- The paper establishes OpenGT, a benchmark that integrates 16 diverse GT and GNN models to systematically evaluate performance and efficiency across varied graph tasks.
- The paper demonstrates that hybrid and global attention mechanisms excel in heterophilous settings and that partition-based methods offer favorable efficiency-accuracy tradeoffs.
- The paper highlights the critical role of adaptive positional encodings, showing that encoding choices must be matched to graph characteristics to balance accuracy and computational cost.
Introduction
Graph Transformers (GTs) have emerged as competitive alternatives to traditional Graph Neural Networks (GNNs) in diverse graph learning tasks, leveraging attention mechanisms for global context modeling and expanded structural expressiveness. However, the proliferation of architectural variants—varying in positional encodings, attention designs, and hybridization strategies—has fragmented the empirical landscape, hindering systematic assessment. The "OpenGT: A Comprehensive Benchmark For Graph Transformers" (2506.04765) paper introduces an open-source benchmark and library designed to standardize the evaluation of GTs, facilitating rigorous, multidimensional comparison and fostering reproducibility across node-level and graph-level tasks. OpenGT addresses open questions about the architectural and algorithmic tradeoffs in GTs by integrating a wide and representative array of models and datasets, presenting a unified platform for empirical analysis and future model development.
The evolution of Graph Transformers is schematically summarized in a comprehensive timeline, stratifying major innovations by their advances in attention mechanisms, positional encodings, and structural adaptations.
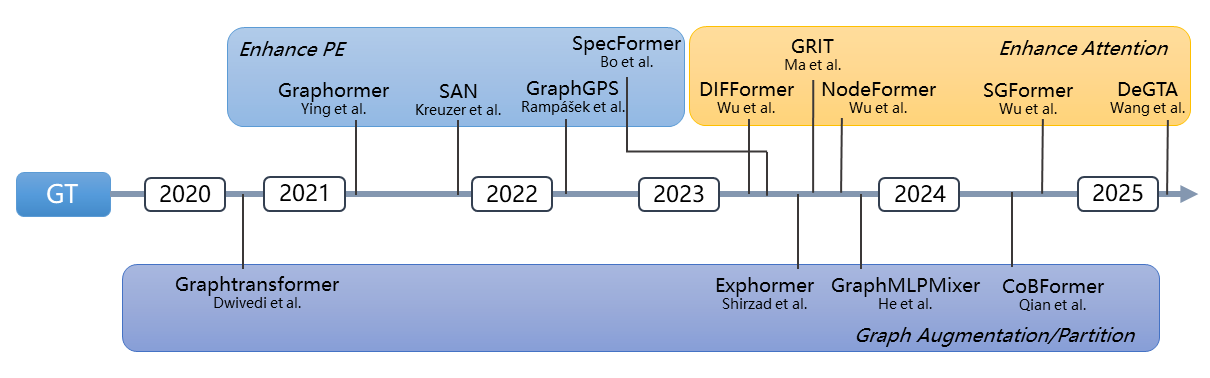
Figure 1: Timeline of key improvements in Graph Transformer architectures, highlighting the introduction of new attention and positional encoding designs.
Benchmark Design and Methodology
OpenGT implements 16 prominent GTs and GNNs within a modular, configuration-driven pipeline based on torch_geometric.graphgym, ensuring consistent code bases and training regimes. The benchmark encompasses datasets capturing a spectrum of graph characteristics—size, homophily/heterophily, and sparsity. Tasks include node classification (Cora, Citeseer, Pubmed, Squirrel, Chameleon, etc.) and graph-level property prediction (e.g., ZINC regression, OGBG-MolHIV/OGBG-MolPCBA classification, Peptides-func/struct).
The evaluation framework systematically investigates:
- Relative effectiveness of GTs versus message-passing GNNs
- Impact of local, global, and hybrid attention mechanisms
- Efficiency-accuracy tradeoffs, including computational bottlenecks
- Role and scalability of positional encodings (spatial, spectral, random walk, etc.)
By standardizing experimental conditions (identical splits, batching, hyperparameter sweeps, etc.), OpenGT minimizes experimental confounds, enabling robust cross-architecture and cross-task analysis.
