- The paper introduces the Kinetics scaling law, emphasizing attention costs over parameter counts during model inference.
- It demonstrates that models above 14B parameters combined with sparse attention offer significant gains in efficiency and problem-solving performance.
- Sparse Kinetics, implemented via block top-k attention, reduces memory bottlenecks and enhances throughput for scalable LLM deployment.
Kinetics: Rethinking Test-Time Scaling Laws
Introduction
The paper "Kinetics: Rthinking Test-Time Scaling Laws" (arXiv ID: (2506.05333)) presents a novel perspective on test-time scaling laws by re-evaluating them through the lens of practical efficiency, focusing on the memory access bottlenecks encountered during inference. Unlike prior approaches that primarily consider compute-optimality, this work underscores the significance of attention-related costs in the test-time compute landscape. It introduces the Kinetics scaling law, which prioritizes models with parameter sizes above a key threshold, emphasizing that attention mechanisms, rather than parameter counts, are pivotal in determining inference costs.
Test-time scaling strategies such as Best-of-N and Long-CoT have gained traction for their ability to enhance the reasoning capabilities of LLMs. However, they impose substantial inference-time costs, with memory access often overshadowing pure computational costs. The paper explores how traditional scaling laws overestimate the benefits of smaller models, advocating instead for resource allocation to focus on larger models and sparse attention technologies.
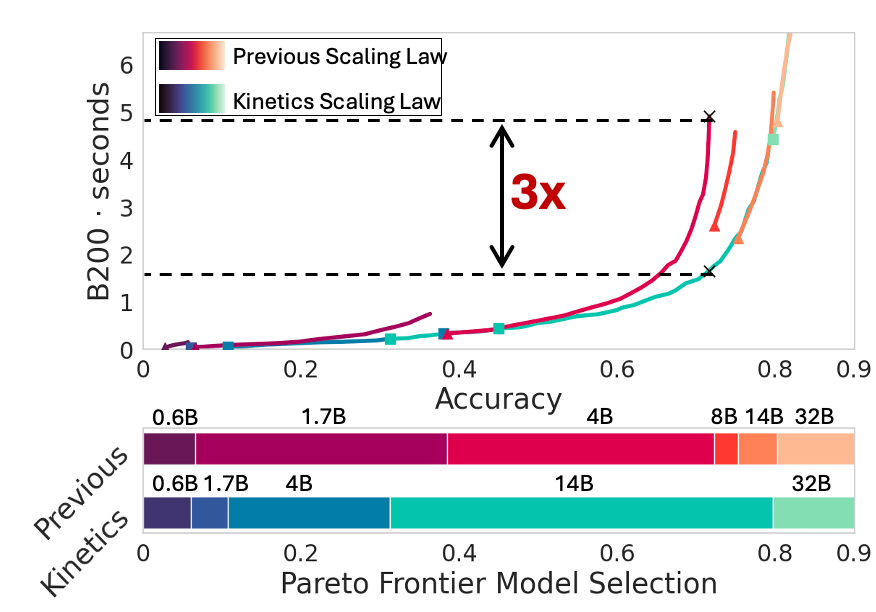
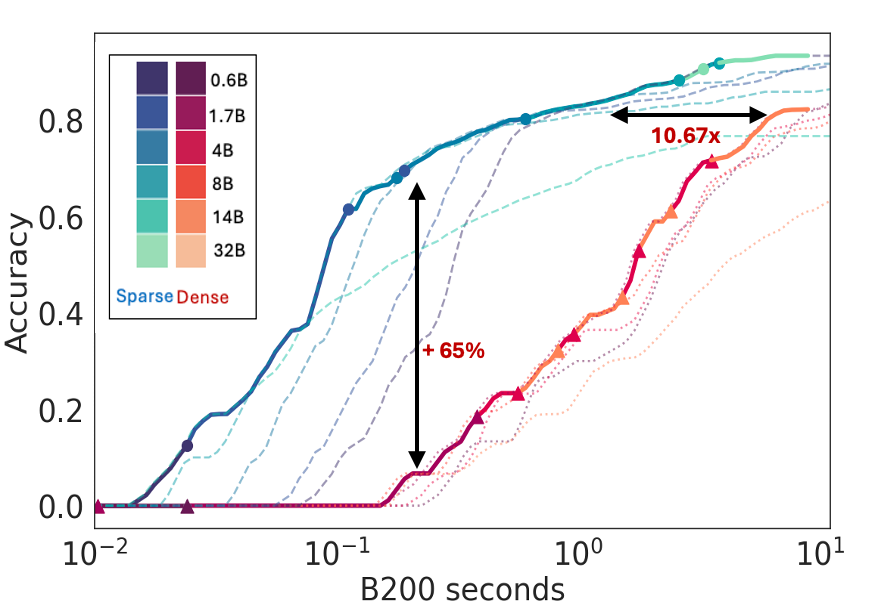
Figure 1: Pareto Frontier for Qwen3 series on AIME24 with Long-CoTs highlighting memory bottlenecks.
