- The paper introduces PuzzleWorld, a benchmark with 667 real-world puzzles for evaluating multimodal, open-ended reasoning in puzzlehunts.
- It employs a dual-axis taxonomy and comprehensive human annotations to capture intermediate reasoning steps and diagnose model performance.
- Findings reveal low final solution accuracy, with fine-tuning enhancing reasoning steps, highlighting challenges in visual and spatial tasks.
PuzzleWorld: A Benchmark for Multimodal, Open-Ended Reasoning in Puzzlehunts
PuzzleWorld is introduced as an innovative benchmark designed to evaluate LLMs and multimodal systems in open-ended, multimodal reasoning tasks derived from puzzlehunts. This paper addresses the gap in AI benchmarking by providing a robust dataset that encompasses multimodal reasoning and the identification of implicit problem structures, challenging the limits of current state-of-the-art models.
PuzzleWorld Benchmark Design
PuzzleWorld consists of 667 real-world puzzles curated from the Puzzled Pint event series, specifically designed to test open-ended, multimodal reasoning capabilities. The puzzles demand solvers, both human and AI, to discern and interpret intricate cues distributed across multiple modalities, including text, visual, and structured data.
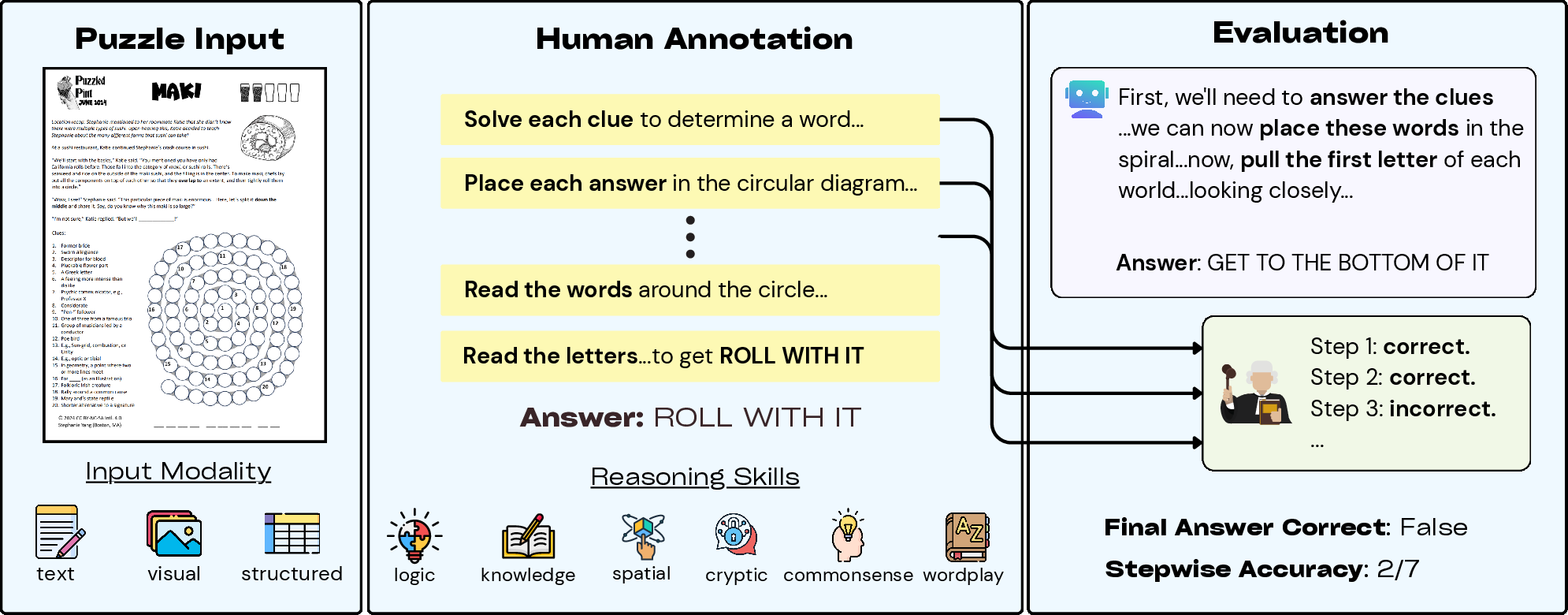
Figure 1: Overview of PuzzleWorld detailing the dataset from PuzzledPint and annotations by human annotators.
