- The paper introduces PM-Loss, a novel regularization term that integrates pretrained pointmap priors to reduce depth-induced artifacts in feed-forward 3D Gaussian splatting.
- It refines geometric consistency by aligning Gaussian centers through efficient closed-form Umeyama alignment combined with a single-direction Chamfer loss.
- Experimental results across datasets show significant improvements in PSNR, boundary reconstruction, and geometric accuracy, validating the method’s effectiveness.
Revisiting Depth Representations for Feed-Forward 3D Gaussian Splatting: A Technical Summary
Problem Statement and Motivation
Feed-forward 3D Gaussian Splatting (3DGS) represents a significant step forward for fast, single-pass neural novel view synthesis, with models such as MVSplat and DepthSplat predicting scene-specific 3D Gaussians from input images. These models typically rely on depth maps, unprojected per-pixel, for geometric reconstruction. However, depth discontinuities—especially around object boundaries—lead to non-ideal 3D Gaussian clouds with artifacts, ultimately degrading rendering quality in extrapolated or challenging viewpoints. The root issue is the inherent geometric disconnect between 2D-predicted depths and the underlying 3D scene structure.
Proposed Method: PM-Loss
To address these geometric inconsistencies, the paper introduces PM-Loss, a plug-and-play regularization term for training feed-forward 3DGS. PM-Loss leverages pointmaps—dense 3D world coordinate predictions regressed by large-scale pretrained transformers (e.g., VGGT or Fast3R)—as a strong geometric prior. Pointmaps, unlike depth maps, directly encode smooth, multi-view-consistent 3D structure at each pixel. The proposed approach distills this geometric prior into 3DGS models via direct 3D supervision, aligning the predicted 3D Gaussian centers to the reference pointmap using efficient closed-form alignment (Umeyama) and a single-direction Chamfer loss.
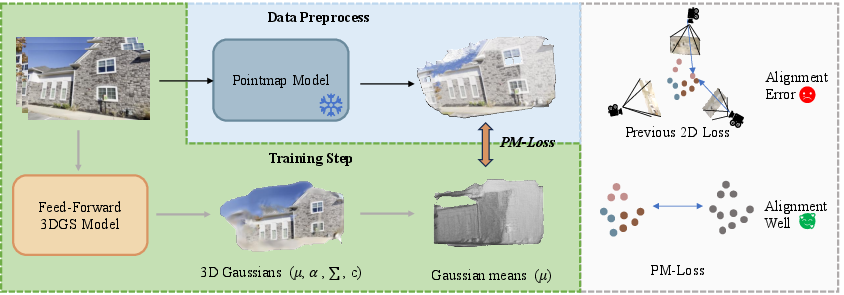
Figure 1: PM-Loss pipeline: A pretrained pointmap model predicts a dense 3D point map, which supervises the 3D Gaussians output by the feed-forward 3DGS; supervision is performed in explicit 3D space for improved fidelity.
This design has critical advantages over prior work. It avoids any modification of core network structure, removes the need for expensive pose-aware model retraining, and requires no extra inference or test-time cost. The regularization directly targets and remedies depth-induced discontinuities, with 3D guidance robust to pose and prediction noise.
Experimental Results
Experiments span multiple datasets (DL3DV, RealEstate10K, DTU) and architectures (MVSplat, DepthSplat). Quantitative metrics on both rendered view quality (PSNR, SSIM, LPIPS) and 3D cloud quality (accuracy, completeness, Chamfer distance) indicate uniformly improved results with PM-Loss. Notably, PSNR often improves by over 2 dB across challenging benchmarks in extrapolation scenarios; geometric metrics show consistent reduction in mean/median errors. The improvements are especially pronounced at boundaries and in under-constrained regions.