Kinetics Scaling Law
Kinetics is derived by incorporating the disproportionate increase in attention costs over parameter counts during test-time, challenging the assumption that smaller models inherently offer efficiency when paired with scaling strategies. A critical observation is that extending model size beyond 14 billion parameters yields superior test-time compute benefits, shifting the strategy from merely extending sequence lengths.
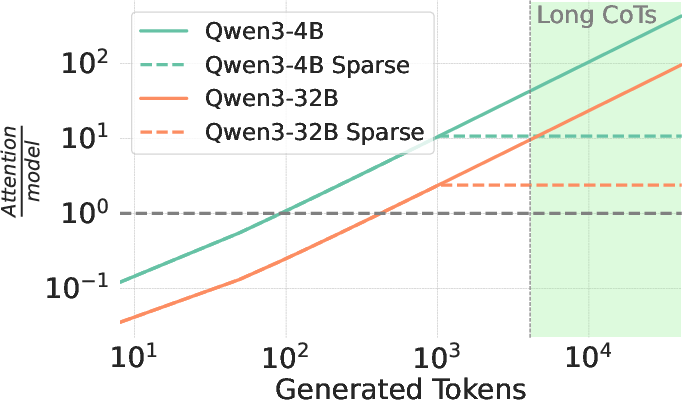
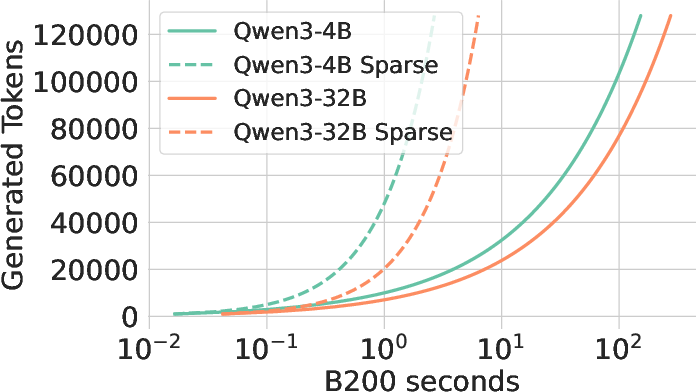
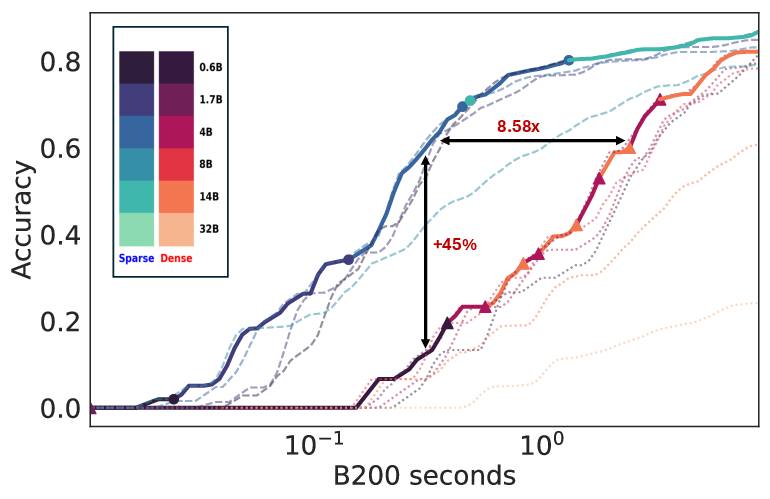
Figure 2: Inference cost dominance by attention, showcasing the substantial impact of attention-related computations.
The paper introduces Sparse Kinetics, a paradigm where sparse attention allows for reduced per-token costs, enabling longer and more parallel generations within the same computational budget. Sparse attention models consistently outperform dense counterparts, realizing impressive gains in problem-solving accuracy in high-cost scenarios.
