- The paper introduces a self-evolving framework for LLM agents, achieving a 95% improvement in average victory points through the PromptEvolver architecture.
- It compares multiple agent architectures from basic action mapping to autonomous code rewriting, revealing challenges in strategic coherence with advanced models.
- The study highlights the potential and limitations of self-improving LLMs in partially observable environments, guiding future research in hybrid AI reasoning.
Self-Evolving LLM Agents for Strategic Planning in Settlers of Catan
The paper "Agents of Change: Self-Evolving LLM Agents for Strategic Planning" explores the enhancement of strategic planning in LLM agents through a novel self-improvement framework. By leveraging the open-source Catanatron framework, the researchers benchmarked various LLM-based agent architectures capable of autonomously refining their gaming strategies in the complex environment of Settlers of Catan. This analysis aims to assess how effectively LLMs can self-evolve and improve long-term strategic gameplay.
Agent Architectures and Methodology
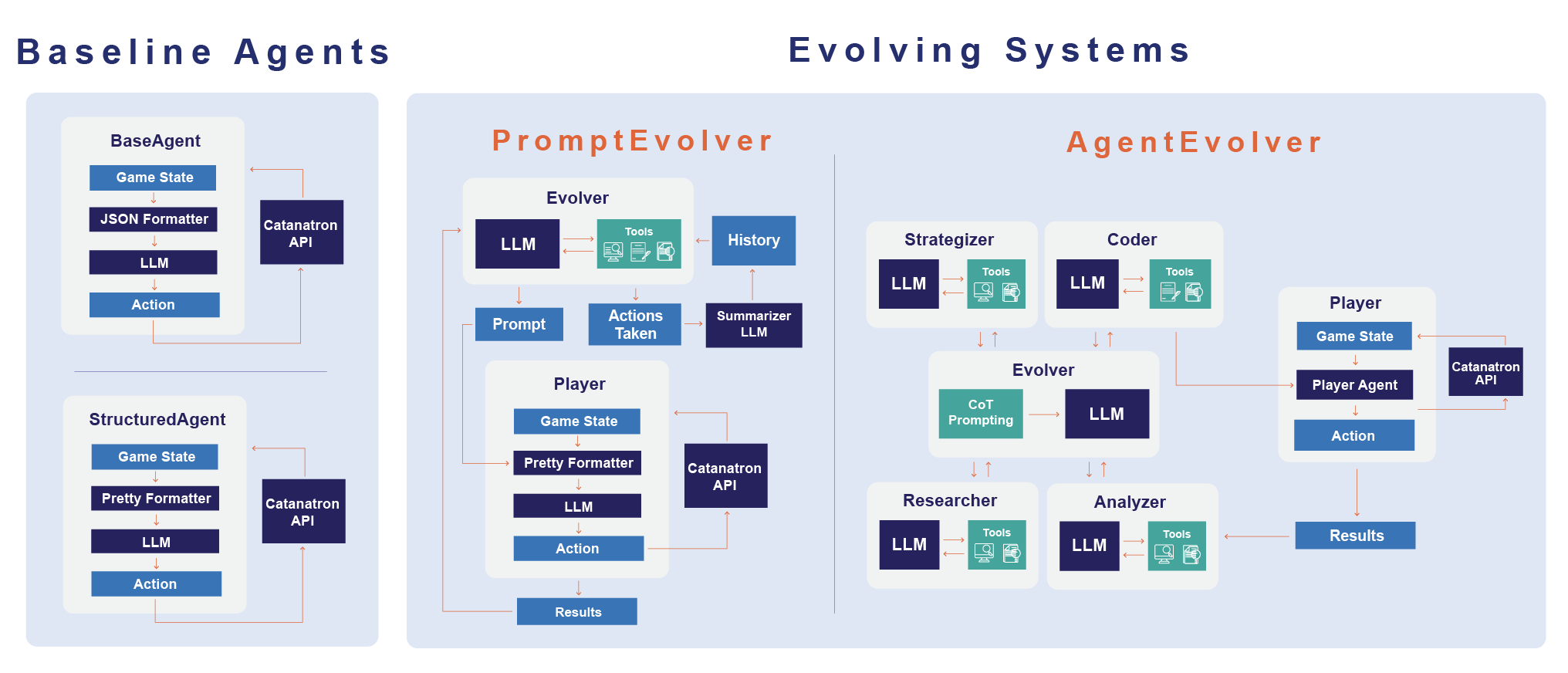
The study introduces several agent architectures, each with progressively more advanced self-improvement capabilities. It explores a direct LLM-to-action mapping (BaseAgent), human-prompt engineering (StructuredAgent), prompt iteration (PromptEvolver), and autonomous code rewriting (AgentEvolver). The research investigates whether multi-agent collaborative frameworks, drawing inspiration from AI models like AutoGPT and Reflexion, can autonomously enhance strategic planning in partially observable environments like Catan.
