- The paper introduces Search Arena, a dataset of over 24,000 multi-turn interactions that enriches LLM training with diverse, multilingual user intents.
- The study demonstrates that search-augmented LLMs maintain competitive performance in search-intensive settings by integrating real-time web data.
- The analysis reveals that user preferences are influenced by citation abundance, highlighting challenges in ensuring the relevance and credibility of sources.
Analysis of "Search Arena: Analyzing Search-Augmented LLMs"
Introduction and Motivation
The study, "Search Arena: Analyzing Search-Augmented LLMs", examines a niche but expanding segment of AI research focused on search-augmented LLMs. These models enhance traditional LLM capabilities by leveraging web search to inform the model's responses with current and contextually relevant information. The work recognizes a significant gap in current datasets which are limited by scale, scope, and diversity, primarily focusing on English and single-turn factual inquiries. This paper introduces the Search Arena dataset, a large, multilingual corpus that captures human interactions with search-augmented LLMs, explicitly aiming to enrich the dataset diversity concerning intents, conversations, and languages.
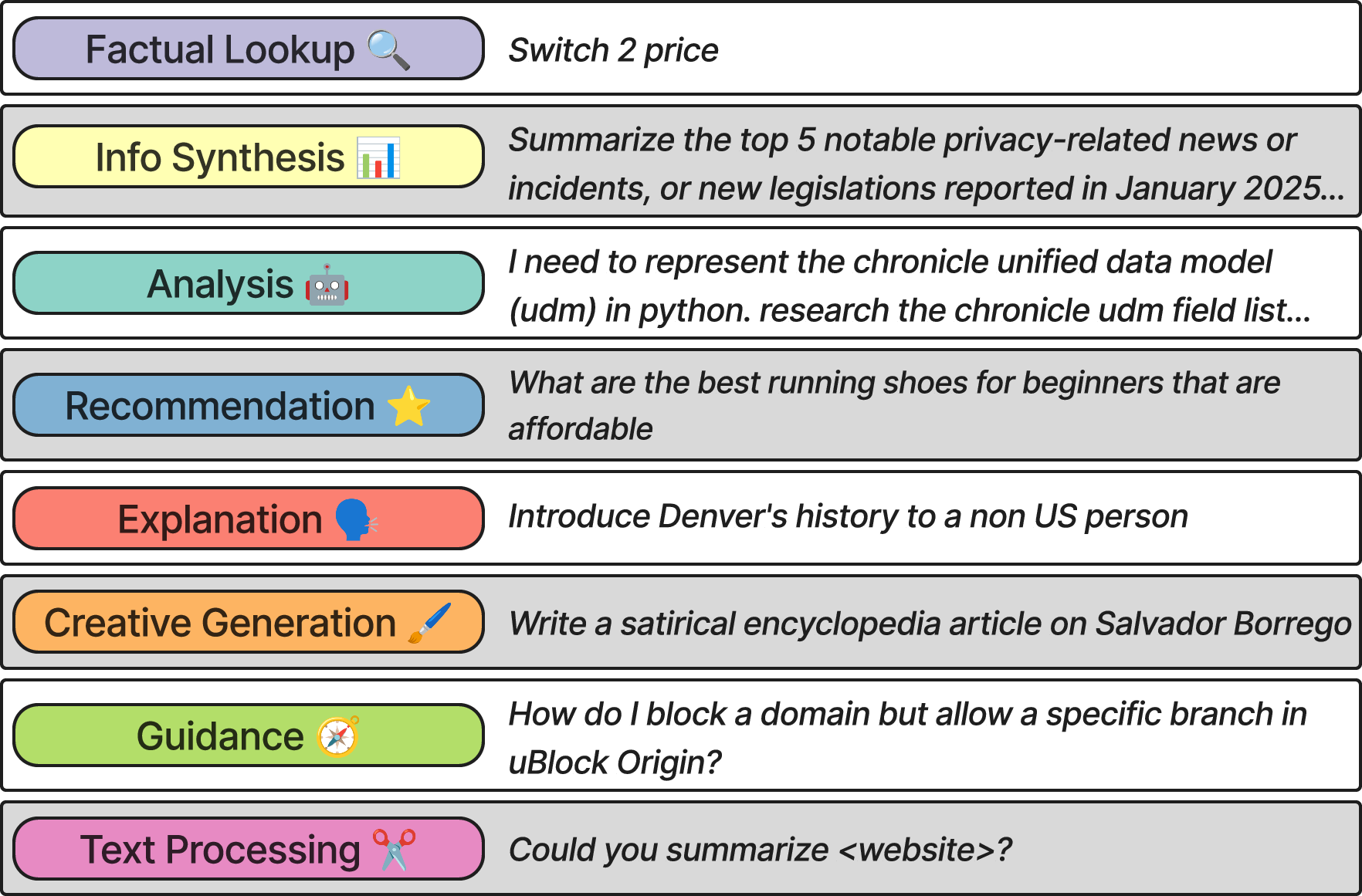
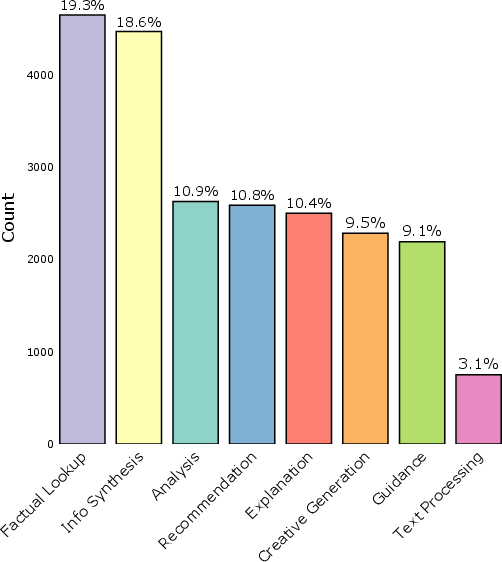
Figure 1: Nine intent categories with representative examples illustrating the distribution and diversity of user prompts requiring real-time web retrieval.