Empirical results demonstrate that sparse attention can enhance problem-solving rates by over 60 points in low-cost regimes, maintaining a performance lead even at higher budgets. These findings solidify the importance of considering hardware efficiency and attention sparsification as primary factors in test-time scaling.
Sparse Attention and Implementation
Sparse attention fundamentally transforms the test-time scaling landscape. The paper proposes practical applications of block top-k attention to simplify the implementation without sacrificing the effectiveness. This approach efficiently handles memory bottlenecks, thereby facilitating a substantial increase in throughput.
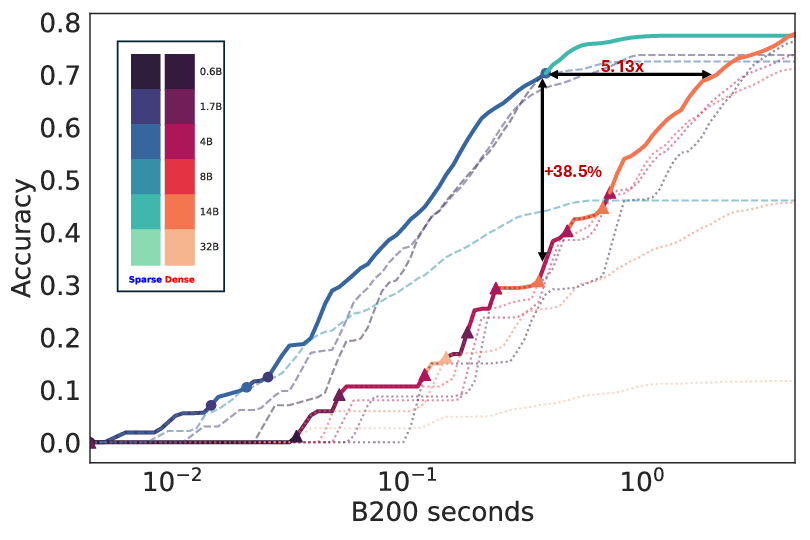
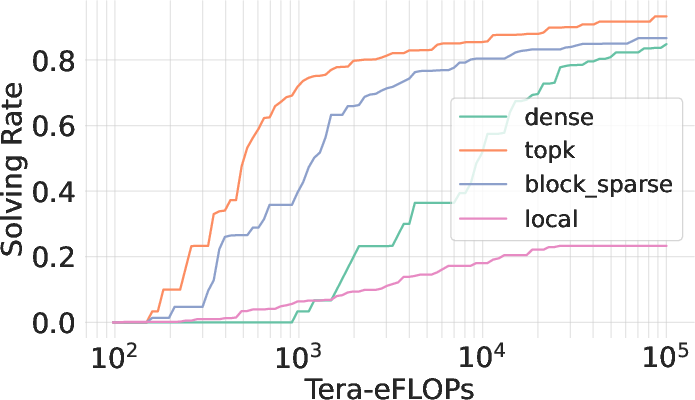
Figure 3: Block top-k attention showcases trade-offs between simplicity and performance effectiveness.
The empirical implementation uses Flashinfer and optimized libraries to demonstrate practical efficiency gains in task throughput. Block top-k attention, while not as optimal as oracle top-k, provides a tangible path toward scalable and efficient LLM inference.
Implications and Future Directions
Sparse Kinetics marks a significant shift in the deployment strategy of LLMs. By integrating sparse attention mechanisms, the paper opens avenues for advancing both inference efficiency and model architecture design. Future work could further explore dynamic sparsity patterns and adaptive resource allocation in response to task complexity, potentially leading to even greater optimization in test-time scaling.
