- The paper introduces Conformer-based deep learning models that convert ultrasound tongue images to mel spectrograms, showing competitive performance against traditional methods.
- It employs both a standalone Conformer Base and a Conformer with bi-LSTM to capture local and global dependencies, enhancing training efficiency and model robustness.
- Subjective evaluations using MUSHRA tests indicate that the Conformer with bi-LSTM improves perceptual naturalness, making it promising for real-time silent speech applications.
Introduction to Silent Speech Interfaces
Silent Speech Interfaces (SSI) are pivotal in scenarios where audible speech production is either impractical or undesirable, such as in cases of speech disorders or certain environmental conditions. SSIs aim to bridge the gap between articulatory movements and speech recognition or reconstruction, thus enabling communication without vocalization. Various modalities have been explored to capture these articulatory movements, including surface electromyography, magnetic resonance imaging, lip videos, and notably, ultrasound tongue imaging (UTI). UTI offers detailed insights into tongue movement, crucial for speech production, while being non-invasive and cost-effective.
Ultrasound-to-Speech Conversion Approach
Ultrasound-to-speech conversion workflows typically consist of mapping ultrasound tongue image frames (UTIF) to intermediate speech signal representations, such as mel spectrograms, followed by synthesizing speech from these representations using a vocoder. This workflow relies heavily on deep neural network (DNN) architectures to effectively transform UTIF to the desired intermediate form.
The current research introduces the application of Conformer-based DNN architectures to enhance the UTIF-to-mel mapping task. Traditional approaches have utilized CNNs and LSTM networks for this purpose. The Conformer, a convolution-augmented transformer, merges the benefits of global interaction capture from transformers with local feature extraction proficiency of CNNs. Its parameter efficiency and ability to learn local and global dependencies make it suitable for tasks requiring sequence data processing.
Figure 1: Schematic diagram of the ultrasound-to-speech system pipeline, showing the Conformer-based ultrasound-to-mel mapping and the HiFi-GAN vocoder for speech synthesis.