Empirical Analysis and Key Insights
OpenGT reveals that GTs are particularly advantageous on heterophilous graphs (e.g., Chameleon, Squirrel): attention-based models significantly outperform baseline message-passing GNNs under sparsity and weak neighborhood signal. However, on homophilous benchmarks, vanilla GNNs retain competitive accuracy, and the performance variance across GTs widens due to hardware bottlenecks and suboptimal architectural choices. This demonstrates that current GTs yield maximal benefit where local message passing is fundamentally insufficient or where relational patterns are not locally clustered.
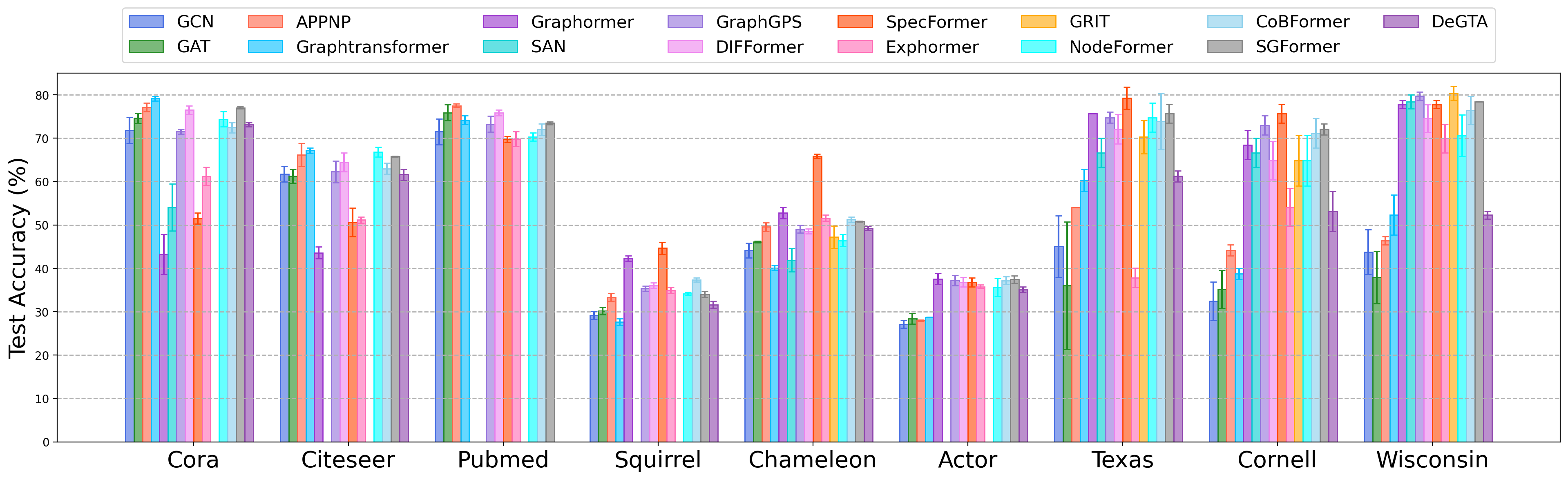
Figure 2: Comparative performance of GTs and GNNs on node-level benchmarks, indicating strong GT gains on heterophilous data.
For graph-level prediction, only GTs architected specifically for this regime (e.g., GraphGPS+RWSE, GRIT) convincingly outperform GNNs. Node-level optimized GTs do not generalize robustly, with ablation showing poor cross-task transfer—contrary to what is typically observed in NLP or CV Transformer use. This indicates significant need for further research on architecture modularity, integrating explicit readout or pooling modules for multi-granularity generalization.