Figure 2: Qualitative comparisons on DL3DV and RealEstate10K under 2-view extrapolation—PM-Loss yields improved object boundaries and scene fidelity.
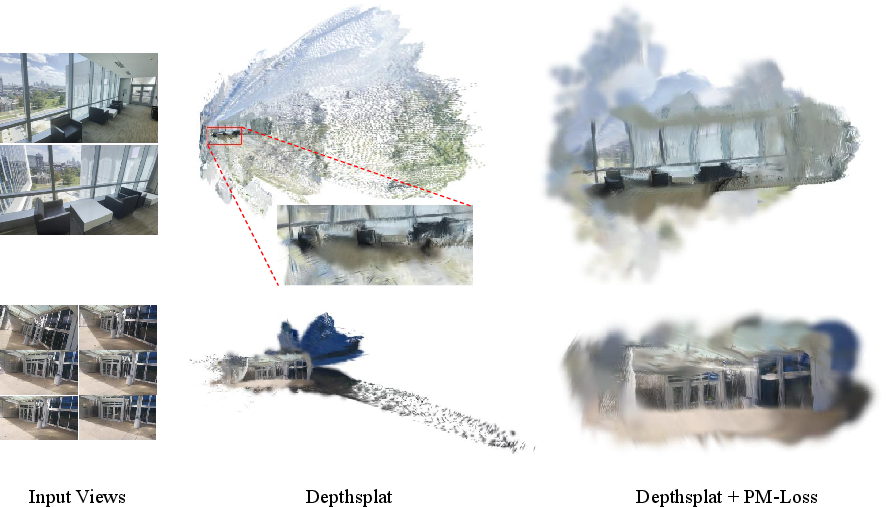
Figure 3: PM-Loss regularization significantly reduces floating artifacts and noise at scene borders in the predicted 3D Gaussian clouds.
The gains persist across different numbers of input views and when using alternative pointmap priors, underscoring the flexibility and robustness of the approach. Pointmap quality is a clear factor—higher accuracy models such as VGGT yield slightly better downstream geometry, though any modern pointmap backbone suffices for notable improvement.
Efficiency is another strength: per-iteration overhead for 3D alignment and loss computation is only ~65ms with Umeyama (vs. >230ms for ICP), and pointmap extraction can be performed offline with negligible memory cost during training.
Architectural and Theoretical Implications
This work exposes fundamental limitations of depth-based 3DGS, pinpointing discontinuities and pixel-wise decoupling as the main causes of poor geometry. By exploiting the strong internal 3D consistency of pointmap models, PM-Loss regularizes Gaussian cloud formation in world space, not camera space, thereby enforcing global geometric constraints absent from traditional metrics or losses.
A key insight is the superiority of 3D-space Chamfer loss over pixel-aligned depth matching: the former allows for robust supervision that is agnostic to minor pose errors and prediction inaccuracies, while retaining one-to-one dense correspondences between predictions and priors.
The method requires only minor modification of existing pipelines and imposes no runtime penalty during inference. This positions PM-Loss as a practical, scalable addition to any feed-forward 3DGS architecture.
Limitations and Future Directions
While the approach is highly effective, the quality of the supervising pointmap directly bounds the achievable 3DGS geometry. If the pointmap model fails (e.g., in low-texture regions like sky), regularization may transfer these errors, as evidenced in explicit failure cases.

Figure 4: Pointmap inaccuracies, such as those from VGGT in sky regions (left), propagate via PM-Loss, resulting in visible artifacts in the final 3D Gaussian cloud (right).
Thus, advances in large-scale pointmap regression (e.g., larger ViT backbones, better self-supervised geometric pretraining) can be directly leveraged by PM-Loss, promising continual improvements in feed-forward 3DGS without further architectural changes. The plug-and-play design also suggests potential synergy with other geometric priors and hybrid regularization strategies.
Practical Implications and Societal Considerations
The integration of PM-Loss into feed-forward 3DGS offers immediate benefits for fast, accurate scene-level novel view synthesis in AR/VR, robotics, and content creation. Improved geometric fidelity, especially near boundaries and under incomplete views, expands usability in challenging real-world scenarios and sparse-view capture settings.
However, by enabling convincing 3D reconstruction even from sparse or ambiguous input, the technique elevates realistic content generation while also introducing opportunities for misuse (e.g., photorealistic fake environments). As with other advances in neural rendering, careful consideration of downstream applications is essential.
Conclusion
PM-Loss presents an effective, efficient, and practical methodology for addressing the geometric weaknesses of depth-based feed-forward 3DGS. By leveraging pretrained pointmap priors for explicit 3D supervision, it delivers consistent and significant improvements across architectures and datasets without introducing test-time overhead. The approach is particularly effective in mitigating depth-induced boundary discontinuities—a longstanding obstacle for feed-forward novel view synthesis methods. As stronger pointmap models emerge, the utility of this regularization is likely to increase, pointing toward a unified framework for geometry-aware neural rendering.

Figure 5: Comprehensive render results on DL3DV and RealEstate10K—PM-Loss robustly enhances boundary reconstruction fidelity in extrapolated views.
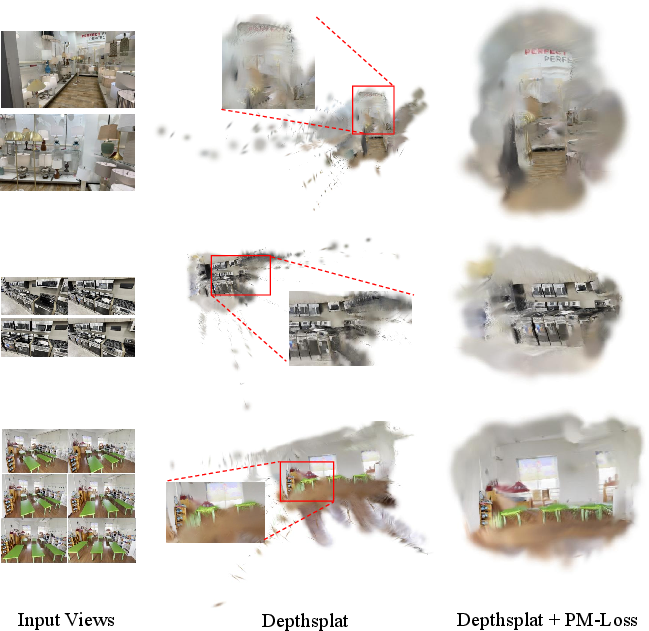
Figure 6: Further comparative results: reduction of floating artifacts and geometric noise in the DL3DV dataset with PM-Loss regularization.