Methodology
The study employs two Conformer-based architectures: the Conformer Base and the Conformer with bi-LSTM. Both models were trained on speaker-specific data from the UltraSuite-Tal80 dataset, encompassing four distinct speakers.
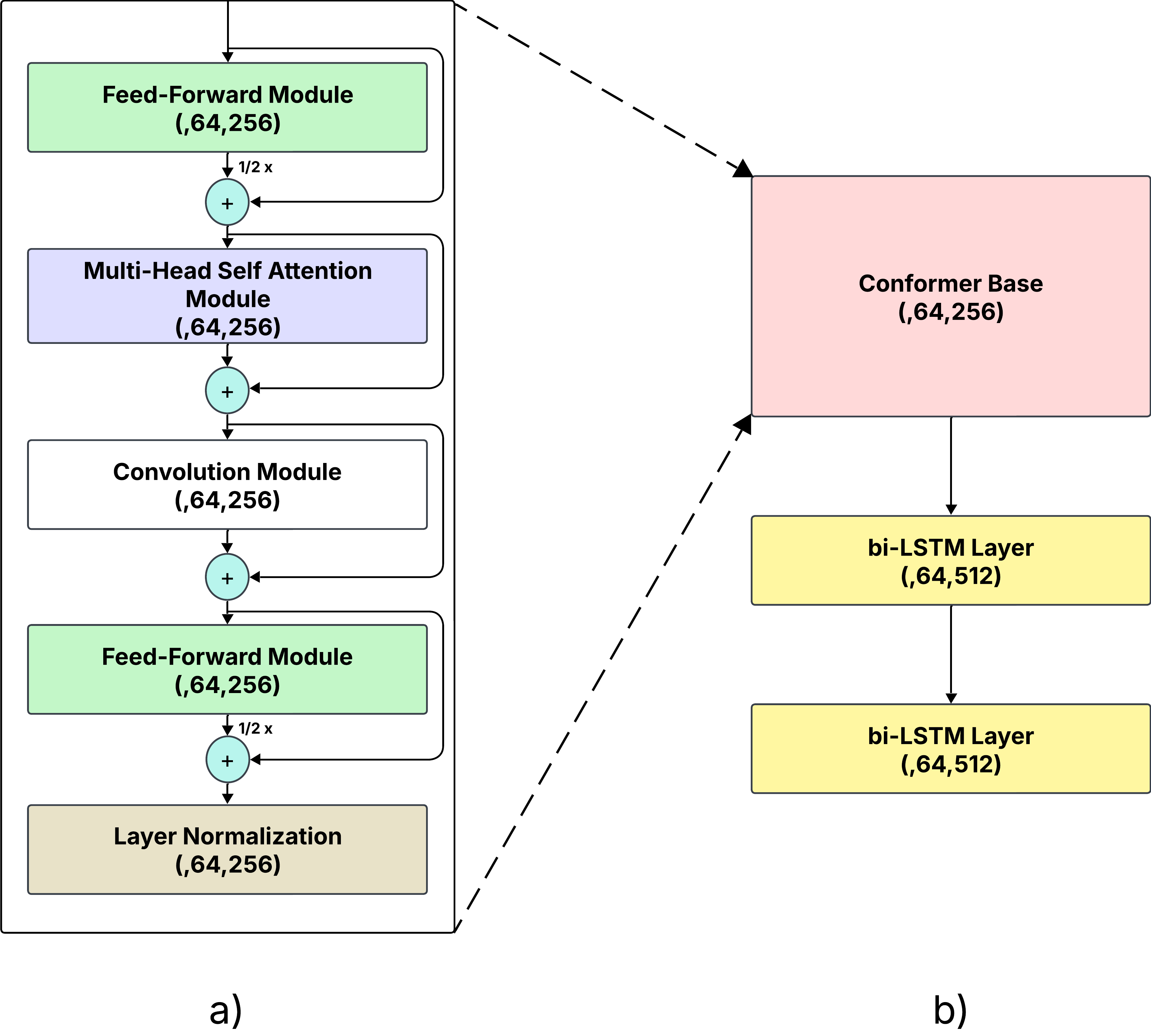
Figure 2: a) Conformer Base; b) Conformer with bi-LSTM (output shape of each layer is mentioned in parentheses).
The Conformer Base implements a sandwich-like structure around the Conformer block, configured to process ultrasound inputs and produce mel spectrograms. It operates with an efficient architectural configuration that minimizes training time compared to traditional CNN approaches.
Inspired by successful implementations in biosignal-based accelerometer-to-speech synthesis tasks, this architecture integrates bi-LSTM layers with Conformer blocks, leveraging their ability to handle sequence data by accessing temporal contexts both forward and backward. This hybrid approach is hypothesized to improve performance and naturalness of synthesized speech.
Results and Evaluations
Objective Metrics
The study evaluates models using Mean Squared Error (MSE) and Mel-Cepstral Distortion (MCD) metrics. Both metrics are crucial for assessing the fidelity and accuracy of the synthesized speech against the original recordings.
- MSE Results: The Conformer with bi-LSTM exhibited comparable effectiveness to traditional methods. However, the Conformer Base showed significant statistical differences in specific cases.
(Table 1)
Table 1: Mean Squared Error results on the test set for each speaker.
- MCD Results: MCD measurements highlighted a speaker-dependent performance variation, suggesting variability in ultrasound data quality across individuals.
(Table 2)
Table 2: Mel-Cepstral Distortion values (dB) on the test set per speaker.
Subjective Evaluations
A MUSHRA listening test provided insights into the perceived naturalness of the synthesized speech. Results indicated a preference for the Conformer with bi-LSTM model over others, suggesting marginally better perceptual quality despite similar objective metrics.
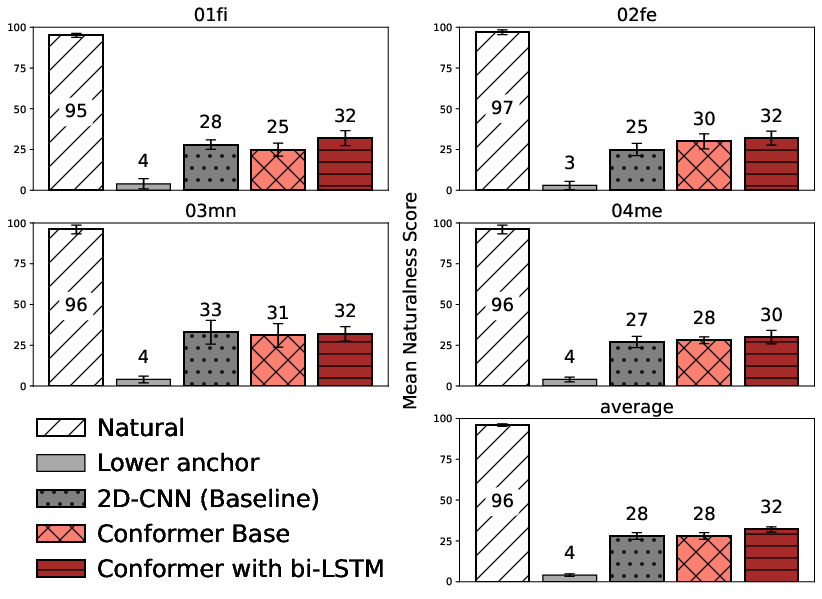
Figure 3: Results of the MUSHRA listening test with respect to naturalness, speaker by speaker (first two rows) and on average (bottom-right corner).
