- The paper introduces WebChoreArena, a benchmark featuring complex web tasks that test agents' memory management, precise calculations, and long-term retention.
- It evaluates prominent models like GPT-4o, Claude 3.7 Sonnet, and Gemini 2.5 Pro using metrics such as string_match and url_match, highlighting significant performance discrepancies.
- The study underscores the need for improved memory and operational strategies to effectively manage multi-domain, tedious web tasks and reduce errors like visual hallucinations.
"WebChoreArena: Evaluating Web Browsing Agents on Realistic Tedious Web Tasks" (2506.01952)
Introduction to WebChoreArena
WebChoreArena is presented as an advanced benchmark designed to push the boundaries of web browsing agents beyond general tasks, focusing on tedious and complex web chores. These tasks demand a high level of proficiency in areas such as massive memory management, precise calculation, and long-term memory retention which are developed from fully reproducible and realistic task scenarios derived from existing benchmarks like WebArena.
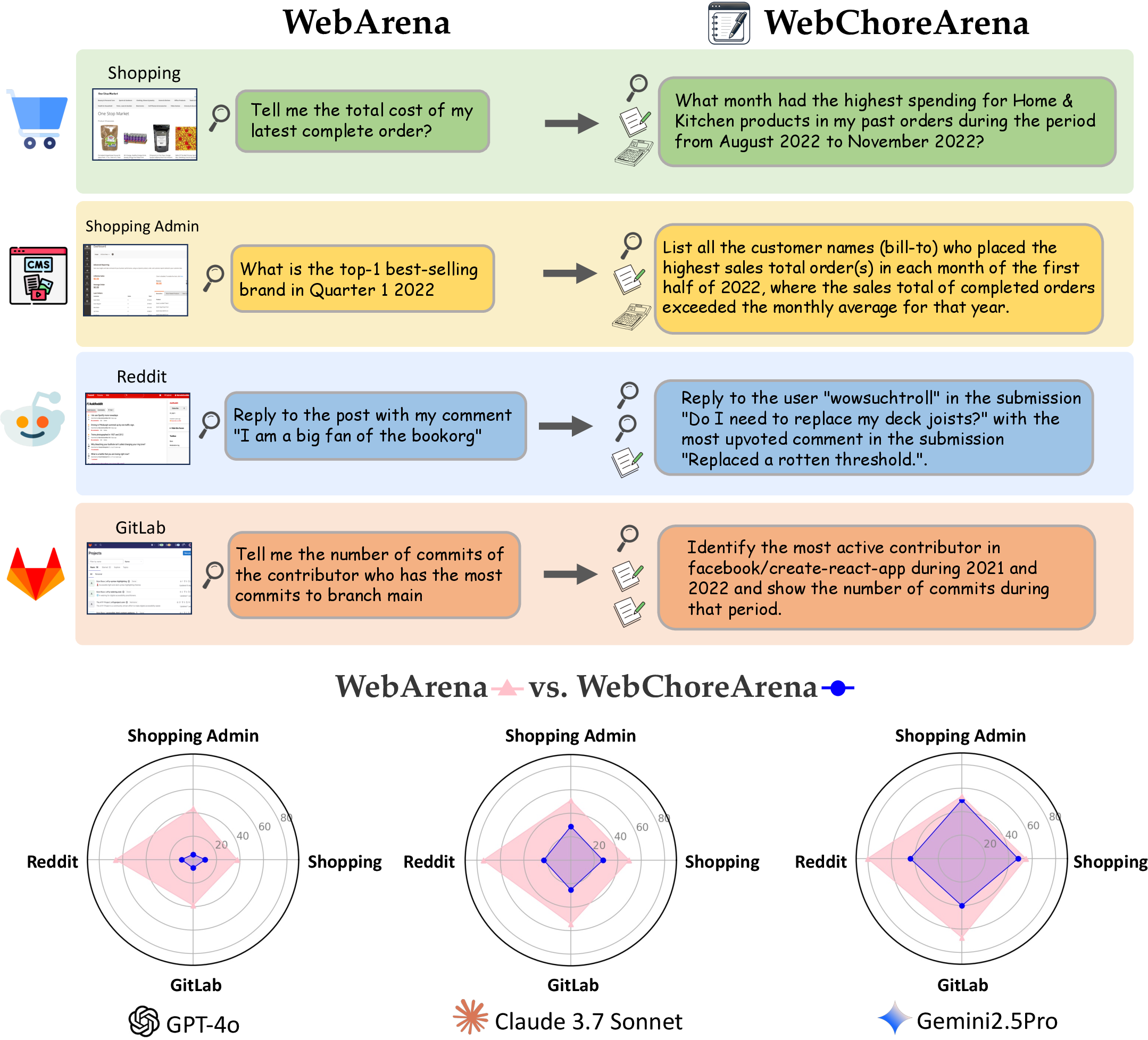
Figure 1: The WebChoreArena challenge. WebChoreArena extends WebArena by introducing more complex and labor-intensive tasks, pushing the boundaries of agent capabilities. This enhanced benchmark allows for a clearer evaluation of progress in advanced models and reveals that even powerful models such as Gemini 2.5 Pro still have significant room for improvement.
