- The paper introduces a second-order optimization method leveraging RKHS and the Representer Theorem to enable tractable, finite-dimensional policy optimization in reinforcement learning.
- It addresses infinite-dimensional Hessian challenges using a cubic regularized objective, achieving local quadratic convergence for faster updates.
- Empirical validation on benchmarks like CartPole and Lunar Lander demonstrates improved convergence speed and higher rewards compared to first-order methods.
Policy Newton Algorithm in Reproducing Kernel Hilbert Space
The paper "Policy Newton Algorithm in Reproducing Kernel Hilbert Space" introduces a second-order optimization framework for reinforcement learning (RL) policies within Reproducing Kernel Hilbert Spaces (RKHS). This paper addresses the computational challenges associated with RKHS-based policy optimization, offering a novel approach that leverages the Representer Theorem for tractable, finite-dimensional optimization.
Introduction to RKHS and Policy Optimization
RKHS offers a flexible, non-parametric policy representation in RL, enhancing sample efficiency and adaptability across various RL domains. The standard RKHS Policy Gradient methods face convergence limitations due to their first-order nature, particularly in complex problem environments characterized by high curvature. Second-order methods, such as the Policy Newton algorithm, integrate Hessian curvature information to achieve faster convergence and appropriately scaled updates, making them suitable candidates for accelerating RKHS policy optimization.
Challenges and Solution with Policy Newton in RKHS
Developing a Policy Newton method in RKHS involves significant challenges, particularly due to the infinite-dimensional nature of the Hessian operator. This paper circumvents the explicit computation of the Hessian's inverse by introducing a cubic regularized auxiliary objective function. This transformation utilizes the Representer Theorem to convert the infinite-dimensional optimization problem into a tractable finite-dimensional problem, whose dimensionality scales with the data volume.
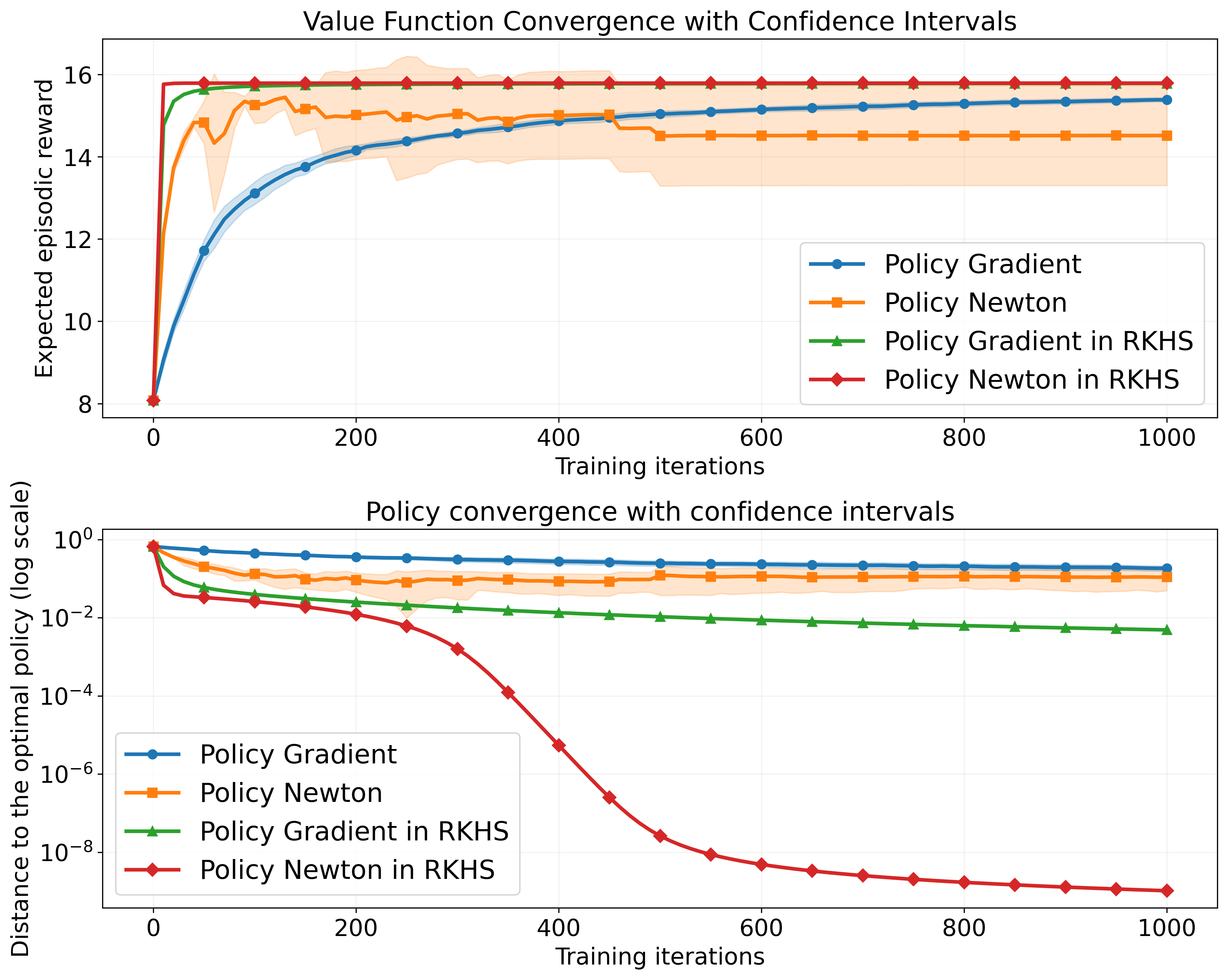
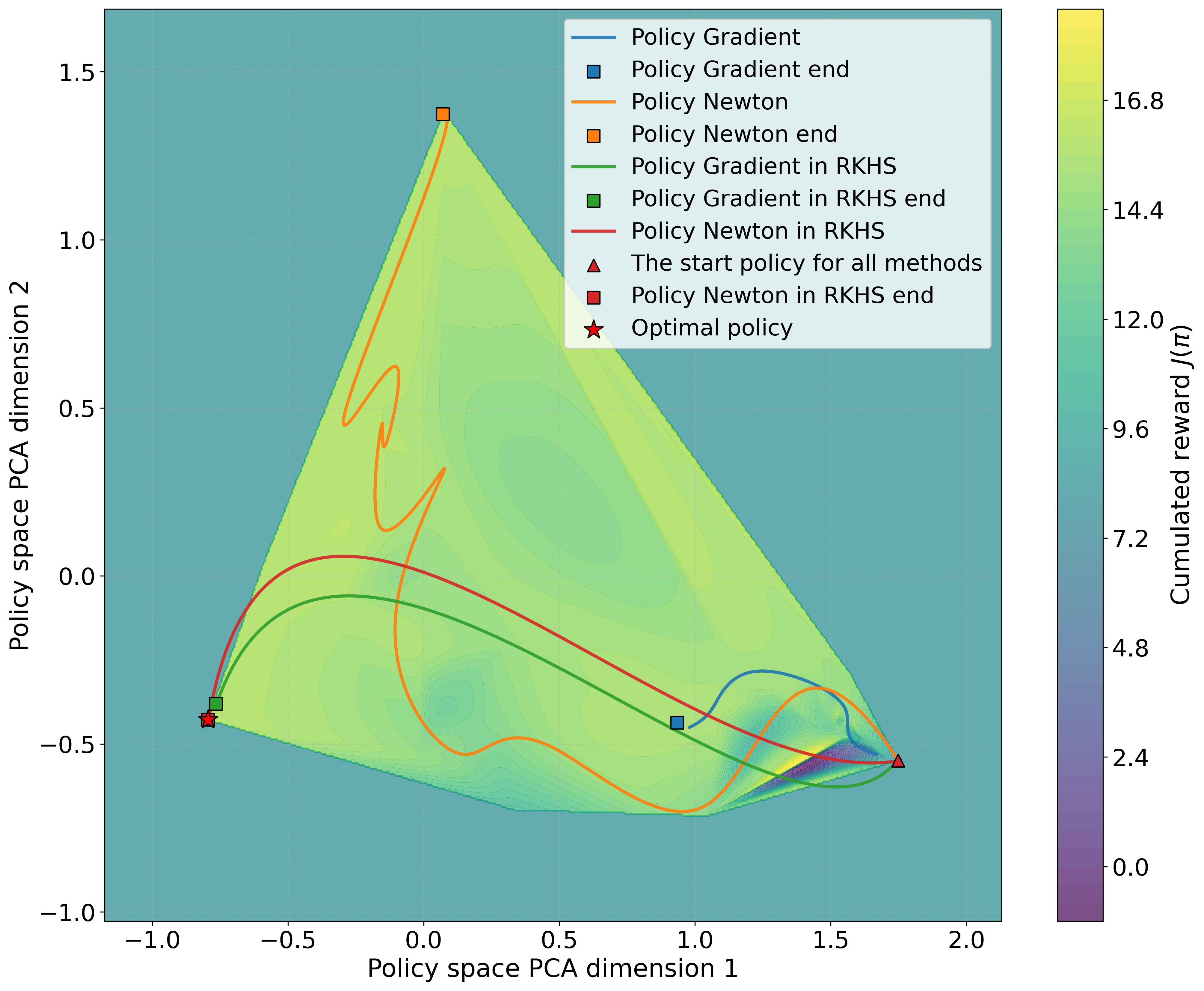
Figure 1: A visual depiction of the convergence process of the proposed approach.