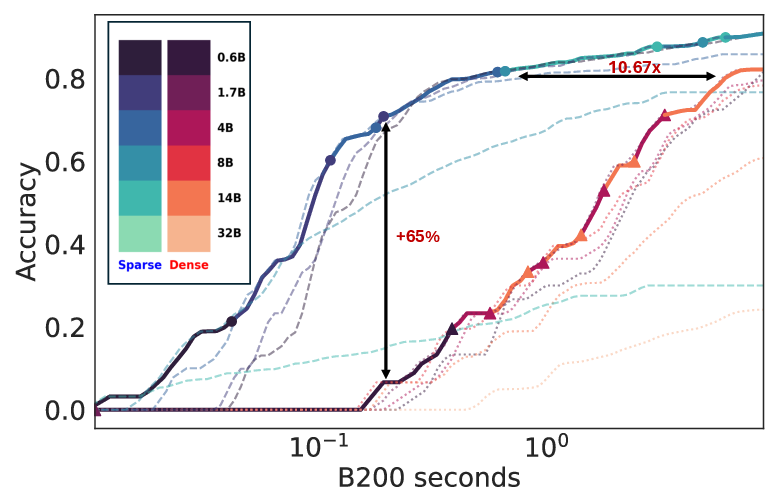
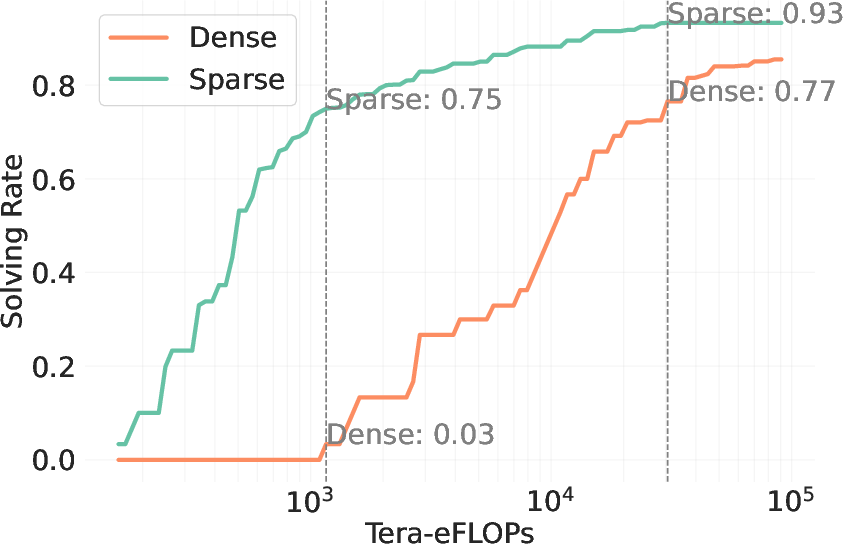
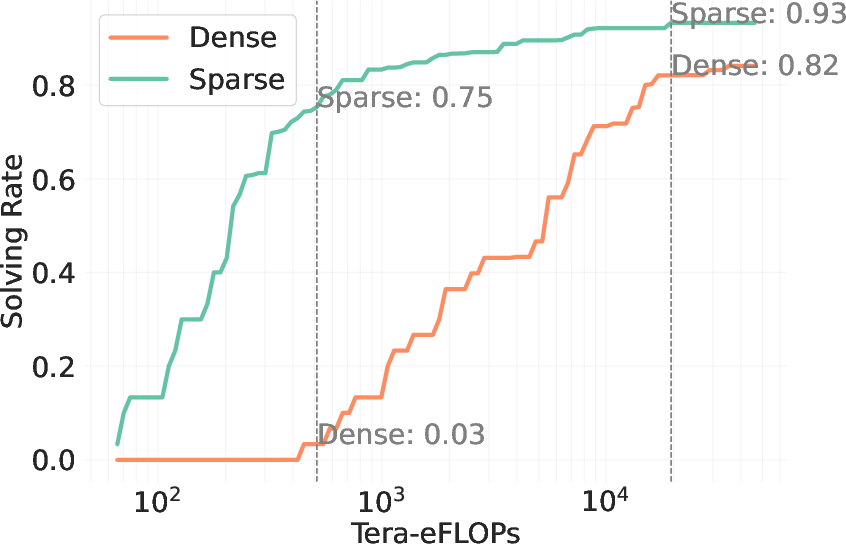
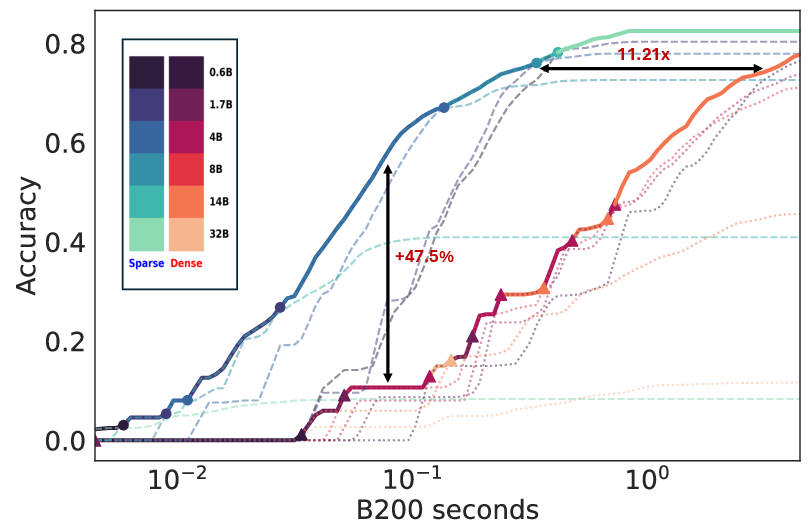
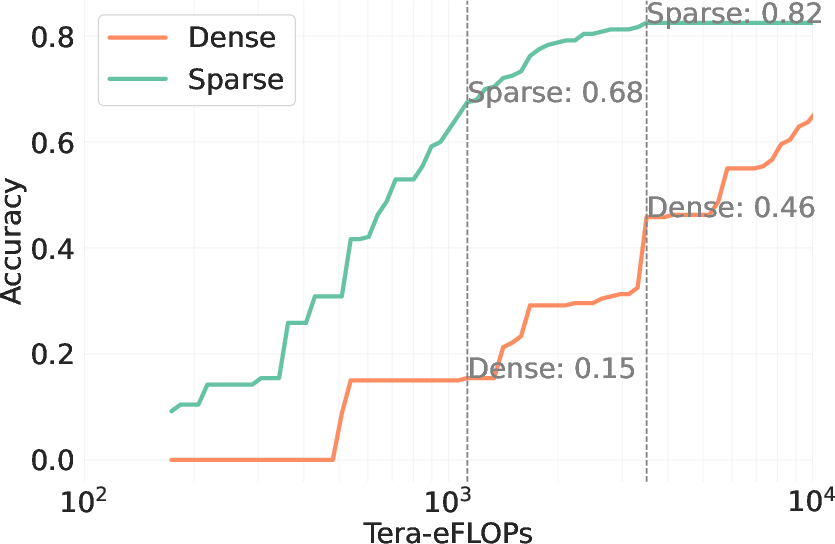
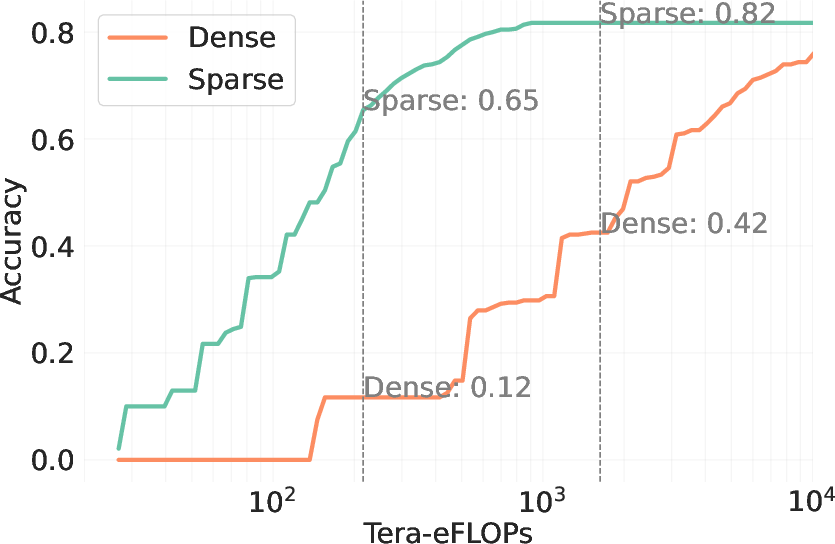
Figure 4: Sparse attention boosts test-time scaling, evidencing substantial improvements in efficiency and accuracy.
The transition from token-centric metrics to task-level throughput highlights the broader applicability and societal utility of generative models when implemented efficiently. Co-design between hardware and algorithmic strategies stands out as a pivotal direction for future research, accelerating the march toward sustainable and scalable AI deployment.
Conclusion
The paper establishes the Kinetics as a pivotal test-time scaling law, emphasizing the critical role of attention costs. By transitioning to sparse attention paradigms, this study underlines the pathway to more efficient and scalable LLM deployment. As we anticipate further advancements in model architecture and inference systems, sparse attention is poised to reshape the contours of AI scalability beyond the limits of current pretraining paradigms.