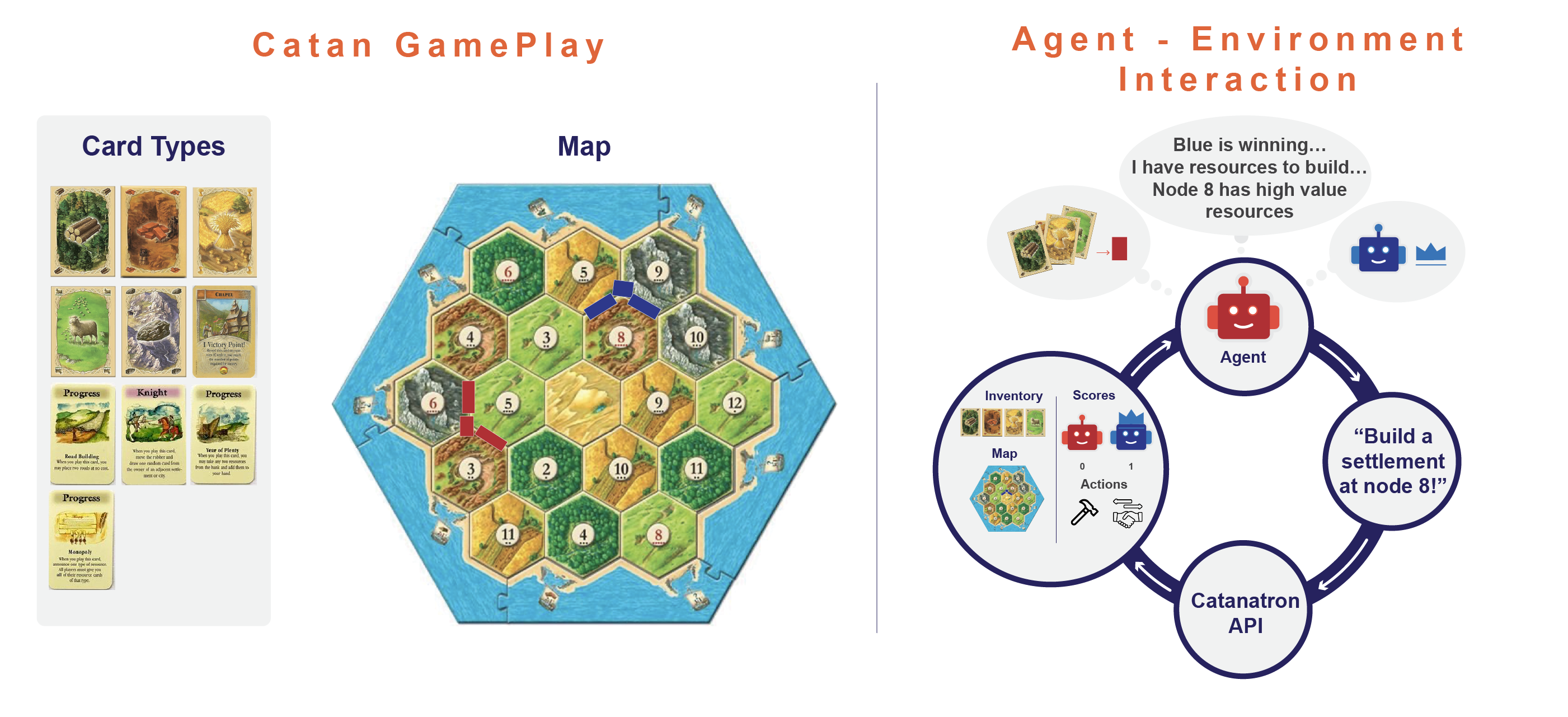
Figure 1: Overview of Catan gameplay and LLM-agent interaction.
These LLM-driven agents utilize structured game state representations to inform turn-by-turn decisions. The evaluation focuses on the agents' ability to outperform a heuristic-based bot, AlphaBeta, measuring metrics such as average victory points and strategic milestones like longest road and largest army.
