Retrieval-Augmented Generation: A Comprehensive Survey of Architectures, Enhancements, and Robustness Frontiers
Abstract: Retrieval-Augmented Generation (RAG) has emerged as a powerful paradigm to enhance LLMs by conditioning generation on external evidence retrieved at inference time. While RAG addresses critical limitations of parametric knowledge storage-such as factual inconsistency and domain inflexibility-it introduces new challenges in retrieval quality, grounding fidelity, pipeline efficiency, and robustness against noisy or adversarial inputs. This survey provides a comprehensive synthesis of recent advances in RAG systems, offering a taxonomy that categorizes architectures into retriever-centric, generator-centric, hybrid, and robustness-oriented designs. We systematically analyze enhancements across retrieval optimization, context filtering, decoding control, and efficiency improvements, supported by comparative performance analyses on short-form and multi-hop question answering tasks. Furthermore, we review state-of-the-art evaluation frameworks and benchmarks, highlighting trends in retrieval-aware evaluation, robustness testing, and federated retrieval settings. Our analysis reveals recurring trade-offs between retrieval precision and generation flexibility, efficiency and faithfulness, and modularity and coordination. We conclude by identifying open challenges and future research directions, including adaptive retrieval architectures, real-time retrieval integration, structured reasoning over multi-hop evidence, and privacy-preserving retrieval mechanisms. This survey aims to consolidate current knowledge in RAG research and serve as a foundation for the next generation of retrieval-augmented language modeling systems.