- The paper introduces LKD-KGC, a framework that autonomously constructs domain-specific knowledge graphs using hierarchical dependency parsing.
- It achieves improved entity and relation extraction precision and recall through context-aware schema generation and triple extraction without predefined schemas.
- The framework demonstrates robustness across diverse datasets, outperforming state-of-the-art methods in both public and private corpora.
Domain-Specific KG Construction via LLM-driven Knowledge Dependency Parsing
Introduction
This essay describes the LKD-KGC framework, which addresses challenges in constructing domain-specific knowledge graphs (KGs) using LLMs. The framework introduces a method for unsupervised KG construction, systematically incorporating hierarchical knowledge dependency parsing to enhance precision and recall in entity and relationship extraction. Domain-specific corpora demand specialized techniques, given their complex terminology, hierarchical knowledge, and limited external references. LKD-KGC leverages LLM-driven prioritization and autoregressive schema generation to meet these needs without reliance on predefined schemas or external knowledge.
Framework Overview
LKD-KGC consists of three main components: Dependency Evaluation, Schema Definition, and Triple Extraction, each contributing to an integrated approach for processing domain-specific corpora. This methodology prioritizes global knowledge dependencies through hierarchical document processing (Figure 1).
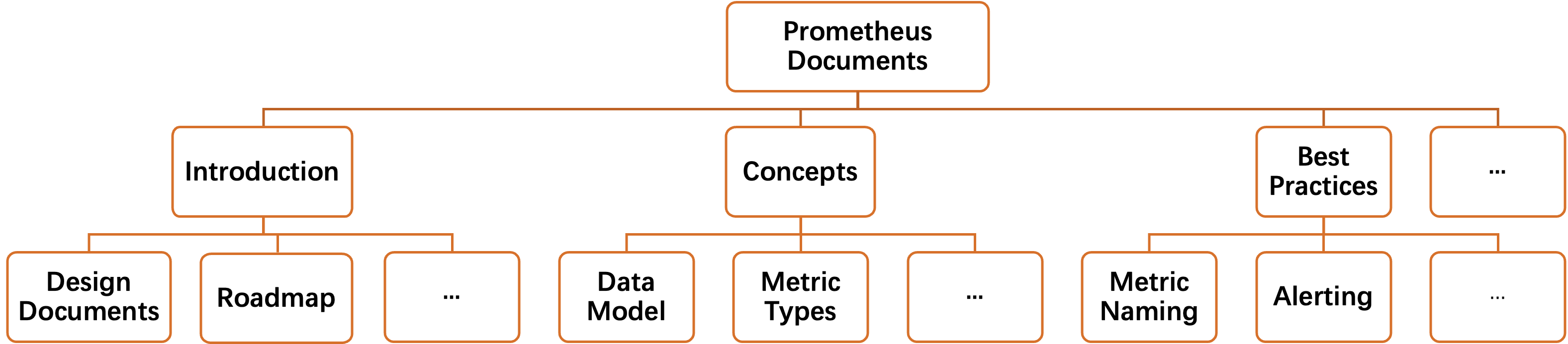
Figure 1: The directory structure of Prometheus documents, demonstrating latent ideal accessing orders for knowledge graph construction.
Dependency Evaluation
This module determines the optimal order for document processing by generating context-aware summaries that integrate cross-document knowledge. It employs vector retrieval to manage context length constraints in LLMs, ensuring efficient hierarchical knowledge synthesis.
Schema Definition
Entity types are extracted from contextually enriched summaries, after which clustering and semantic deduplication refine the entity schema. Prompts guide LLMs to define comprehensive and coherent entity schemas using retrieved contextual knowledge.
Under the guidance of an established entity schema, triples are extracted from original documents based on entity types without predefined relation types. This ensures that only meaningful relationships are constructed into the final KG.
