- The paper introduces a calibration approach that leverages sub-clause frequencies with multivariate Platt scaling to improve LLM uncertainty estimation for SQL queries.
- Experiments on SPIDER and BIRD datasets show significant enhancements in calibration metrics such as Brier score, ECE, and AUC compared to traditional methods.
- The method effectively detects errors in structured SQL queries, thereby increasing transparency and reliability in text-to-SQL systems.
Calibrating LLMs for Text-to-SQL Parsing by Leveraging Sub-clause Frequencies
Introduction
The paper "Calibrating LLMs for Text-to-SQL Parsing by Leveraging Sub-clause Frequencies" (2505.23804) addresses the challenge of providing calibrated confidence scores for the correctness of SQL queries produced by LLMs. Text-to-SQL parsing involves converting natural language questions into structured SQL queries, which is vital for accessing large-scale structured databases without needing expertise in SQL syntax. Despite the proficiency of LLMs in this task, they often yield overconfident erroneous outputs. Thus, calibrated confidence measures are crucial for deploying trustworthy text-to-SQL systems.
The paper establishes a benchmark for post-hoc calibration methods applied to LLM-based text-to-SQL tasks. Platt scaling is utilized initially, delivering notable calibration improvements over raw model probabilities. The authors introduced a novel calibration method using sub-clause frequency (SCF) scores combined with a multivariate Platt scaling (MPS) framework. This approach exploits the structured nature of SQL, where individual sub-clause frequencies provide more granular correctness signals. Experiments on SPIDER and BIRD datasets demonstrate that this method significantly enhances calibration and error detection performance compared to traditional Platt scaling.
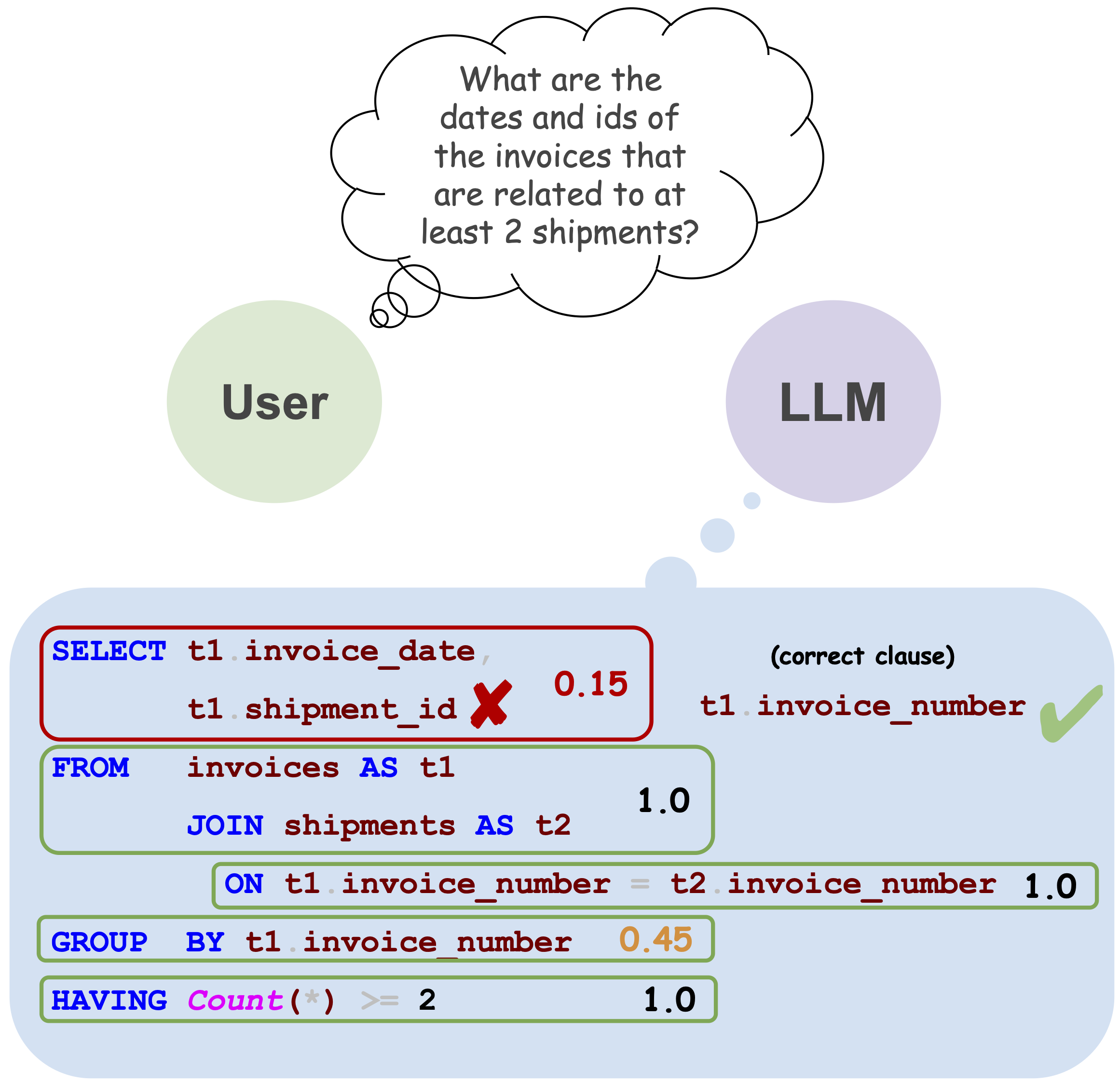
Figure 1: An example question from the SPIDER dataset and an output produced by T5 3B. Correct and incorrect sub-clauses are indicated, with corresponding sub-clause frequency (SCF) scores.