Mathematical Framework and Algorithm
The paper mathematically formulates the Policy Newton RKHS algorithm, detailing the use of the second-order Fréchet derivative. It shows that the Hessian resides in the space HK⊗HK, further integrated into a conventional quadratic optimization framework with cubic regularization. The Representer Theorem aids in transforming this problem into an optimization over a finite-dimensional Euclidean space.
The algorithm iteratively solves the optimization problem using the conjugate gradient method, which is both computationally efficient and capable of handling the dimensionality of practical datasets.
Convergence and Application
The paper provides a rigorous theoretical foundation for the convergence properties of the Policy Newton method in RKHS, demonstrating convergence to a local optimum with a local quadratic convergence rate — a significant advantage over first-order methods.
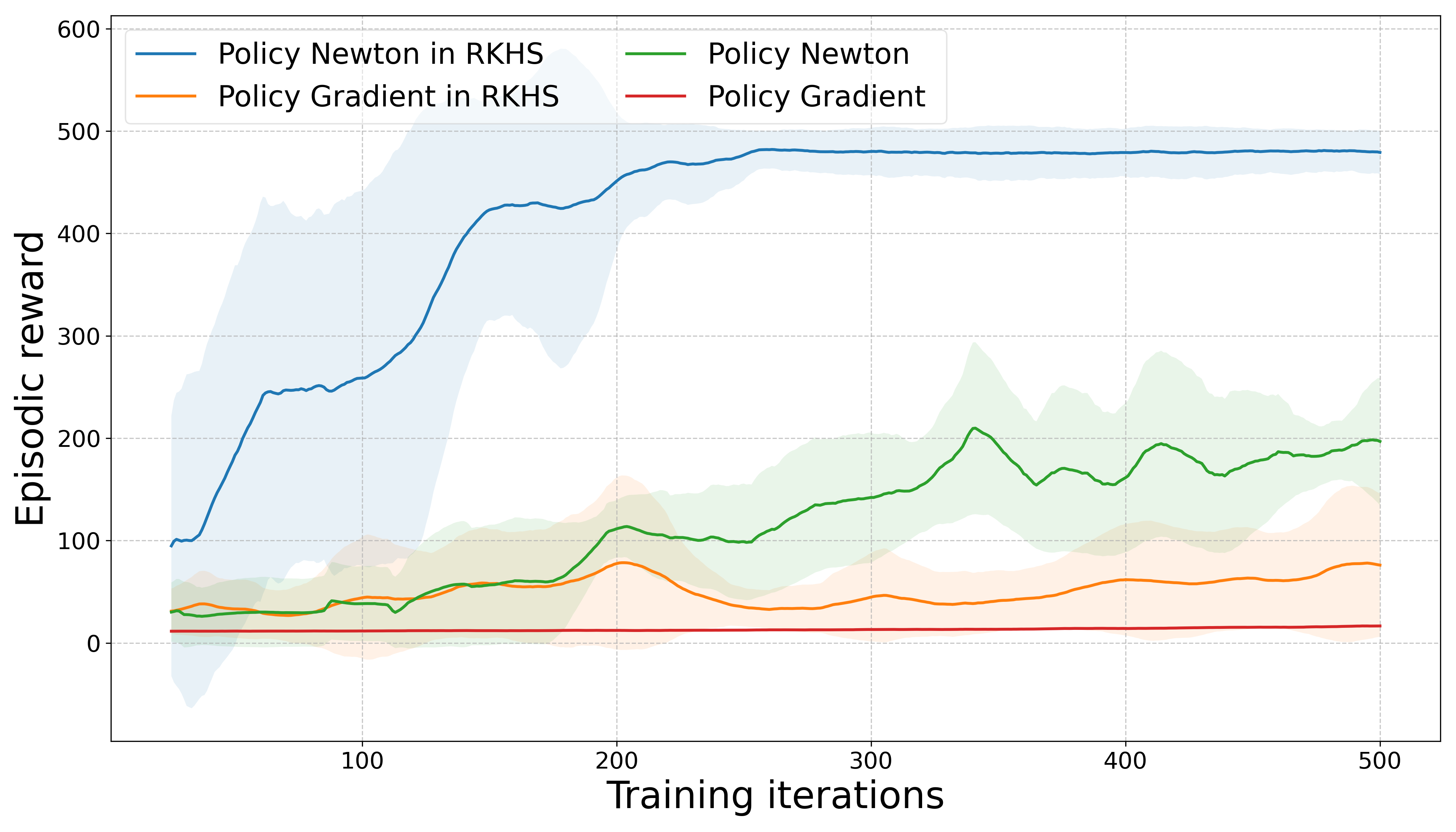
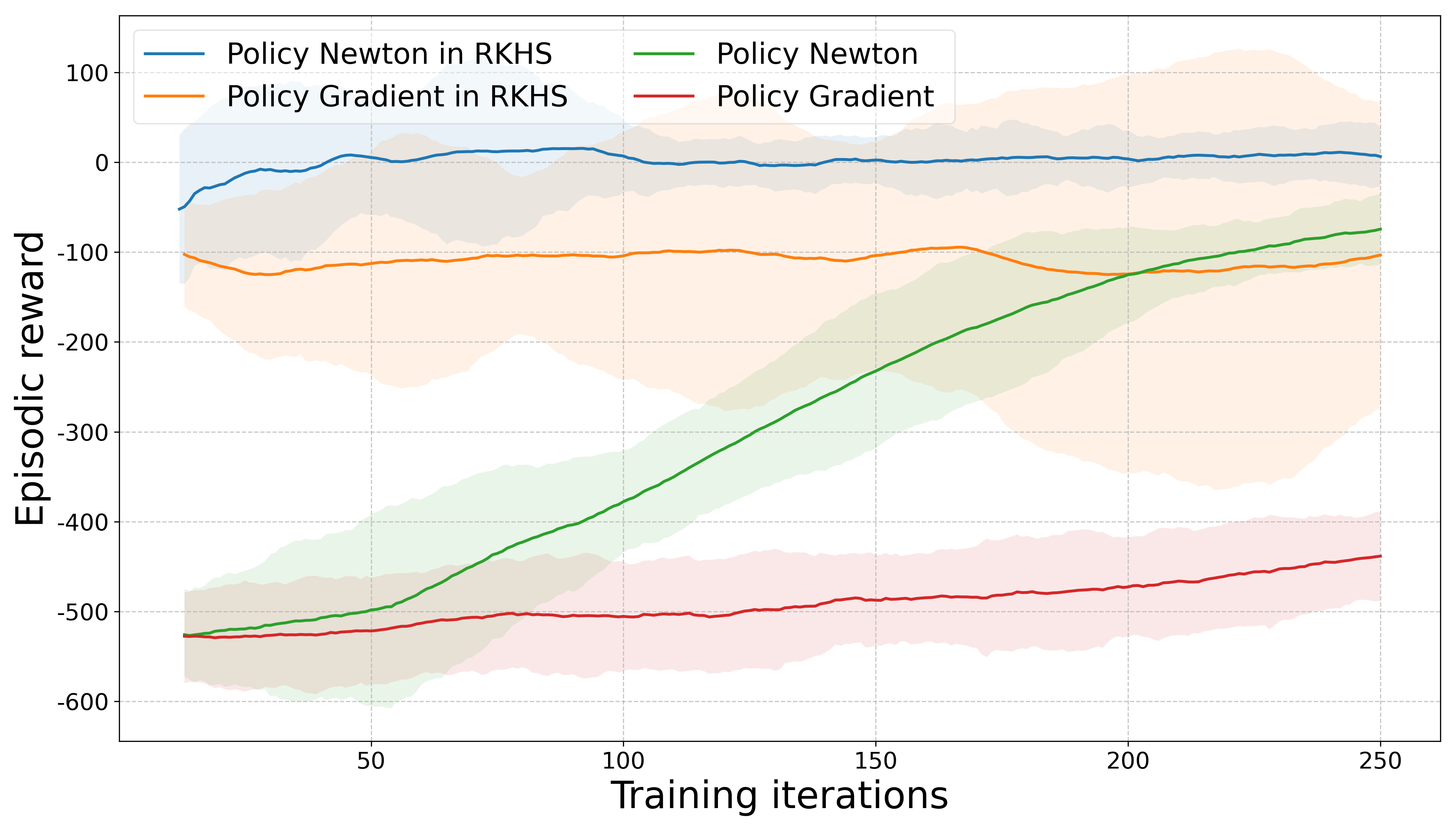
Figure 2: Results from the CartPole environment demonstrating the effectiveness of the Policy Newton approach in RKHS.
Experimental Validation
Empirical evaluations on both a toy financial asset allocation problem and complex RL benchmarks, such as CartPole and Lunar Lander, validate the theoretical strengths of the approach. These experiments illustrate substantially improved convergence speed and higher reward achievements compared to both traditional first-order and parametric second-order baselines.
Conclusion
This research successfully bridges a critical gap between non-parametric policy representations and second-order optimization methods within the RL context. By providing both theoretical proofs and empirical validation, the paper sets a foundation for the broader applicability of Policy Newton methods to more challenging and high-dimensional RL tasks. Future work could integrate these findings with neural network architectures to further explore their potential in large-scale and high-variance environments.