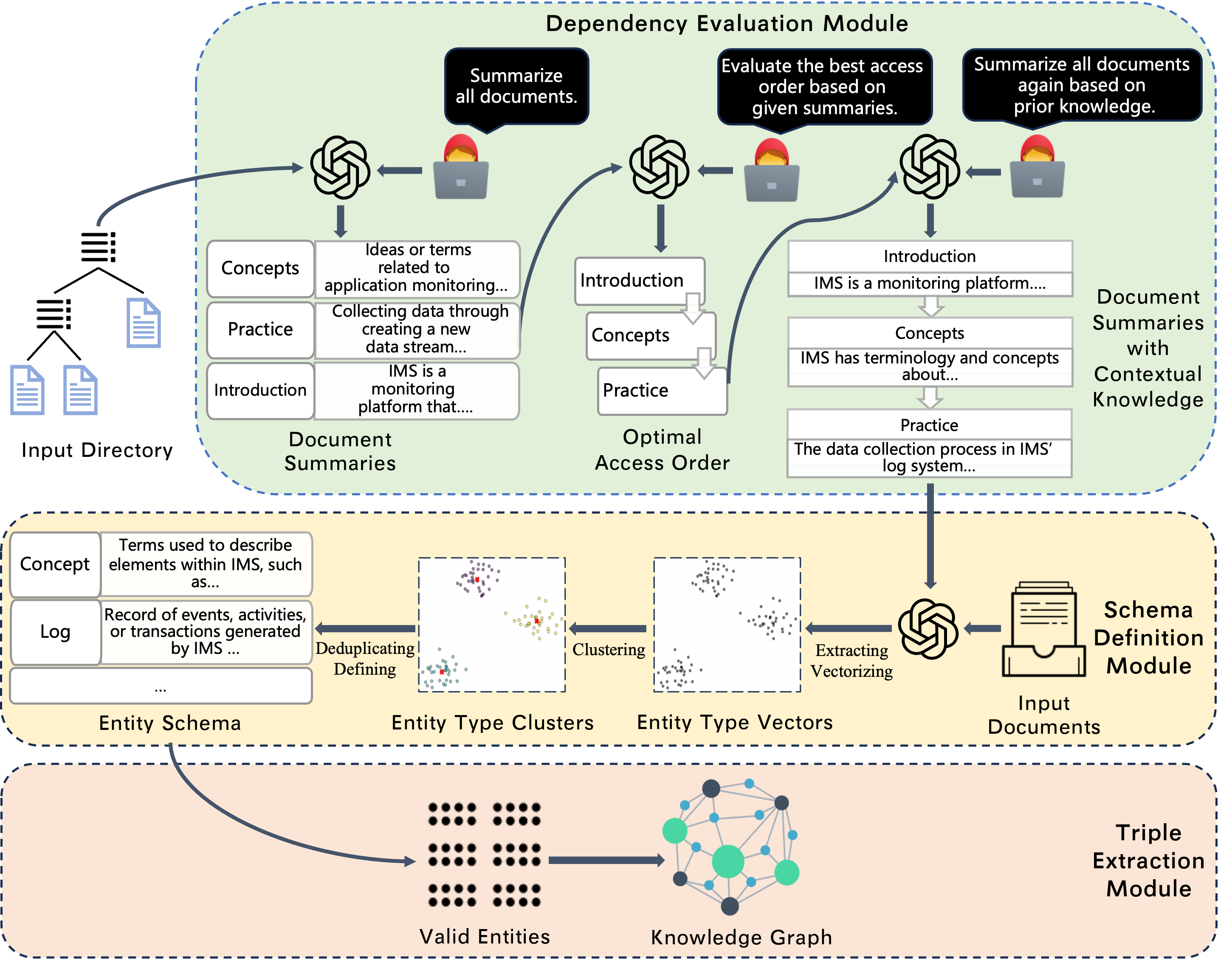
Figure 2: The framework of LKD-KGC, illustrating comprehensive domain-specific KG construction using hierarchical dependency parsing.
Experimental Evaluation
Public Corpora
LKD-KGC was evaluated using public datasets, demonstrating superior precision and recall compared with existing LLM-based methods. For the Prometheus dataset, it achieved significant improvements in extracting valid entities and relations, as depicted by higher recall numbers and precision rates.
Private Corpora
On private corpus datasets like IMS documentation, where external references are unavailable, LKD-KGC excelled by fully utilizing internal document contexts. The dependency parsing allowed for accurate extraction of valid entities and relation triples from complex domain-specific texts.
The experimental results underscored LKD-KGC's capability to outperform state-of-the-art baseline methods across diverse datasets and LLM backbones. These improvements in precision and recall metrics highlight the robustness of the framework in handling intricate knowledge dependencies.
Conclusion
The LKD-KGC framework provides an effective solution for constructing high-quality domain-specific knowledge graphs by exploiting LLM-driven knowledge dependency parsing. Its autonomous capability to infer processing sequences and integrate hierarchical contexts results in improved precision and recall rates. These advancements suggest promising directions for future developments in AI-driven KG construction methodologies, particularly in domains with complex and specialized knowledge requirements.