Key Findings
The experiments highlight several significant findings regarding the capabilities and limitations of self-evolving LLM agents:
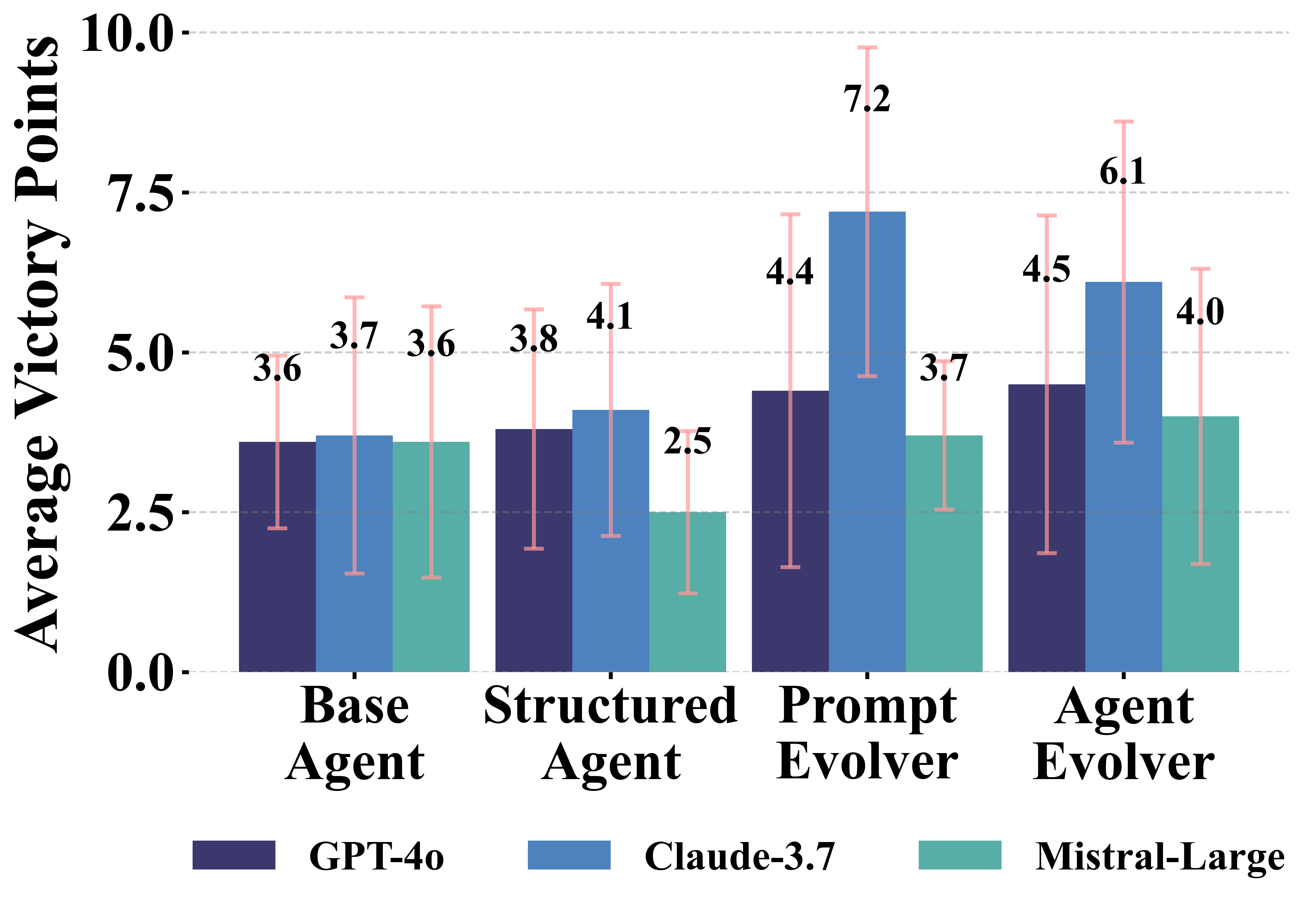
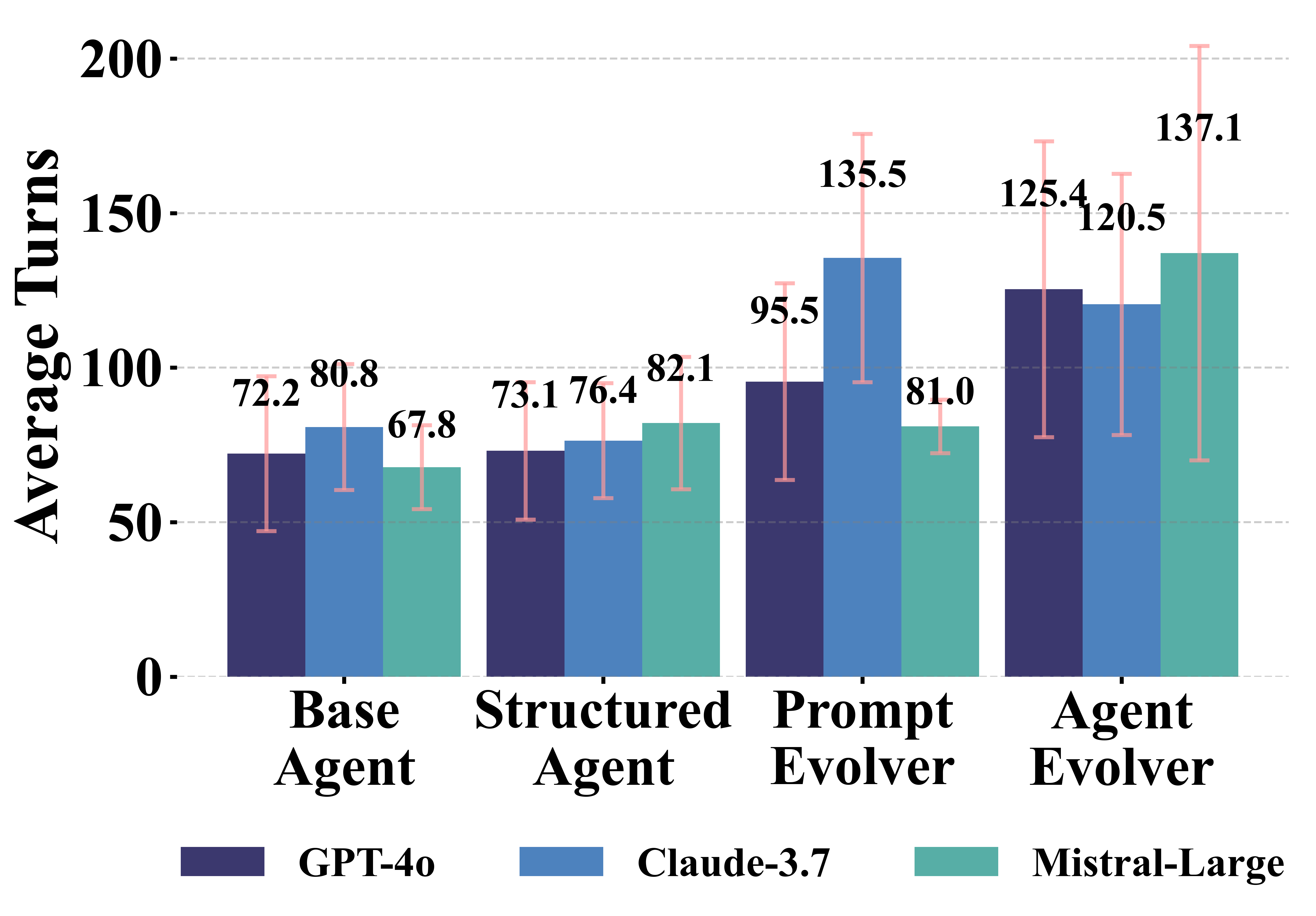
Figure 3: Average Game Length.
Discussion of Evolutionary Processes
PromptEvolver Architecture
The PromptEvolver's success varied significantly across different models. While Claude 3.7 showed remarkable strategic improvement, Mistral Large struggled to effectively leverage self-improvement capabilities, demonstrating the dependency of agent performance on the LLM's inherent strategic reasoning capability.
AgentEvolver Challenges
The AgentEvolver architecture, although demonstrating the potential for autonomous code generation, faced limitations with strategic coherence and more complex gameplay dynamics. The models showed promising results in self-directed learning and interfacing with the Catanatron framework, suggesting potential in exploring similar evolutionary architectures in other strategic contexts.
