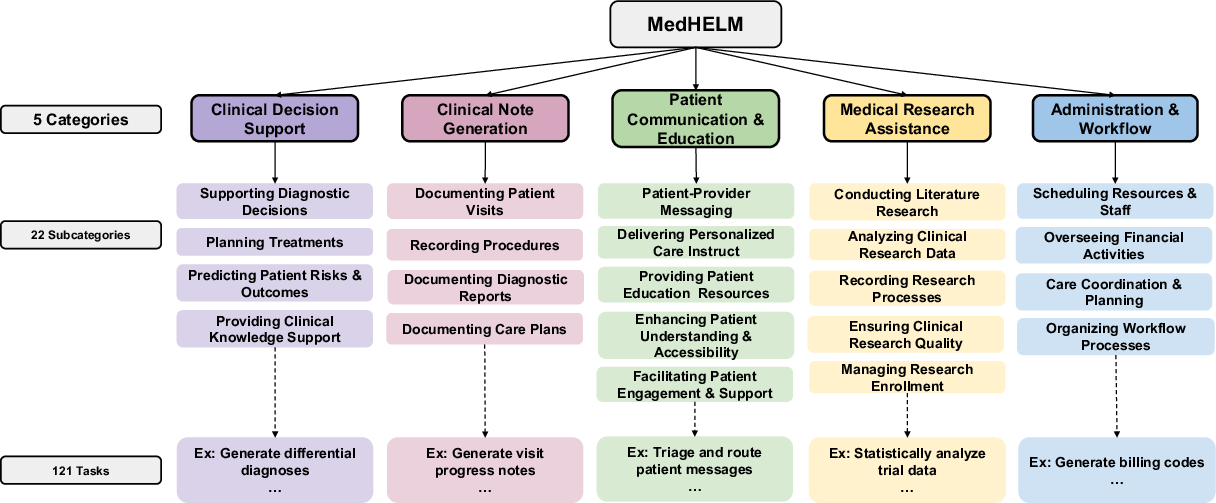
Figure 2: Heatmap of normalized scores (0–1) for each model (rows) across 35 benchmarks (columns). Dark green indicates high performance; dark red indicates low performance.
- Category Performance: Models performed best in Clinical Note Generation and Patient Communication tasks, attributed to natural language processing strengths, while structured reasoning tasks like Clinical Decision Support posed challenges.
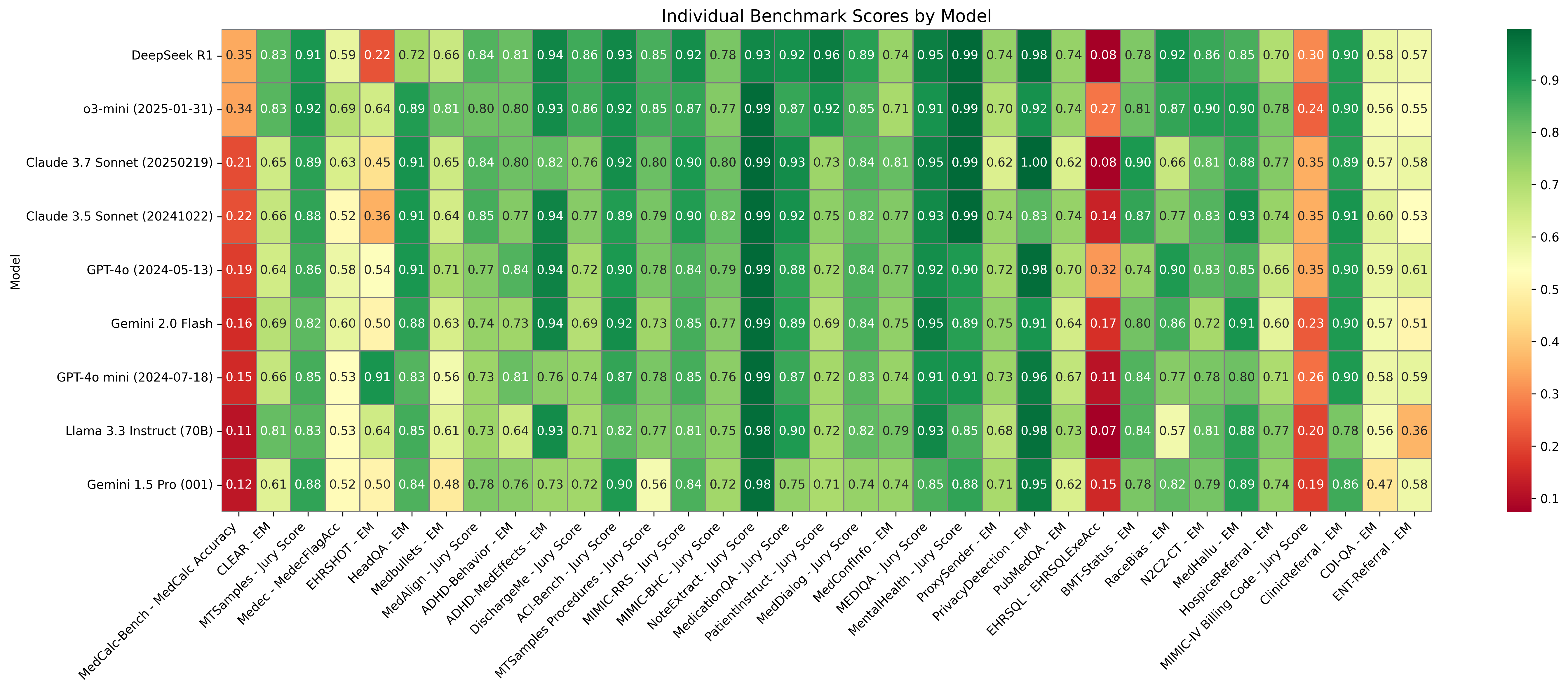
Figure 3: Mean normalized scores (0-1 scale) across the 5 categories for all evaluated models. Darker green represents higher scores.