Each puzzle is annotated with detailed solution traces and cognitive skill labels, providing a comprehensive framework for evaluating AI models' step-by-step reasoning processes. This structure facilitates both holistic benchmarking and meticulous diagnostic assessments of various models' intermediate reasoning abilities.
Taxonomy and Dataset Construction
The paper proposes a dual-axis taxonomy system for puzzle categories based on input modalities and reasoning mechanisms. This framework enables a detailed assessment of models’ reasoning performance across different cognitive dimensions, including logical deduction, wordplay, and spatial reasoning.

Figure 2: Sample annotations illustrating the modalities and reasoning skills required for different PuzzleWorld puzzles.
The dataset construction process involves sourcing puzzles and human annotating reasoning steps from solution documents. This annotation allows for tracing the logical derivations and transformations required to arrive at puzzle solutions, offering insights into potential AI failure points and improvement areas.
Evaluation of AI Models on PuzzleWorld
The authors evaluate several state-of-the-art closed and open-source models, such as GPT-4o and Qwen QVQ, on the PuzzleWorld dataset. Findings reveal that existing models achieve low accuracy on final solutions, with the majority falling between 1-2%. The best-performing model, GPT-o3, solved only 14% of puzzles, highlighting the significant challenges posed by PuzzleWorld.
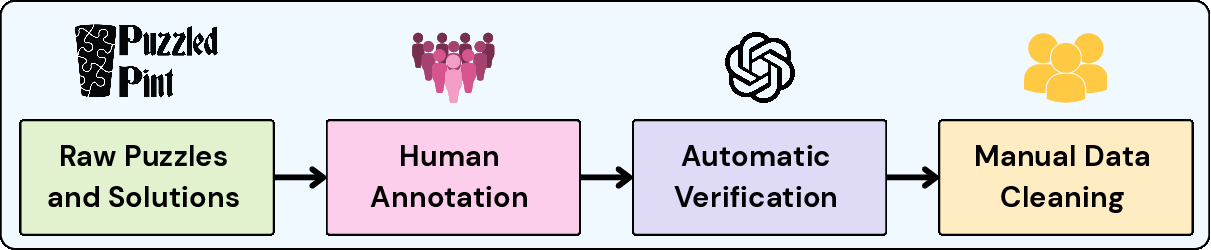
Figure 3: Dataset construction process and statistics showing the complexity and annotation details of puzzles.
Despite poor final answer performance, the detailed stepwise reasoning evaluation illuminates intermediate capabilities where models can still demonstrate partial understanding and logical follow-through, albeit failing to conclude correctly. Results indicate a pronounced dependence on textual strategies for reasoning, often a bottleneck in puzzles requiring visual and spatial manipulations.
Error Analysis and Improvement via Fine-tuning
Detailed error analyses reveal critical areas where models falter, such as visual misinterpretation and lack of sketching ability—key for tasks demanding manipulative and spatial reasoning skills. It is evident that models tend to exhibit myopic reasoning, failing to employ backtracking strategies when initial hypotheses are disproven.