Calibration Techniques
Calibration is defined as the alignment between reported probabilities and observed correctness outcomes. The paper adopts standard statistical definitions and methods adapted to the text-to-SQL domain. The goal is to calibrate a scoring function s, mapping SQL queries to confidence scores reflecting the likelihood of correctness, using post-hoc methods like Platt scaling.
Platt scaling adjusts model scores with a logistic regression, refining probabilistic outputs for improved calibration. A significant limitation of traditional Platt scaling is its reduction to a univariate calibration approach. The paper's novel multivariate Platt scaling extends this method by incorporating multiple signals derived from SQL syntax, specifically the frequency of sub-clauses in likely outputs. This multivariate approach aims to produce well-calibrated probabilities that communicate uncertainty effectively.
Methods and Approaches
The paper's methodological framework is centered around MPS and SCF scores. MPS extends Platt scaling by integrating signals from multiple sub-clause frequencies into a comprehensive confidence assessment. For each SQL output, SCF scores are computed by sampling alternative outputs using nucleus sampling and beam search techniques, and counting the frequency of each sub-clause across samples. These scores are then fed into a logistic regression calibration model, learning the correlation of sub-clause consistency with correctness.
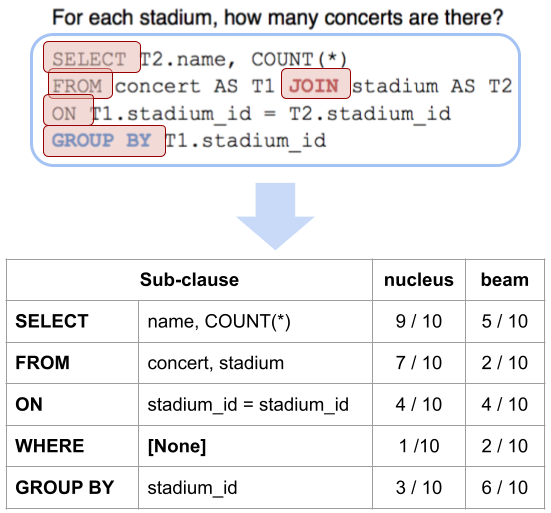
Figure 2: Parsing a query to derive SCF scores, illustrating the frequency counting process across sampled outputs.
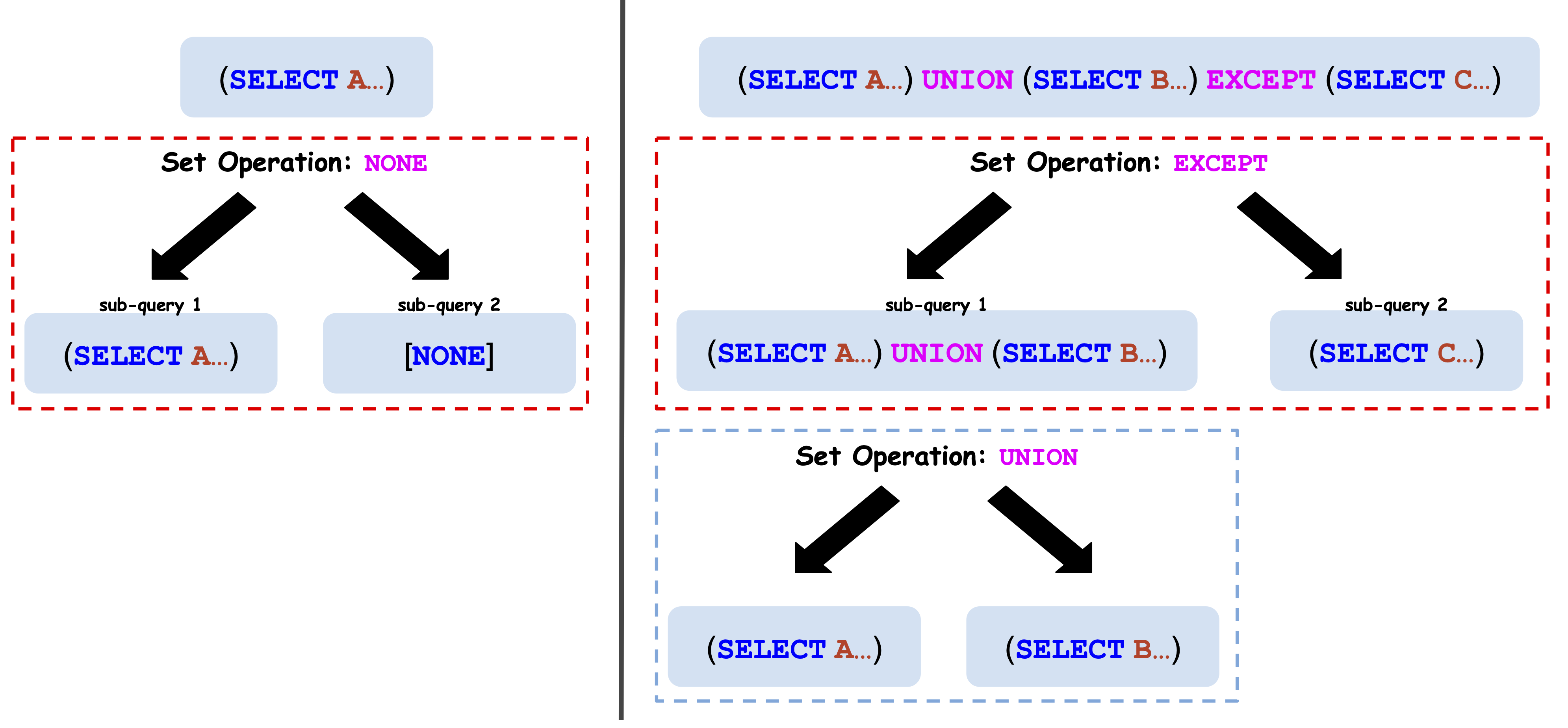