Conclusions
This research underscores the potential of Conformer-based architectures in improving SSI performance, particularly for ultrasound-to-speech tasks. The Conformer with bi-LSTM architecture, owing to its superior training efficiency and promising subjective results, emerges as a viable enhancement over traditional models. While objective differences were minimal, subjective evaluations suggest improved naturalness, which is critical for real-time applications.
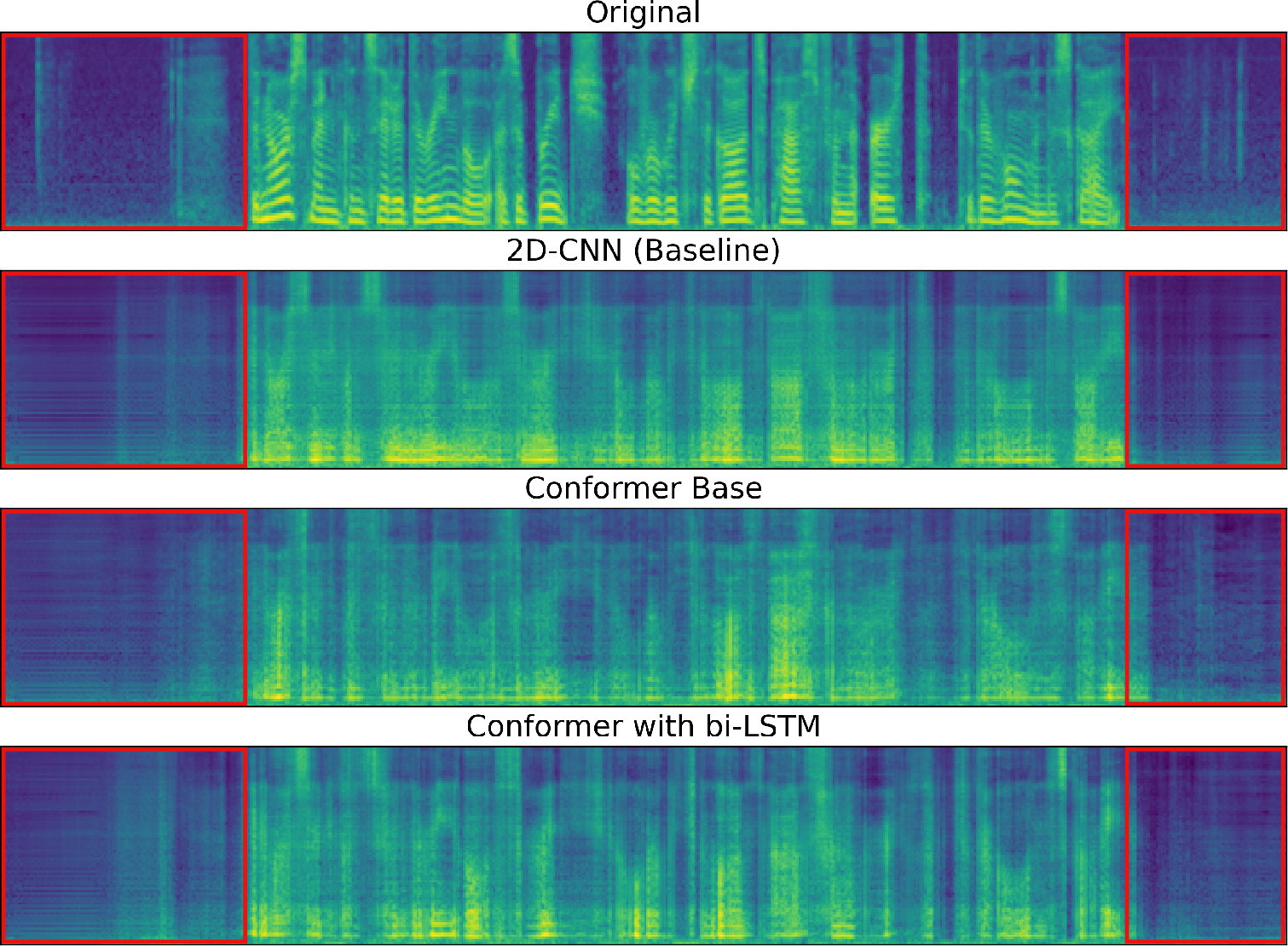
Figure 4: Mel spectrogram representation of synthesized samples using proposed and baseline ultrasound-to-speech system, in comparison to original form ("014_xaud" utterance by speaker "01fi").
Future work should focus on further refining these models to optimize silent segment generation and explore broader applications in SSI, leveraging these advancements for comprehensive speech synthesis solutions. The complete code and synthesized samples are available at Zenodo.