Task Design and Evaluation Metrics
WebChoreArena encompasses 532 meticulously crafted tasks across four simulated websites, including platforms for e-commerce, content management, social interactions, and collaborative developments, along with cross-site tasks requiring navigation across multiple domains. These tasks are categorized mainly into four types: Massive Memory, requiring large-scale information retention; Calculation, demanding mathematical operations; Long-Term Memory, requiring retention across multiple webpages; and Other, involving specialized operations.
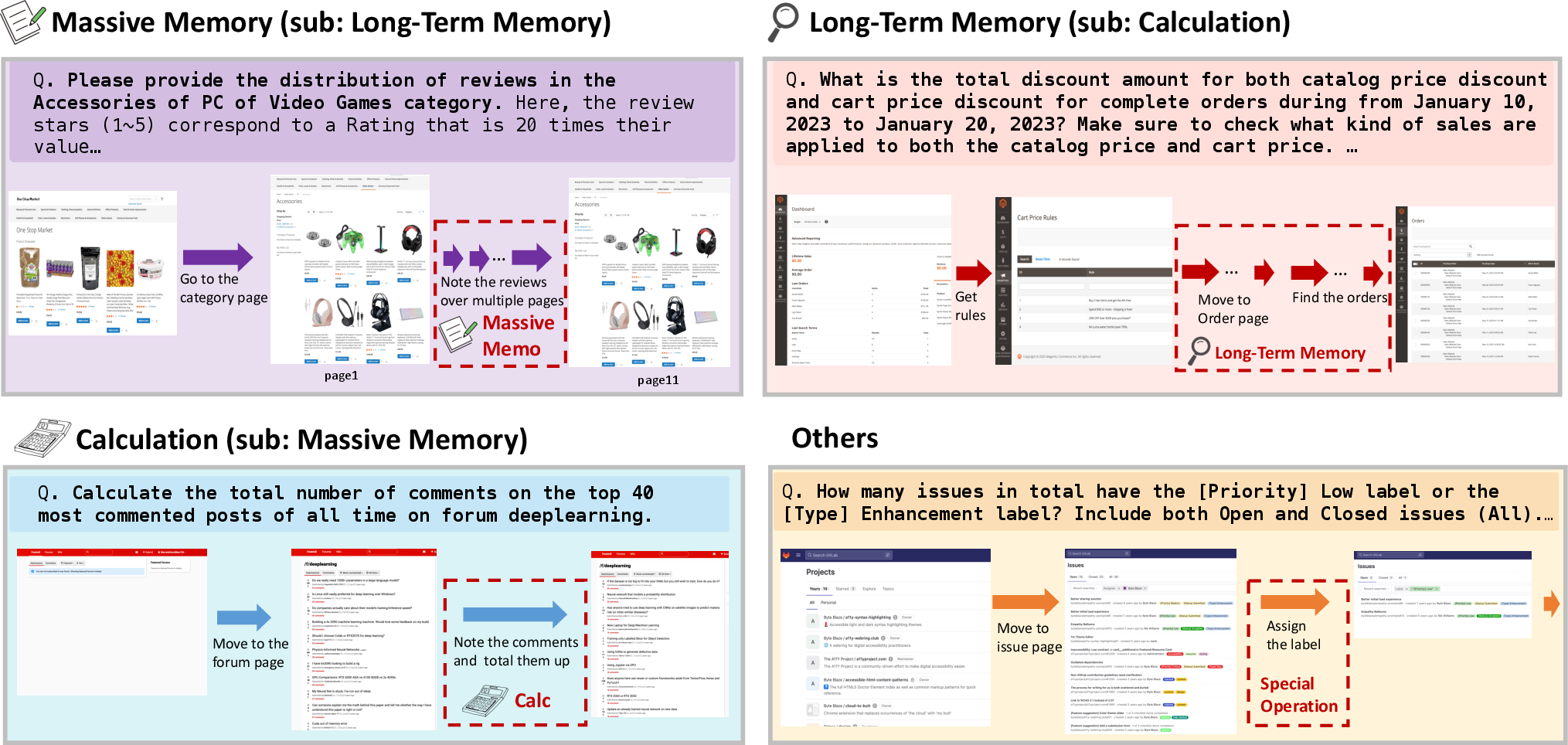
Figure 2: Examples in each task type in WebChoreArena. (i) Massive Memory tasks require accurately memorizing a large amount of information from the given page. (ii) Calculation tasks involve performing arithmetic operations. (iii) Long-Term Memory tasks require the agent to retain relevant information across many steps and interactions. (iv) Others involve tasks that require special or domain-specific operations.