Dataset Composition
The Search Arena dataset stands out due to its unprecedented scale, encompassing over 24,000 multi-turn user interactions and annotated with more than 12,000 human votes reflecting user preferences. The presence of multilingual prompts (spanning 70 languages) and a sophisticated taxonomy categorizing user intents into nine distinct types marks a significant departure from previous datasets restricted to English-language single-turn queries. The dataset reveals that factual lookups constitute a small segment of real-world user queries, noticing a broader spectrum including analysis, recommendations, and synthesis, indicating the need for LLMs to provide nuanced and multi-faceted responses beyond simple facts.
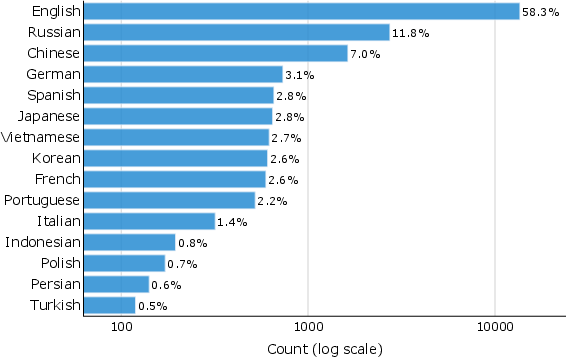
Figure 2: Search Arena dataset distribution across languages and comparison of prompt lengths with other datasets.
User Preferences and Citation Analysis
The study also inspects user preferences and the role of citations. User preference is notably influenced by the number and type of sources cited, suggesting a correlation between perceived response credibility and citation presence, although citations do not always support attributed claims. The bias towards preferring abundant citations—even when irrelevant—raises concerns about user susceptibility to citation wisdom rather than content accuracy.
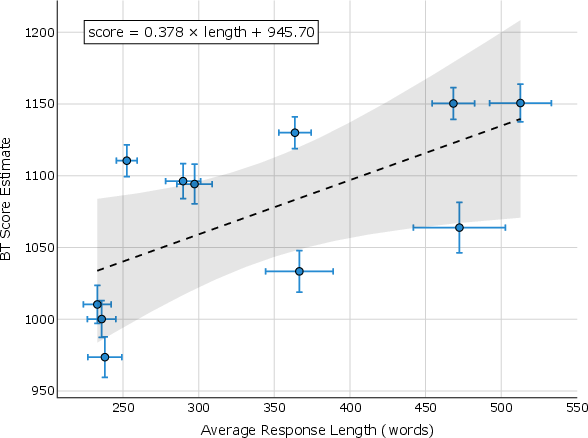
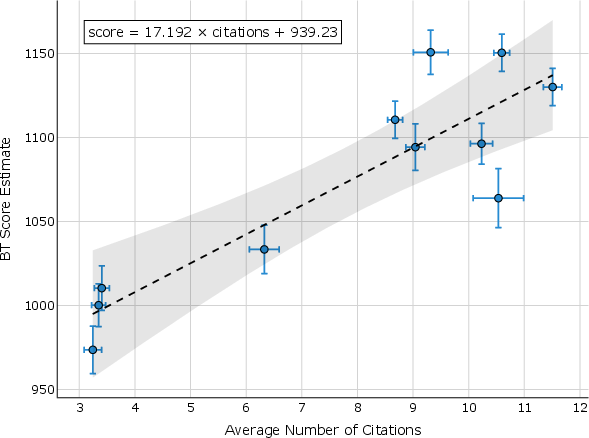
Figure 3: Positive relationship between model score, response length, and the number of citations.
Cross-Arena Evaluation
The paper introduces a robust cross-arena experimental setup to examine the adaptability of search-augmented LLMs across different environments, contrasting them with non-augmented LLMs. Results indicate that search models maintain competitive performance across general and search-intensive settings, whereas non-search models struggle in the latter. This illustrates a potential benefit of integrating search capabilities into LLMs, especially for knowledge retrieval tasks requiring current data.