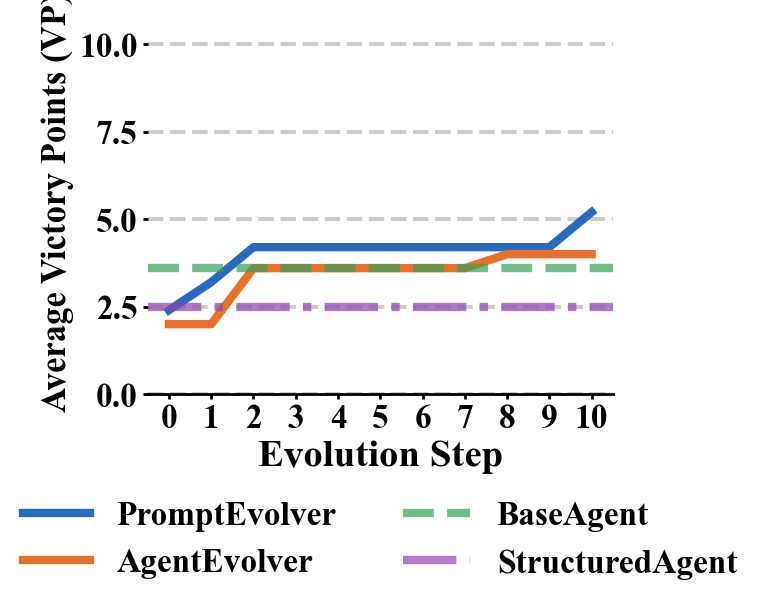
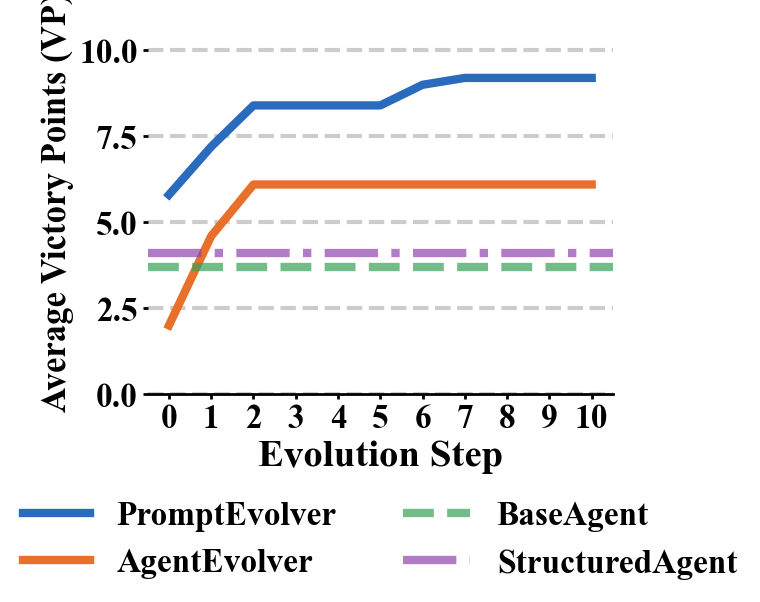
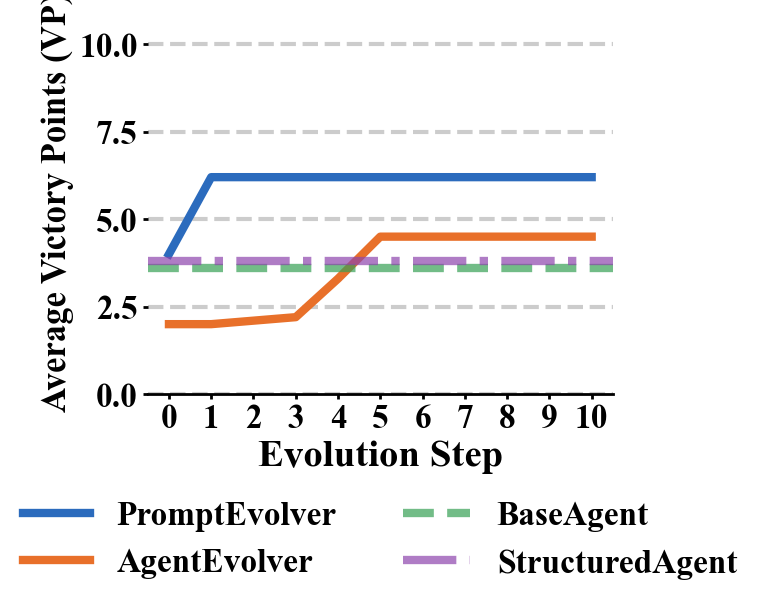
Figure 4: Mistral Large.
