- The paper introduces a deep latent variable model for zero-shot Chinese character recognition by automatically decomposing characters into compositional latent components.
- It employs an ELBO framework that optimizes reconstruction and prediction, achieving a 47% accuracy improvement on HWDB zero-shot tests.
- The method demonstrates robust cross-dataset generalization, making it applicable in historical script analysis and future character recognition tasks.
CoLa: Chinese Character Decomposition with Compositional Latent Components
Introduction
The paper "CoLa: Chinese Character Decomposition with Compositional Latent Components" (2506.03798) introduces a novel approach to Chinese character recognition (CCR) leveraging the cognitive principles of compositionality and learning-to-learn. Traditional methods often rely on predefined radical or stroke decomposition, which can limit generalization to novel characters. Instead, CoLa uses deep latent variable models to learn compositional latent components directly from data, bypassing human-defined decomposition schemes.
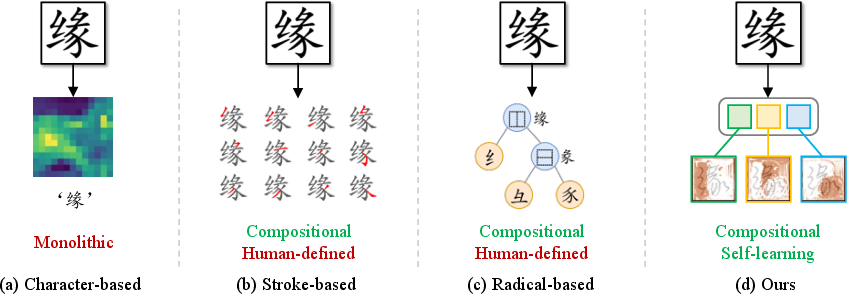
Figure 1: Different types of Chinese character recognition methods explored, highlighting CoLa's approach of automatic decomposition.
Methodology
CoLa employs a deep latent variable model to decompose characters into compositional latent components within a latent space. This model supports zero-shot recognition by comparing these latent components from input characters with those from template images. Unlike previous methods that are constrained by predefined decomposition rules, CoLa automatically learns to decompose characters by reconstructing visual features derived from a pretrained teacher encoder, aligning components in an interpretable manner.
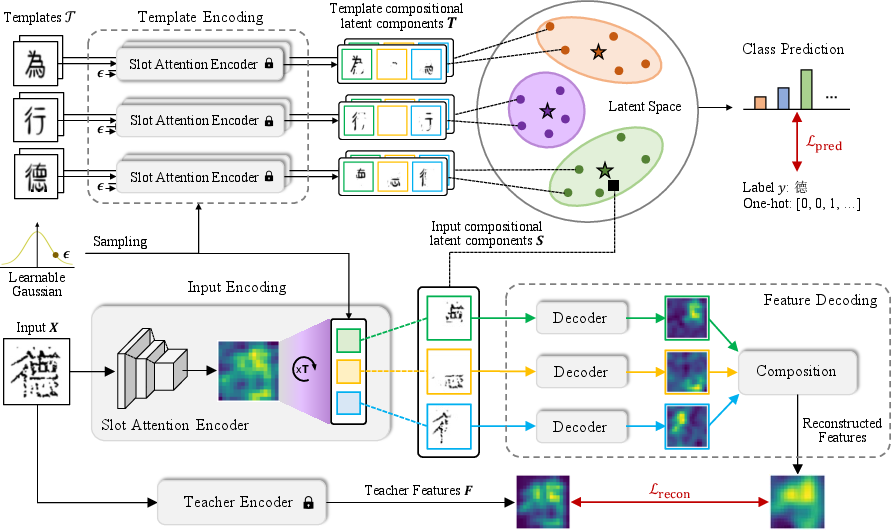
Figure 2: The generative process of CoLa, showing extraction, decoding, and prediction mechanisms.
The model's probabilistic framework involves an evidence lower bound (ELBO) that combines reconstruction, prediction, and regularization terms to optimize performance. Effective recognition is achieved by minimizing the reconstruction error and maximizing the likelihood of correct class prediction. CoLa's design inherently supports permutations in component order, allowing flexibility in how decomposition is approached.
Experimental Results
CoLa's performance was evaluated on multiple datasets, including handwritten (HWDB) and printed Chinese characters, as well as historical documents. Significant improvements were observed in zero-shot settings, with the model achieving superior accuracy over existing radical and stroke-based methods. For instance, CoLa improved recognition accuracy by approximately 47% in character zero-shot settings on HWDB.
