- The paper introduces a novel reinforcement pre-training method that reframes next-token prediction as a reasoning task using on-policy reinforcement learning.
- The paper demonstrates significant accuracy improvements by leveraging unannotated text and scalable compute, outperforming benchmarks like R1-Distill-Qwen-32B.
- The paper sets a robust foundation for future RL-based fine-tuning by promoting deeper reasoning processes and improved token prediction.
Reinforcement Pre-Training for LLMs
Reinforcement Pre-Training (RPT) introduces a new paradigm in the scaling of LLMs by integrating Reinforcement Learning (RL) with the well-established next-token prediction task. In doing so, it transforms next-token prediction into a reasoning task enhanced by RL, which is scalable to large text corpora without requiring domain-specific annotations. This approach aims to improve the language modeling accuracy and serves as a robust foundation for further reinforcement fine-tuning.
Motivation and Background
Traditional LLMs predominantly rely on the next-token prediction objective, a form of self-supervised learning that scales effectively across diverse text corpora. However, leveraging RL in LLMs typically encounters challenges of scalability and domain specificity, primarily due to dependency on human feedback and annotated datasets. Techniques like Reinforcement Learning from Human Feedback (RLHF) face issues like reward hacking, whereas Reinforcement Learning with Verifiable Rewards (RLVR) is limited by data scarcity.
RPT attempts to unify these realms by reframing next-token prediction, a fundamental task, as next-token reasoning (Figure 1). This approach uses the vast unannotated text data available, imposing a reasoning step prior to the prediction. The model receives reward signals based on the correctness of its predictions, hence promoting a deeper understanding of text content rather than superficial pattern matching.

Figure 1: Comparison of standard next-token prediction and next-token reasoning. Standard next-token prediction estimates the next token in the pre-training corpus directly, while next-token reasoning performs reasoning over multiple tokens before making the prediction.
Reinforcement Pre-Training Framework
The RPT method, as illustrated in Figure 2, structures LLM training around next-token reasoning through on-policy reinforcement learning. For each context derived from a training corpus, the model predicts multiple potential outcomes (trajectories). The correctness of each trajectory is evaluated, and positive rewards are only granted to those matching ground-truth sequences.
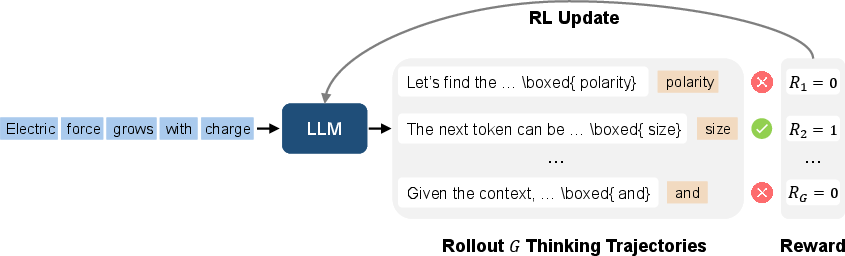
Figure 2: An illustration of reinforcement pre-training. Given a context with a missing continuation, the LLM performs on-policy rollouts to generate multiple thinking trajectories, each with interim reasoning and a final prediction.
This mechanism involves calculating rewards based on prefix-matching between the predicted and actual next token sequences, thus encouraging the generation of accurate token predictions.
Evaluation and Results
Experiments involving RPT demonstrated a significant improvement in next-token prediction accuracy, most notably surpassing performance benchmarks of equivalent or larger models like R1-Distill-Qwen-32B at varying levels of task difficulty (Figure 3). Notably, the RPT model's accuracy scales positively with increased compute, maintaining high coefficients of determination in these scaling experiments (Figure 4).