Limitations and Further Research
Several limitations persist in this research, including high computational costs and restricted generalization to other environments. The approach also reveals limitations tied to the base model's strategic reasoning ability. Continued exploration into reinforcement learning baselines and hybrid architectures combining symbolic and neural reasoning could yield advancements in autonomous strategic planning.
Conclusion
This study demonstrates the growing potential of LLMs to develop strategic capabilities autonomously, expanding their role from passive task execution to active self-improvement and strategic design. The findings underscore the emergent nature of LLMs in complex decision-making tasks, showcasing their potential to refine long-term strategies with minimal human intervention. Future research should explore enhanced generalization, improved integration of symbolic reasoning, and expansion to broader strategic environments.
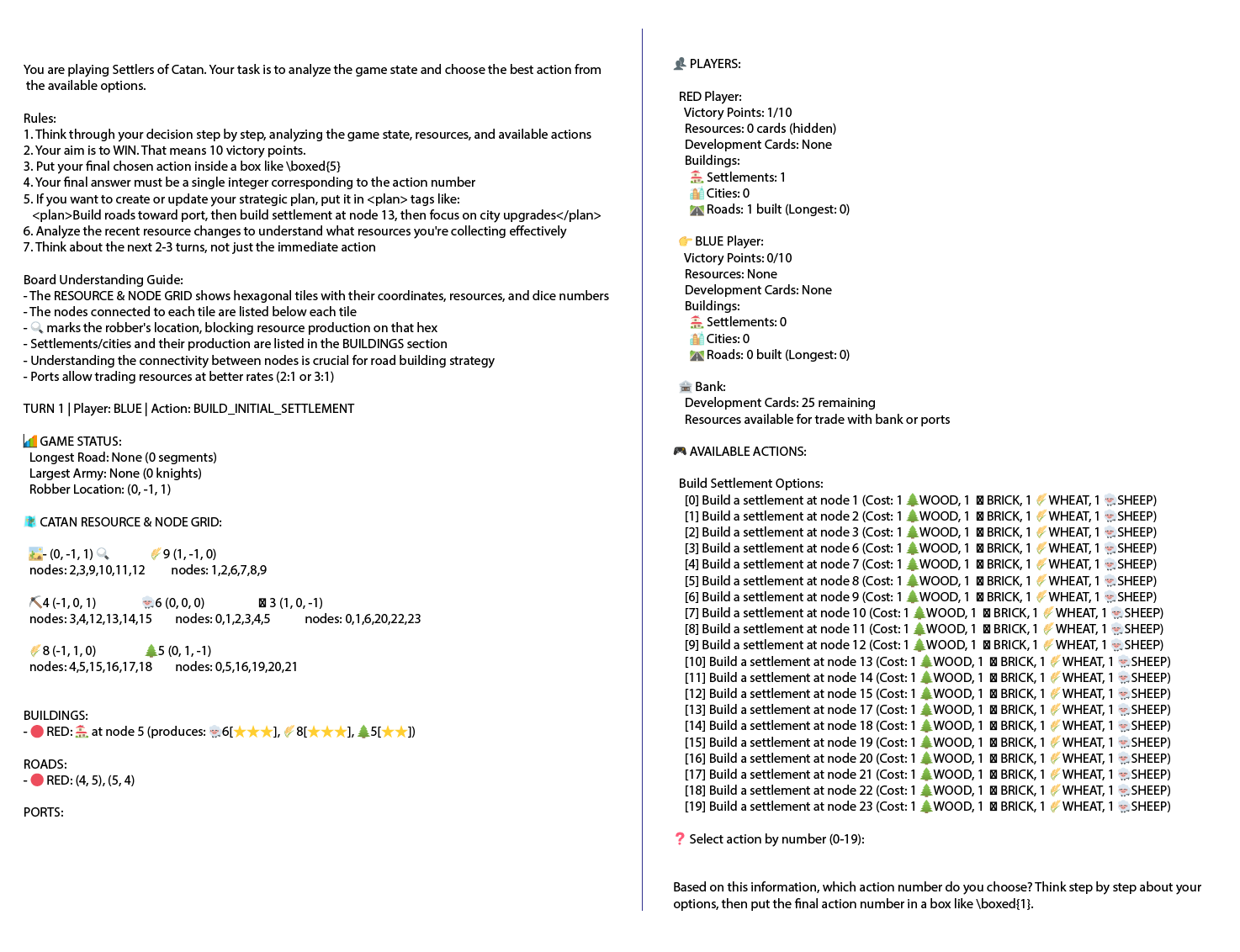
Figure 5: Sample StructuredAgent LLM prompt.