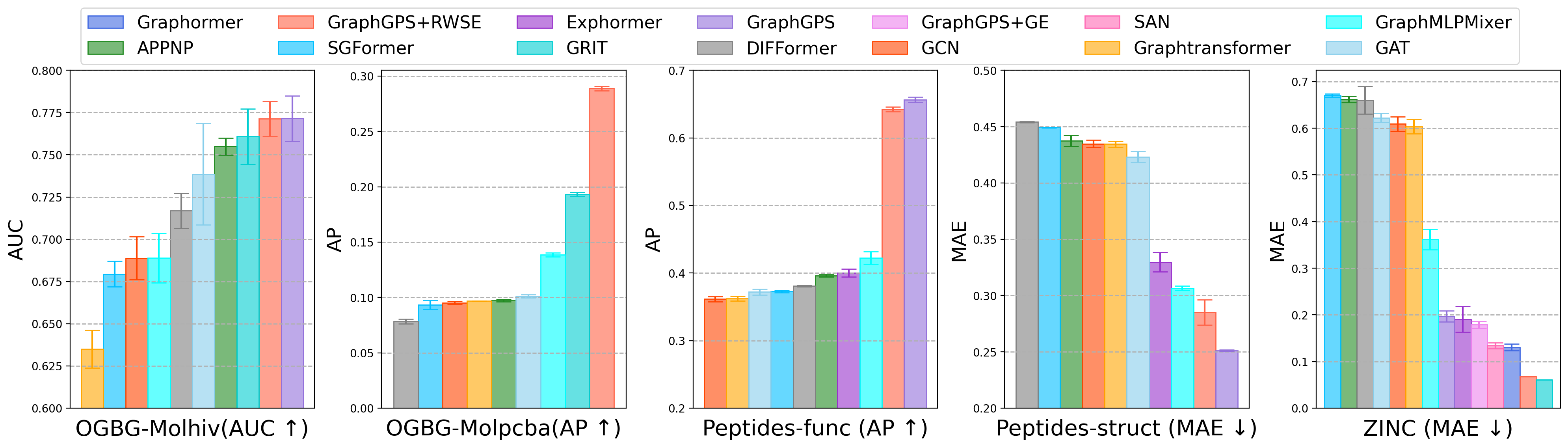
Figure 3: Graph-level performance, highlighting the dominance of position-aware and hybrid GTs over GNNs in diverse chemical and biological prediction tasks.
Attention Mechanisms: Local, Global, and Hybrid Scope
Models with purely local attention (e.g., Graphtransformer, DeGTA) degrade rapidly in sparse, heterophilous scenarios: their constrained receptive field fails to propagate long-range graph context, mirroring GNN oversmoothing limitations. In contrast, global or hybrid attention (e.g., Graphormer, GraphGPS, SGFormer) preserves performance across graph types, albeit with greater computational cost. This motivates ongoing research in scalable, adaptively-applied attention and partitioning strategies.
Efficiency-Accuracy Tradeoff
The quadratic complexity of fully-connected attention impedes large-scale deployment of several GTs. Models employing partition-based attention (CoBFormer, GraphMLPMixer) strike a highly favorable efficiency-effectiveness balance: by hierarchically dividing the graph and concentrating computation within and between partitions, they approach full-attention accuracy at a fraction of the cost, as confirmed in time-to-convergence benchmarking.
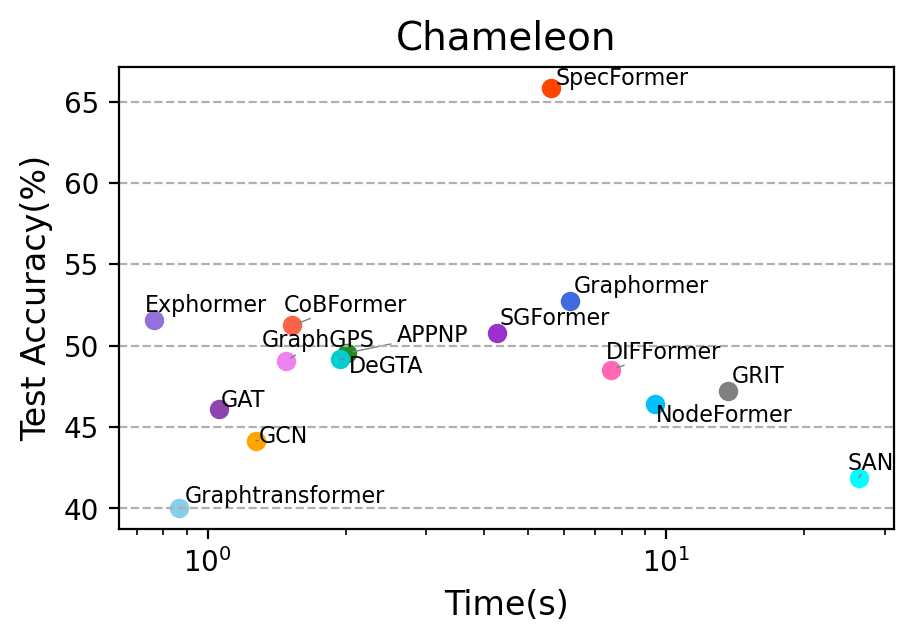
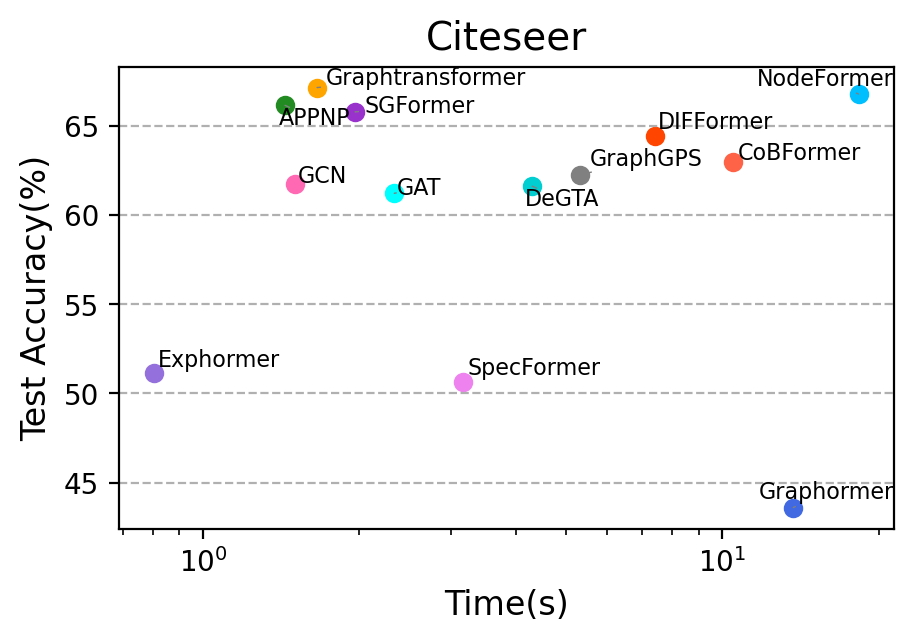
Figure 4: Time versus accuracy tradeoff on representative datasets (Chameleon, Citeseer), illustrating that partitioned-attention GTs (e.g., CoBFormer) achieve competitive accuracy at much lower computational cost than full-attention architectures.
Positional Encoding: Algorithmic Impact and Overhead
Degree-based and simplified spatial encodings (Graphormer GE/GESP) provide substantial accuracy boosts in dense graphs while minimizing computational overhead. Sophisticated encodings (spectral, random walk, all-pairs shortest paths) can further enhance accuracy, but at a prohibitive preprocessing cost—often dwarfing the training time (e.g., spectral decomposition or all-pairs shortest-path computation on Pubmed exceeds one hour). Empirically, encoding choices must be dynamically matched to graph scale and structure to avoid infeasibility. This necessitates new research in approximating or learning position information efficiently, and in constructing configuration pipelines that adapt encoding choice on a per-dataset basis.