Figure 3: SQL queries parsed into tree structures, highlighting sub-clause computation for SCF signals.
Experimental Evaluation
The paper evaluates calibration efficacy on the SPIDER and BIRD datasets, established benchmarks for text-to-SQL parsing. Experiments compare raw LLM outputs, traditional Platt scaling, and the proposed MPS + SCF approach across multiple metrics: Brier score, expected calibration error (ECE), adaptive calibration error (ACE), and area under the curve (AUC) for error detection.
Results show that MPS significantly outperforms both uncalibrated and Platt-scaled probabilities. MPS consistently improves calibration error metrics and successfully increases AUC scores indicating enhanced error detection capabilities. The method demonstrates superior calibration across varied LLM architectures and query complexities, underscoring the utility of integrating structured SQL signals in calibration processes.
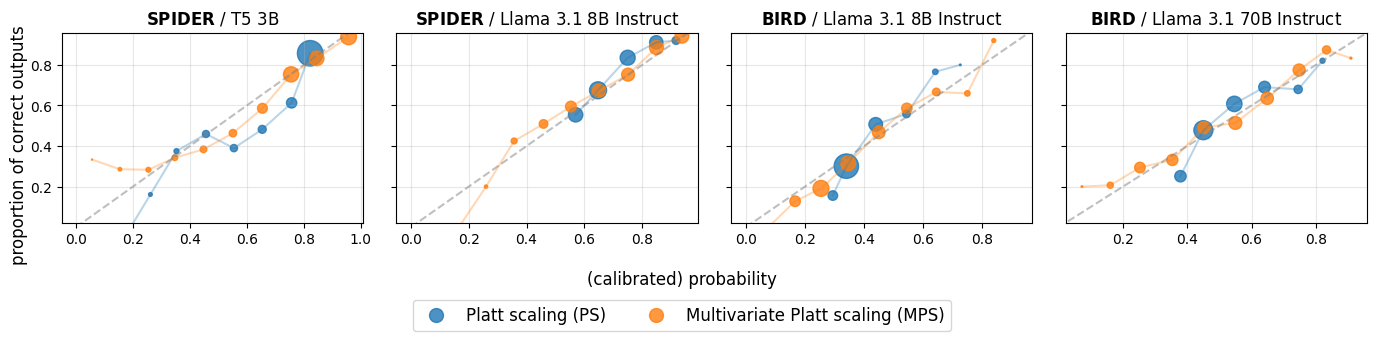
Figure 4: Calibration curves comparing Platt scaling and multivariate Platt scaling using fixed-width ECE-style bins.
Conclusion
This work presents a precise and innovative approach to calibrating confidence scores in LLM-based text-to-SQL parsing. By leveraging the structured signals inherent in SQL syntax, the proposed MPS + SCF method offers substantial improvements in predictive uncertainty calibration. The findings hold significant implications for enhancing transparency and reliability in semantic parsing tasks. Future work may extend this calibration methodology to other domains where structured output parsing is prevalent, further refining uncertainty quantification in AI systems.