A critical consideration in MedHELM is the balance between performance and computational cost:
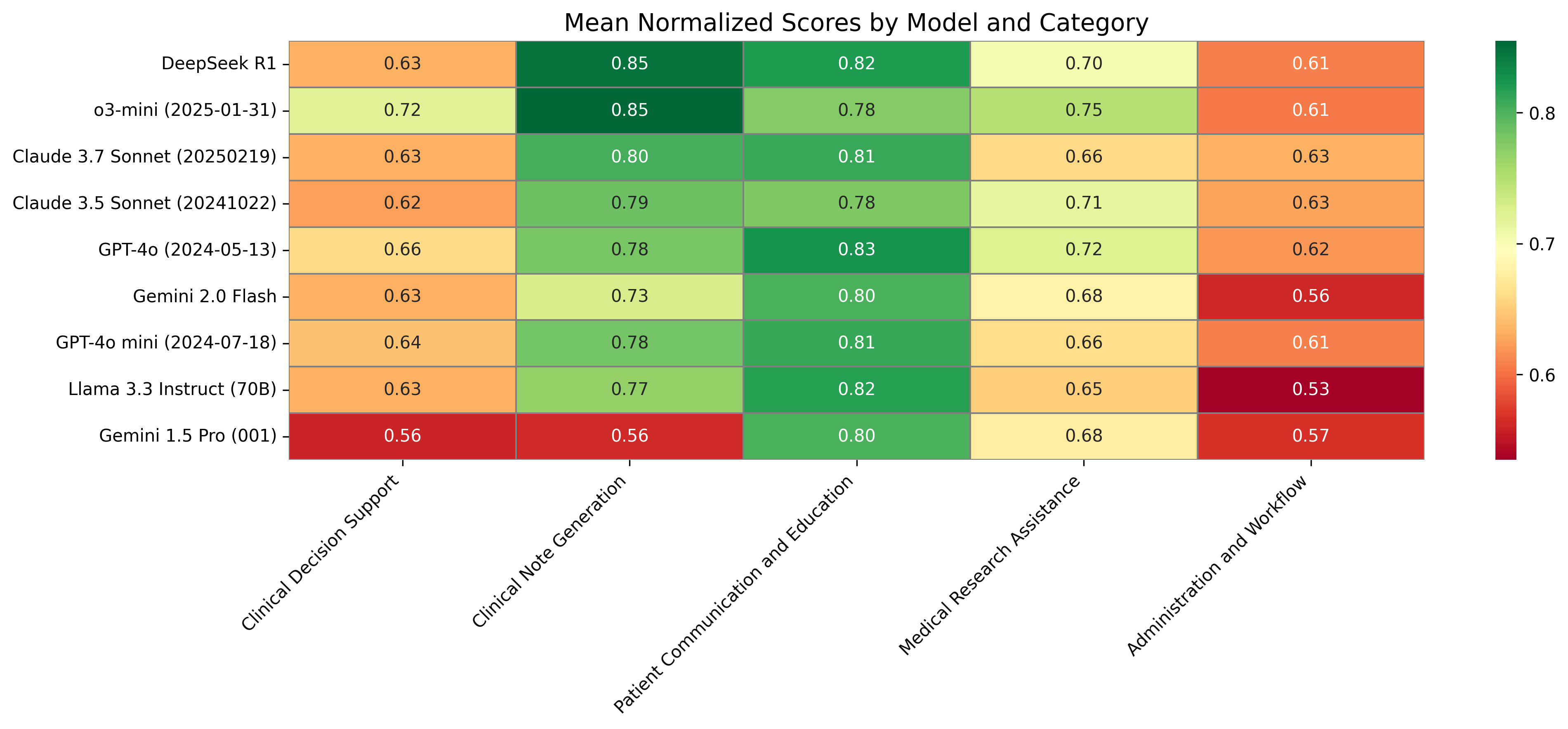
Figure 4: Scatter plot of mean win-rate (y-axis) versus estimated computational cost (x-axis) for each of the 9 models across 35 benchmarks.
- Trade-Off Insights: While high-performing reasoning models like DeepSeek R1 incur greater computational expenses, models such as Claude 3.5 Sonnet provide a sweet spot, achieving nearly top-tier results with significantly lower costs.
Implications and Future Directions
MedHELM's framework highlights the importance of diverse, real-world benchmarks for evaluating medical AI. By providing an open-source platform, it encourages continuous improvement and adaptation as LLM capabilities evolve. Future developments could refine evaluation methods, particularly for complex, subjective tasks in Clinical Decision Support and Administration workflows.
Conclusion
"MedHELM: Holistic Evaluation of LLMs for Medical Tasks" establishes a comprehensive framework to assess LLMs in a clinical context, emphasizing practical performance over theoretical benchmarks. It sets a foundation for real-world AI deployment in healthcare, promoting transparency and ongoing refinement of medical task evaluation.