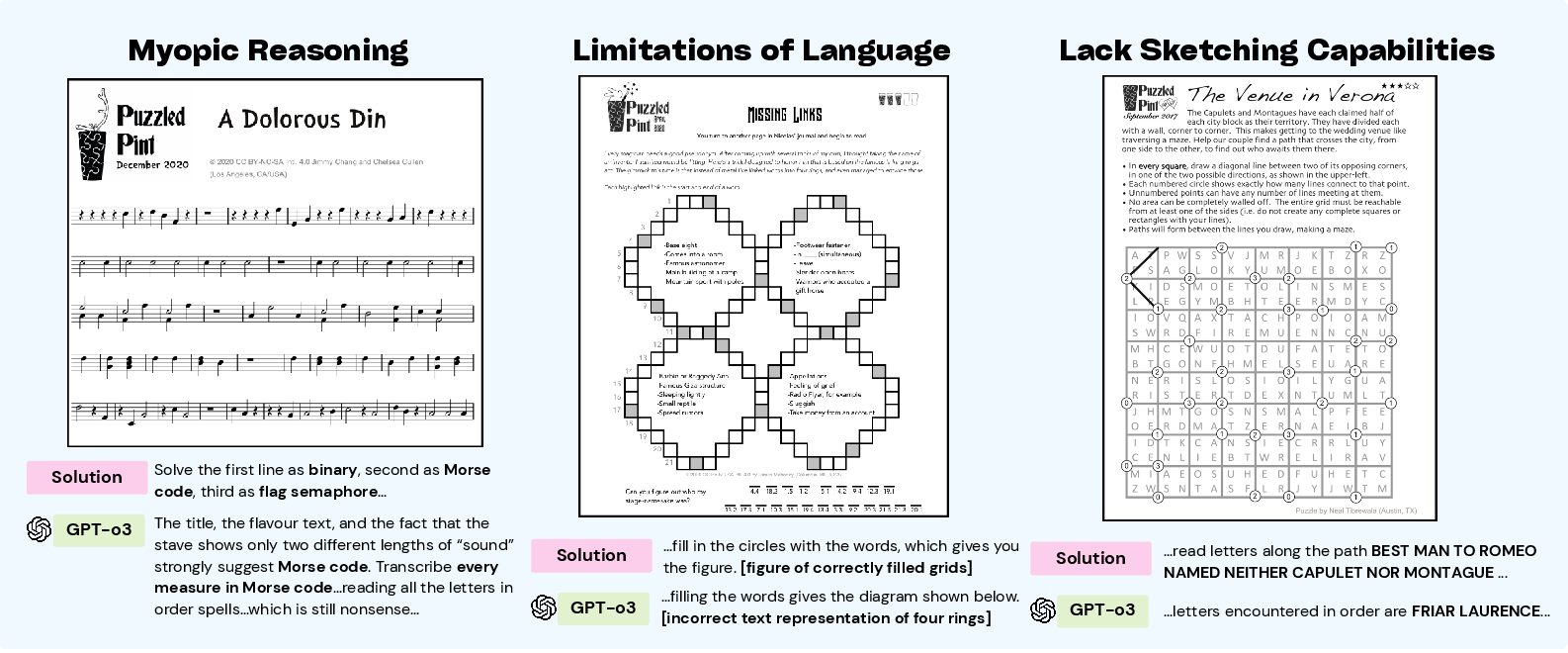
Figure 4: Example puzzle errors illustrating myopic reasoning, language bottlenecks, and sketching errors.
Fine-tuning models using intermediate reasoning data from PuzzleWorld significantly enhances stepwise accuracy, demonstrating that improvements in detailed annotations and structured reasoning training can lead to better performance despite unchanged final answer accuracy.
Conclusion
PuzzleWorld represents a crucial advancement in creating more comprehensive benchmarks for evaluating complex, multimodal reasoning in AI. By challenging models with scenarios that mimic open-ended and creative human problem-solving, PuzzleWorld underscores the limitations of current AI capabilities and highlights pathways for developing more adaptive, generalist AI systems.
PuzzleWorld provides a rigorous resource for the ongoing development and benchmarking of multimodal reasoning systems, marking a step towards achieving more advanced, general-purpose AI applicable in real-world problem-solving contexts. The dataset and its annotations are accessible for further research and development at the provided repository.