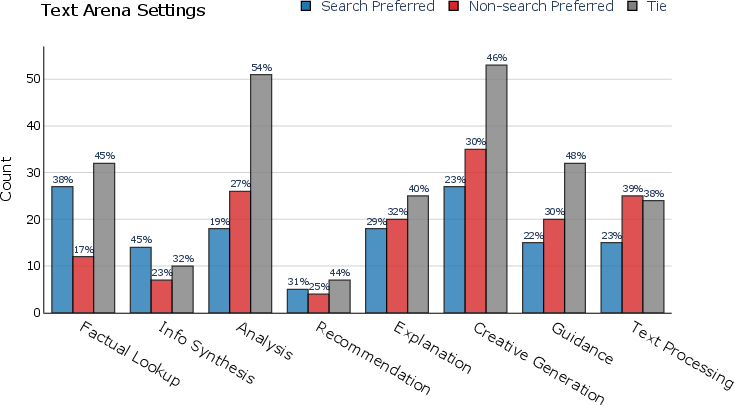
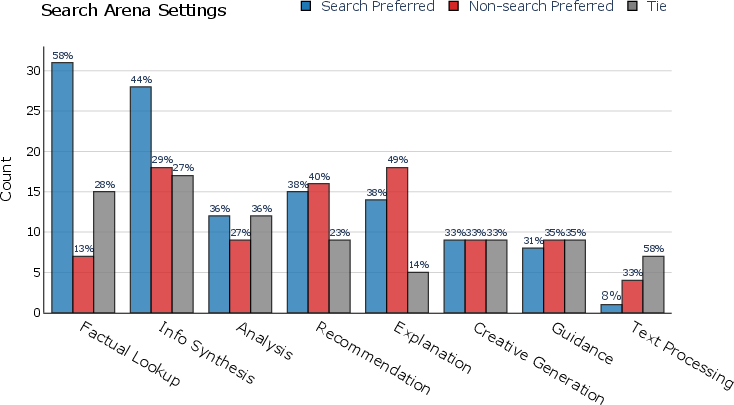
Figure 4: User preferences for different models categorized by prompt intent across Text Arena and Search Arena.
Implications and Future Work
The introduction of Search Arena opens avenues for developing more sophisticated evaluation methods for LLMs, evident from the dataset's scale and diverse linguistic and intent dimensions. Future research should focus on improving the underlying quality of citations and the interpretability of this data in generating trusted and credible AI responses. Addressing the challenge of citation attribution remains a key research field, as highlighted by users' preference for responses with factually irrelevant citations.
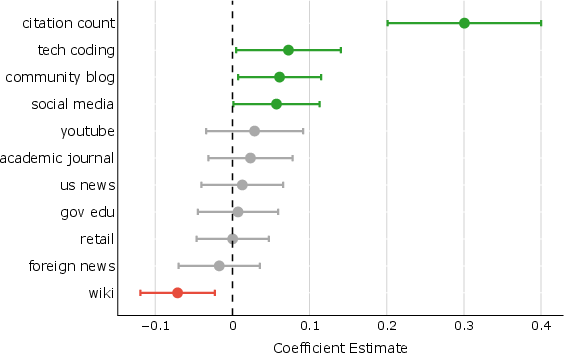
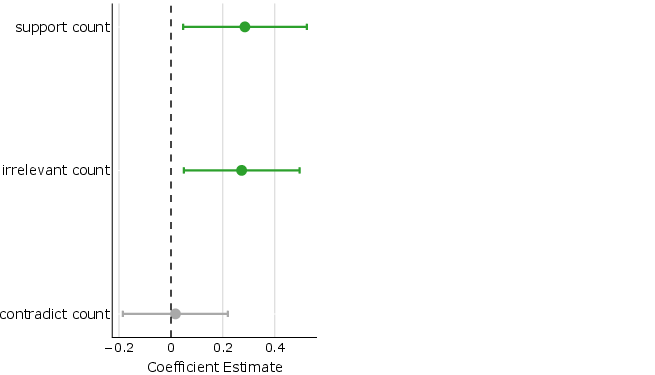
Figure 5: Analysis of citation effects on user preference with subsections detailing citation types and user bias.
Conclusion
The "Search Arena" paper highlights the complexity involved in evaluating search-augmented LLMs by providing a novel, comprehensive dataset capturing real-world AI-human interactions. Through substantial user interaction data and rigorous evaluation protocols, this paper contributes significantly to our understanding of how search-augmentation impacts LLM performance and user satisfaction. This dataset paves the way for ongoing research into more nuanced, reliable, and user-centered AI model evaluations.
In conclusion, the findings emphasize the importance of developing LLMs that leverage real-time data efficiently, ensuring the delivery of factual and context-appropriate responses that align with user expectations across variable settings.