The evaluation protocol involves metrics such as string_match for textual output evaluation, url_match for URL verification, and program_html for functional web interaction assessment, ensuring thorough and reliable performance assessment across varied task scenarios.
The performance of three prominent LLMs—GPT-4o, Claude 3.7 Sonnet, and Gemini 2.5 Pro—was evaluated on WebChoreArena using BrowserGym and AgentOccam, two state-of-the-art web agents. The results indicate substantial performance gaps with agents achieving far lower accuracy rates on WebChoreArena compared to WebArena, highlighting the increased complexity of tasks presented in the new benchmark.
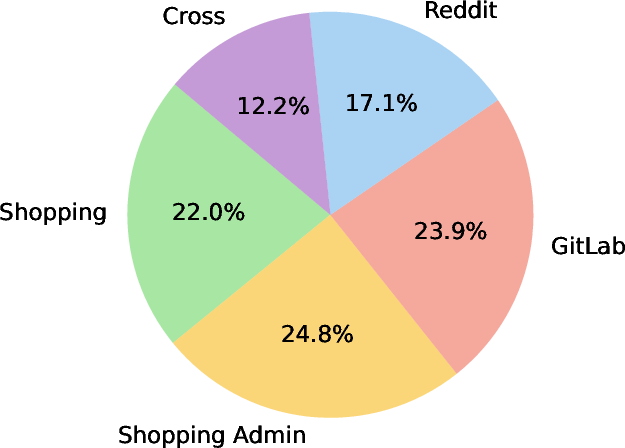
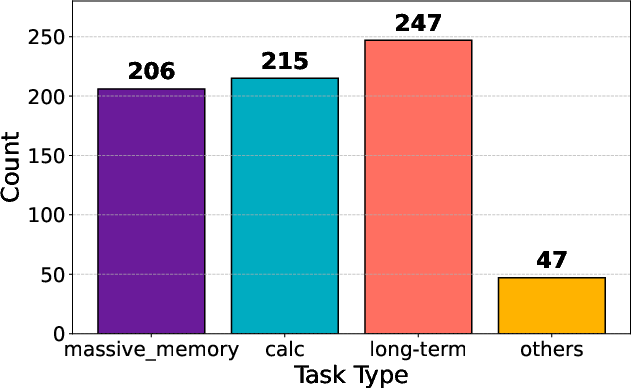
Figure 3: Distribution of websites and task types in WebChoreArena.
Specifically, performance analysis shows that GPT-4o achieved dramatically reduced accuracy on WebChoreArena tasks, demonstrating the benchmark’s effectiveness in distinguishing between capabilities of older and newer models.
Memory Utilization and Operational Strategies
The configurations for BrowserGym and AgentOccam showcase their differences in memory management. BrowserGym utilizes explicit memory storage at each step, while AgentOccam employs summarized input that requires explicit note-taking actions for memory retention. This discrepancy explains the variance in agent performances on memory-intensive tasks.
Future Directions and Conclusion
WebChoreArena offers significant implications for the future of web browsing agent development, emphasizing the need for improved methodologies that can tackle complex, memory-intensive, and calculative challenges. The benchmark provides a robust platform for testing LLM advancements and accentuates areas requiring improvement such as reducing visual hallucinations and improving operational efficiency during tool utilization.
In conclusion, WebChoreArena stands as a pivotal benchmark for evaluating advancements in web agent capabilities, challenging existing models with high task difficulty and revealing current limitations in even the most advanced LLM-based agents. Future work should focus on refining agent architectures to leverage visual inputs effectively and designing novel strategies for memory and calculation-intensive tasks to improve overall performance.