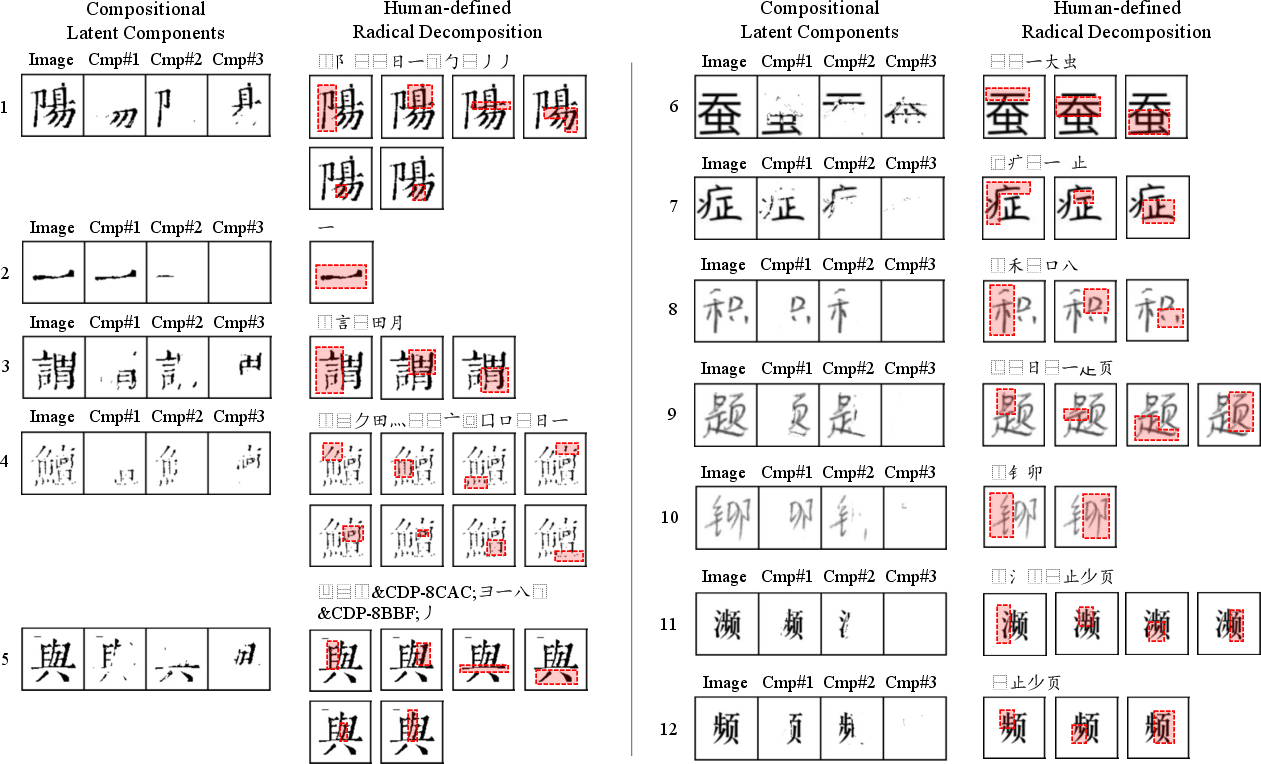
Figure 3: Visualization of compositional latent components, comparing these to human-defined radical decompositions.
Furthermore, CoLa has demonstrated robust cross-dataset generalization capabilities, analyzing characters from oracle bone scripts without retraining on these significantly different scripts. This highlights its potential applicability in historical script analysis, demonstrating a profound capacity for component recognition across diverse datasets.
Implications and Future Work
CoLa represents a significant advancement in the field of CCR by circumventing the limitations of human-defined decomposition schemes. The ability to automatically discover and utilize compositional latent components opens new avenues for applications across domain recognition tasks. However, future work should address CoLa's performance in complex scene images where background noise and resolution variability could affect decomposition accuracy.
Conclusion
"CoLa: Chinese Character Decomposition with Compositional Latent Components" (2506.03798) provides a compelling approach to zero-shot Chinese character recognition by leveraging a deep latent variable framework to learn decompositional structures. This method not only surpasses traditional approaches in performance but also extends the possibility of cross-dataset applications, particularly in historical contexts. These findings pave the way for further innovation in character recognition and similar fields requiring nuanced component-based interpretation.