- The paper establishes the first public benchmark for MSA mispronunciation detection using Qur'anic recitations as a realistic case study.
- It combines real and synthetic data from Common Voice and TTS augmentation, utilizing SSL models with CTC loss to predict phoneme sequences.
- Results indicate that the multilingual mHuBERT model outperforms other SSL variants, offering a foundational benchmark for further research.
Towards a Unified Benchmark for Arabic Pronunciation Assessment: Quranic Recitation as Case Study
Introduction
The paper introduces a comprehensive benchmark for evaluating mispronunciation detection in Modern Standard Arabic (MSA) by utilizing Qur'anic recitation as a case study. This work establishes a standardized framework for advancements in Arabic pronunciation assessment, setting the stage for future research and development in this domain. The authors present a pipeline encompassing data processing, a specialized phoneme set for nuanced MSA pronunciation, and a benchmark test set termed the Qur'anic Mispronunciation Benchmark (QuranMB.v1).
Dataset Curation
Given the scarcity of phonetically labeled Arabic speech, the authors address this limitation by curating a diverse dataset using two key strategies. The training set, CMV-Ar, is derived from an 82.37-hour subset of the Common Voice dataset for MSA Arabic, supplemented with vowelized Qur'anic recitations. Additionally, the authors employ a Text-to-Speech (TTS) augmentation process to generate synthetic data with controlled pronunciation errors, totaling 52 hours of speech data. The TTS augmentation process is pivotal in simulating realistic mispronunciation patterns.
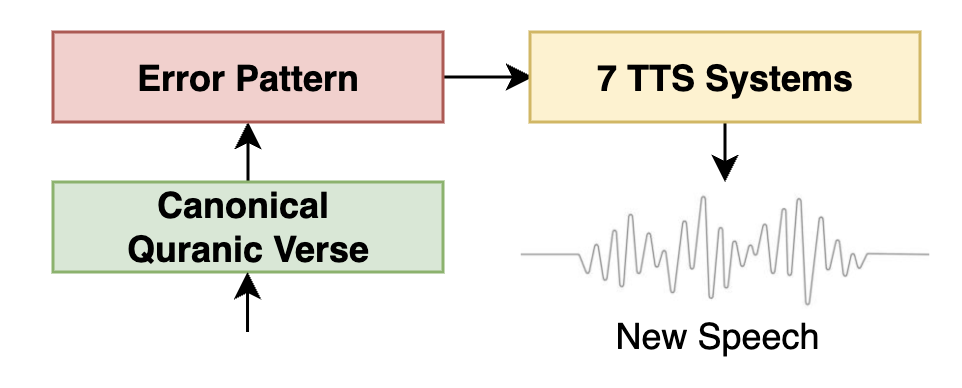
Figure 1: TTS Augmentation Pipeline.
The testing dataset, QuranMB.v1, consists of read-aloud recordings of 98 Qur'anic verses by 18 native speakers, deliberately incorporating mispronunciation errors, facilitated by a custom recording tool.
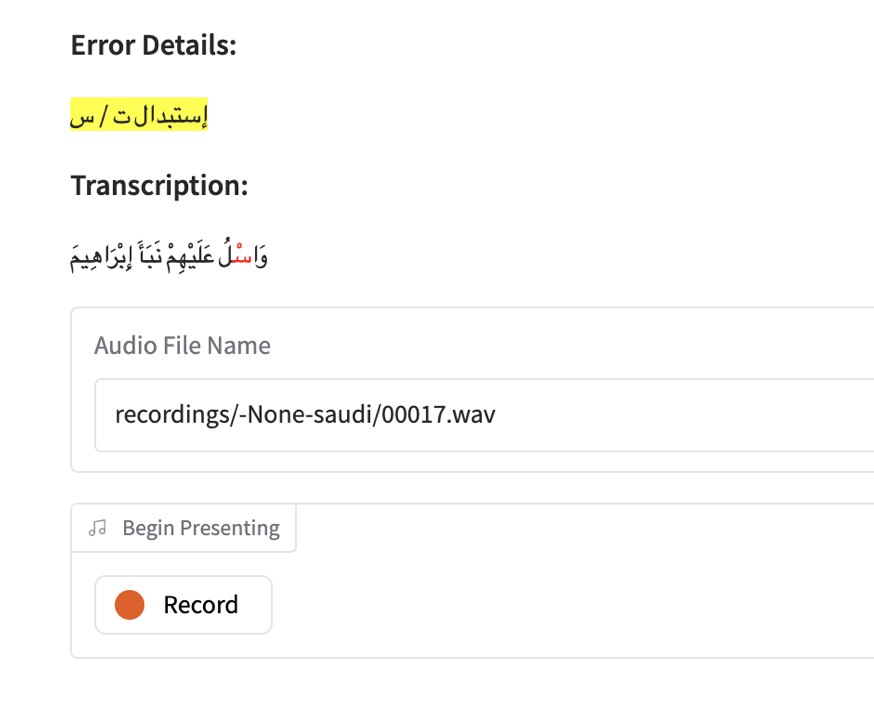
Figure 2: Interface of the recording tool, highlighting modified text and providing instructions to ensure consistent pronunciation errors.
Methodology
The authors leverage a self-supervised learning (SSL)-based framework for Mispronunciation Detection and Diagnosis (MDD). The system utilizes SSL models such as Wav2vec2, HuBERT, WavLM, and mHuBERT, evaluated with real, synthetic, and combined datasets. Connectionist Temporal Classification (CTC) loss guides phoneme sequence predictions, while hierarchical evaluation measures model performance across True Accept (TA), False Reject (FR), False Accept (FA), Correct Diagnosis (CD), and Error Diagnosis (ED) metrics.
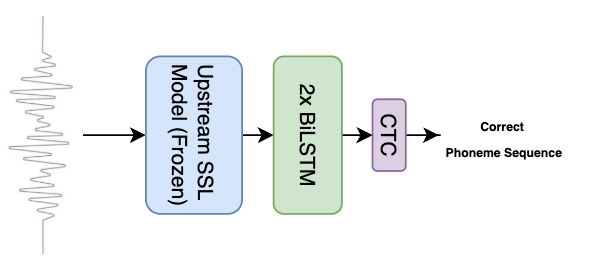
Figure 3: Mispronunciation Detection Modeling Pipeline.
Results and Analysis
The multilingual mHuBERT model outperforms monolingual SSL variants across data configurations, achieving the highest F1-scores, highlighting its effective representation of Arabic phonetic variations. Synthetic data from TTS models achieves competitive performance, suggesting its suitability for capturing nuances of recitation errors. Combined datasets enhance the mHuBERT model's performance further. Although current models show challenges in achieving precise phonetic alignment, with a maximum F1-score of 30%, these baseline results provide a foundational benchmark for future research.
Conclusion
This paper establishes the first public benchmark for MSA pronunciation detection, offering valuable resources such as the QuranMB.v1 test dataset and detailed data curation methodologies. Despite the complexity of Qur'anic pronunciation assessment, the initial benchmarks highlight the importance of diverse, well-curated datasets combined with advanced augmentation techniques. Future work will continue expanding benchmarks, incorporating broader datasets, and extending phoneme vocabularies, thereby contributing significantly to advancements in Arabic pronunciation technology.