(Figure 5)
Figure 5: Sensitivity of node classification accuracy to positional encoding variants across models and datasets. Degree-based encodings are efficient and effective in high-degree graphs; spectral and random-walk encodings incur heavy preprocessing but can benefit structural generalization in some regimes.
Theoretical and Practical Implications
The findings of OpenGT underscore the following implications for future GT research:
- No GT design is universally optimal: Effectiveness depends jointly on graph density, homophily, and task type. Benchmarking must include both node-level and graph-level tasks and account for hardware-feasible scalability.
- Architectural transferability across prediction granularity remains elusive: Unlike text/image Transformers, GTs designed for node-level tasks seldom transfer to graph-level prediction without explicit architectural adaptation. Modular, task-adapted GTs that disentangle local/global processing and optimize pooling/readout are an open area.
- Scalable, adaptive attention and positional encoding remain rate-limiting factors: Future GTs must combine partition-based architectures, efficient hybrid attention, and dynamically selected or learnable positional encodings to balance expressivity and resource constraints.
- Reproducible, easy-to-use benchmarking is essential for progress: OpenGT allows repeated, fair comparisons and rapid prototyping of future architectural innovations.
The prospect of a graph foundation model in analogy to vision and language is outlined but will require substantial advances on all these fronts to materialize.
Conclusion
OpenGT establishes a rigorous and extensible regime for the empirical study of Graph Transformers. By revealing the nuanced interplay between model design, dataset structure, and task requirements, this benchmark provides actionable guidance for practitioners and clear targets for future research in efficient graph representation learning. Its insights and open library set an effective standard for subsequent developments in the field.