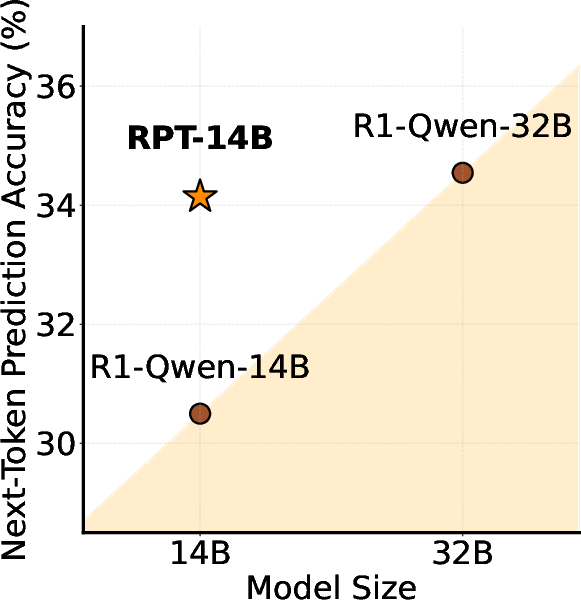
Figure 3: Average next-token prediction accuracy across data of various difficulty levels, showing superior performance of RPT models.
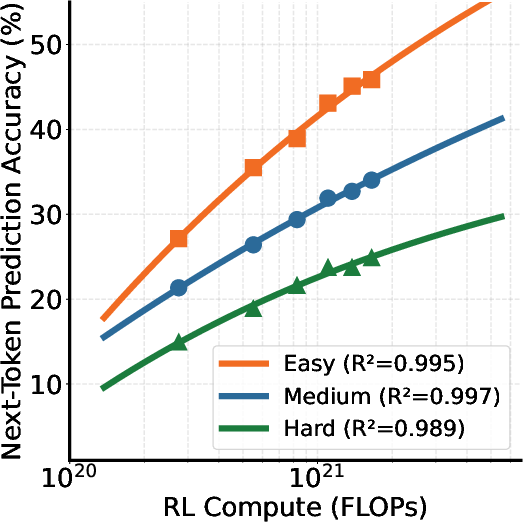
Figure 4: Next-token prediction accuracy of reinforcement pre-training improves consistently with increased training compute under all data difficulties, indicating robust alignment with the scaling laws.
The scalability of RPT is underscored by its reliable improvement through increased computational resources, positioning it as a sustainable model development strategy. Furthermore, the analysis of reasoning patterns (Figure 5) indicates that the model, through RPT, engages more complex reasoning frameworks, which are qualitatively different from conventional problem-solving strategies.
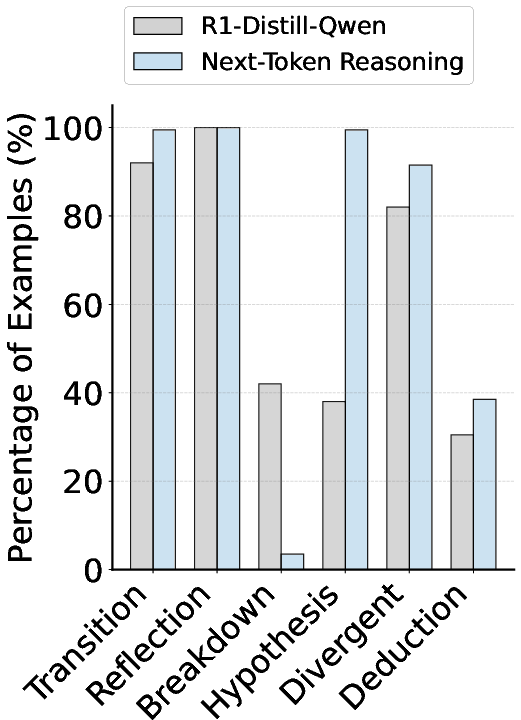
Figure 5: Reasoning pattern statistics of models in problem-solving and next-token reasoning, highlighting distinct reasoning processes facilitated by RPT.
Conclusions and Future Directions
Reinforcement Pre-Training sets a foundational shift in LLM development by effectively merging RL methodologies with traditional language pre-training tasks. This paradigm promotes richer understanding and reasoning capabilities in models, serving as a robust precursor for RL-based fine-tuning.
Future endeavors aim to explore broader datasets beyond mathematical contexts and to extend RPT frameworks across varied text domains. Additionally, establishing scaling laws specific to RPT and incorporating hybrid models that balance traditional and next-token reasoning approaches are avenues for further exploration. This ongoing research underlines the potential of RPT in pushing the boundaries of comprehensively capable and efficient LLMs, broadening their applicability and functional depth across AI-driven tasks.