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper is a big, easy-to-read guide to a popular AI idea called Retrieval-Augmented Generation (RAG). Imagine a smart student (an AI model) that can not only remember what it studied, but also look things up in a library or on the web while answering your question. That’s RAG: it lets a LLM search for facts and then write an answer using what it found. The paper explains how RAG works, the different ways to build it, how to make it faster and more accurate, how to test it, and what problems still need to be solved.
The main questions the paper asks
The authors focus on simple but important questions:
- How do RAG systems combine “searching” and “writing” to give better answers?
- What are the main types of RAG designs, and how do they differ?
- What tricks help RAG retrieve better information, use it wisely, and avoid mistakes or “hallucinations” (made-up facts)?
- How do researchers fairly test RAG systems?
- What trade-offs do RAG systems face, and what should future RAG systems focus on?
How the authors studied it (in everyday terms)
This is a survey paper, which means the authors read and organized a lot of recent RAG research instead of running one single new experiment. They:
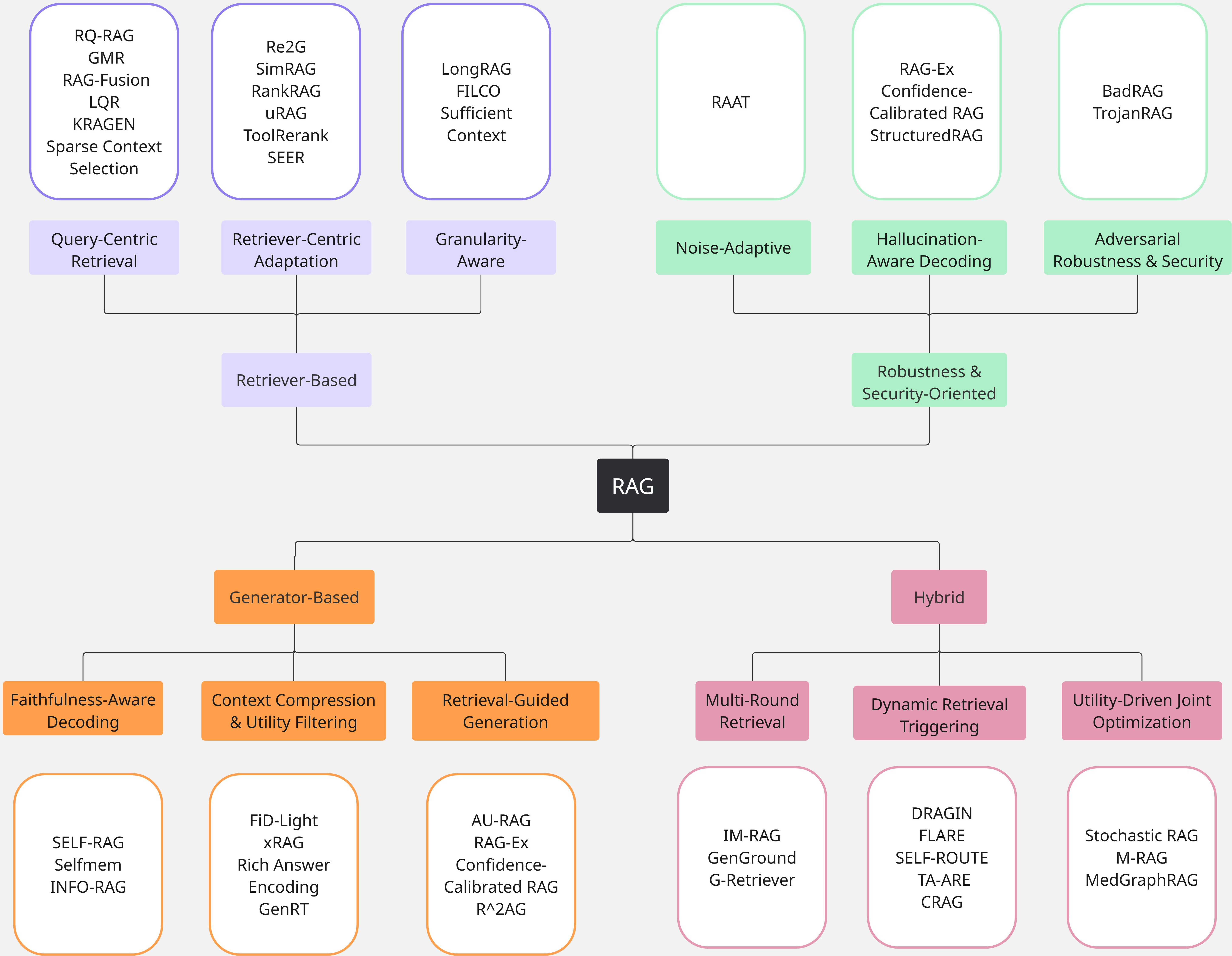
- Built a “map” (taxonomy) of RAG designs, grouped by where the main improvements happen: in the searching part (retriever), the writing part (generator), both working together (hybrid), or in defending against mistakes and attacks (robustness).
- Compared common add-ons that make RAG better, like smarter searching, filtering out irrelevant text, speeding things up, and reordering search results (reranking).
- Reviewed how RAG is tested on tasks like answering questions, solving multi-step problems (multi-hop reasoning), and handling tricky or noisy inputs.
- Pointed out patterns and trade-offs across many studies, and listed open challenges.
Key terms explained simply:
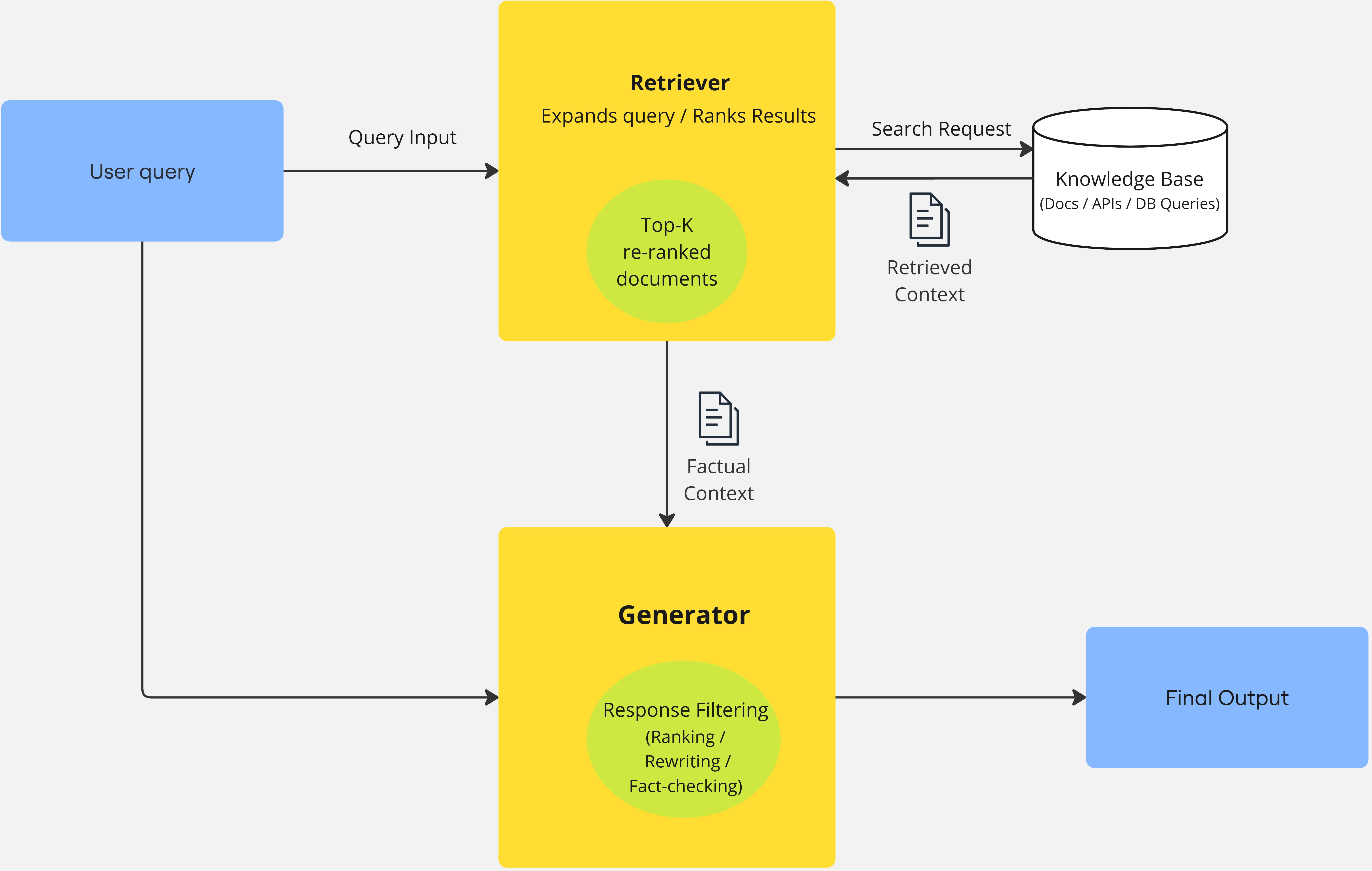
- Retriever: the “searcher” that finds relevant documents.
