Rex-Thinker: Grounded Object Referring via Chain-of-Thought Reasoning
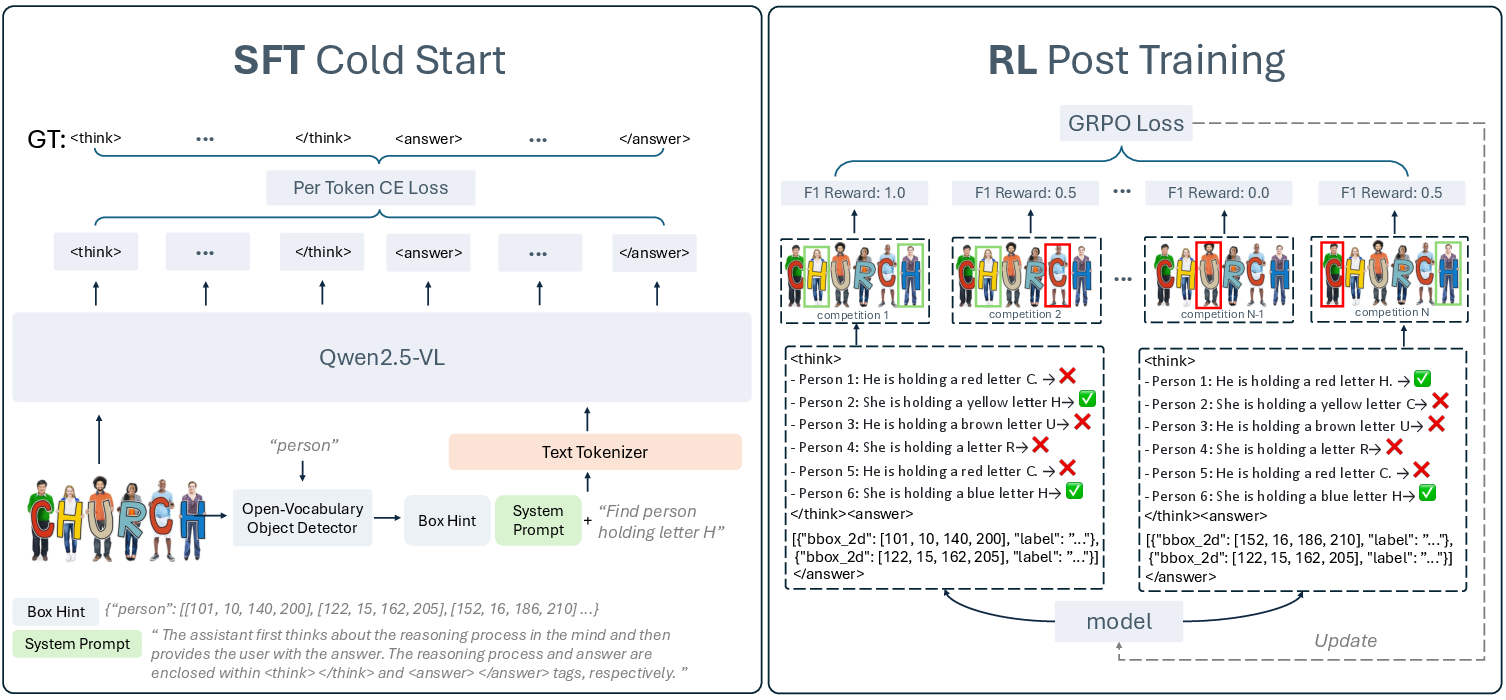
Abstract: Object referring aims to detect all objects in an image that match a given natural language description. We argue that a robust object referring model should be grounded, meaning its predictions should be both explainable and faithful to the visual content. Specifically, it should satisfy two key properties: 1) Verifiable, by producing interpretable reasoning that justifies its predictions and clearly links them to visual evidence; and 2) Trustworthy, by learning to abstain when no object in the image satisfies the given expression. However, most methods treat referring as a direct bounding box prediction task, offering limited interpretability and struggling to reject expressions with no matching object. In this work, we propose Rex-Thinker, a model that formulates object referring as an explicit CoT reasoning task. Given a referring expression, we first identify all candidate object instances corresponding to the referred object category. Rex-Thinker then performs step-by-step reasoning over each candidate to assess whether it matches the given expression, before making a final prediction. To support this paradigm, we construct a large-scale CoT-style referring dataset named HumanRef-CoT by prompting GPT-4o on the HumanRef dataset. Each reasoning trace follows a structured planning, action, and summarization format, enabling the model to learn decomposed, interpretable reasoning over object candidates. We then train Rex-Thinker in two stages: a cold-start supervised fine-tuning phase to teach the model how to perform structured reasoning, followed by GRPO-based RL learning to improve accuracy and generalization. Experiments show that our approach outperforms standard baselines in both precision and interpretability on in-domain evaluation, while also demonstrating improved ability to reject hallucinated outputs and strong generalization in out-of-domain settings.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.