- Generator: the “writer” (the LLM) that uses the found documents to craft an answer.
- Reranking: reordering search results so the most helpful items come first.
- Multi-hop reasoning: answering a question that needs several facts connected together.
- Hallucination: when the model confidently states something that isn’t true.
What they found and why it matters
The paper organizes RAG systems into four main families and highlights what each does best:
- Retriever-based systems (focus on better searching)
- Goal: Make sure the right information is found.
- How: Rewrite confusing questions, train better searchers, and retrieve the right-sized chunks (not too big, not too small).
- Why it matters: If you search better, the writer has better facts to use. But this can add time and still struggle with unclear questions.
- Generator-based systems (focus on better writing with the evidence)
- Goal: Make the model write more faithful, fact-based answers.
- How: Add self-checking steps, compress or summarize context to fit more info, and guide writing using retrieval hints.
- Why it matters: Reduces hallucinations and makes answers clearer. But it may rely on the searcher being “good enough.”
- Hybrid systems (the searcher and writer work together)
- Goal: Interleave search and writing—look up a bit, write a bit, repeat.
- How: Trigger new searches when the model is unsure, or optimize both parts together.
- Why it matters: Great for complex, multi-step questions. The downside: more complicated and sometimes slower.
- Robustness and security-focused systems (stay reliable under noise and attacks)
- Goal: Keep answers accurate even if the retrieved text is noisy, irrelevant, or maliciously poisoned.
- How: Train with tricky inputs, add constraints to reduce hallucination, and defend against adversarial documents.
- Why it matters: Real-world data is messy. These defenses are crucial for safety, especially in areas like healthcare or finance.
Helpful enhancements across the RAG pipeline:
- Smarter retrieval: adapt when to search, use multiple sources, and refine queries to be clearer.
- Filtering: pick only the most relevant snippets before writing, so the model isn’t distracted.
- Efficiency: speed things up using compression, caching past results, and overlapping searching with writing.
- Reranking: reorder search results to push the best evidence to the top.
- Evaluation: use benchmarks that test not just accuracy, but also grounding (does the answer match the sources?) and robustness.
Important trade-offs the paper highlights:
- Precision vs. flexibility: Narrow, precise searches can miss useful context; broad searches can be noisy.
- Efficiency vs. faithfulness: Faster systems sometimes skip steps that improve truthfulness.
- Modularity vs. coordination: Keeping search and writing separate is simple; tightly coupling them can perform better but is harder to control and explain.
What this means for the future
The authors point to several promising directions:
- Adaptive retrieval: systems that know when to search, where to search, and how much to retrieve, in real time.
- Real-time integration: using up-to-date information quickly without slowing down responses too much.
- Better multi-hop reasoning: connecting multiple pieces of evidence in a structured, step-by-step way.
- Privacy and security: protecting against poisoned sources, reducing data leaks, and keeping sensitive info safe.
Why this matters to you: RAG is becoming a standard way to make AI assistants more accurate and trustworthy. It helps them cite sources, stay up-to-date, and handle specialized topics. Stronger RAG systems could power safer medical advice tools, smarter research assistants, better customer support, and more reliable classroom helpers—while being faster and more secure.
Bottom line
RAG is like giving a smart student instant library access during a test. This survey shows how to make that student search better, write more faithfully, work efficiently, and stay safe from bad information. It also lays out a clear roadmap for building the next generation of trustworthy, fact-grounded AI systems.
Collections
Sign up for free to add this paper to one or more collections.