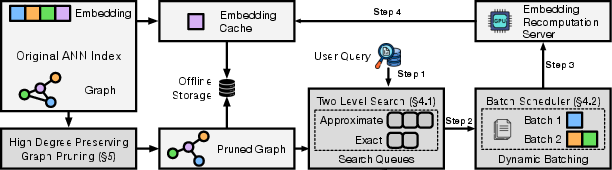
- The paper presents a novel storage-efficient vector index that recomputes embeddings on-the-fly using a graph-based approach.
- It leverages a high-degree preserving graph pruning algorithm to maintain search accuracy while reducing the storage footprint to under 5%.
- Dynamic batching optimizes GPU usage, ensuring query latency remains under 2 seconds with 90% top-3 recall performance.
LEANN: A Low-Storage Vector Index
Introduction
The paper "LEANN: A Low-Storage Vector Index" explores the development of a storage-efficient approximate nearest neighbor (ANN) search index, optimized for deployment on personal devices that have limited resources. With the increasing demand for embedding-based search over locally stored personal data, traditional indexing methods often result in prohibitively high storage overhead. LEANN aims to address this challenge by reducing the index size while maintaining high retrieval performance and low latency.
System Design and Methodology
Graph-Based Structure and Recomputation Strategy
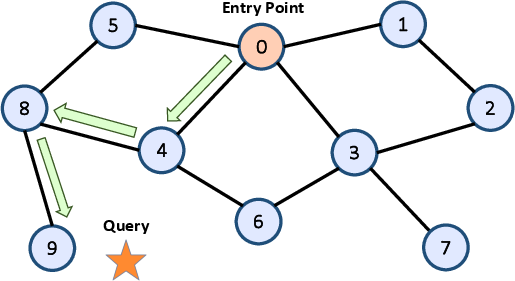
LEANN is designed to optimize both storage and computational efficiency. At its core, it employs a graph-based index structure inspired by the Hierarchical Navigable Small World (HNSW) model but introduces significant modifications:
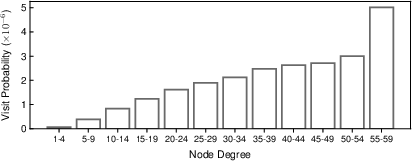
High-Degree Preserving Graph Pruning
To manage storage efficiently, LEANN applies a high-degree preserving graph pruning technique. This method involves selectively retaining high-degree nodes that are critical to search performance, while pruning redundant low-utility edges in the graph:
Optimizations for Latency
Dynamic Batching Mechanism
LEANN incorporates dynamic batching to enhance computational efficiency during query processing. By grouping recomputation tasks and leveraging GPU resources effectively, LEANN can reduce latency significantly:
LEANN's evaluation on real-world question answering benchmarks demonstrates impressive results:
- Storage Efficiency: LEANN achieves a drastic reduction in index size to under 5% of the original data size.
- Accuracy and Speed: Despite reduced storage, LEANN maintains 90% top-3 recall with query latency under 2 seconds, showcasing a significant advantage over conventional indices.
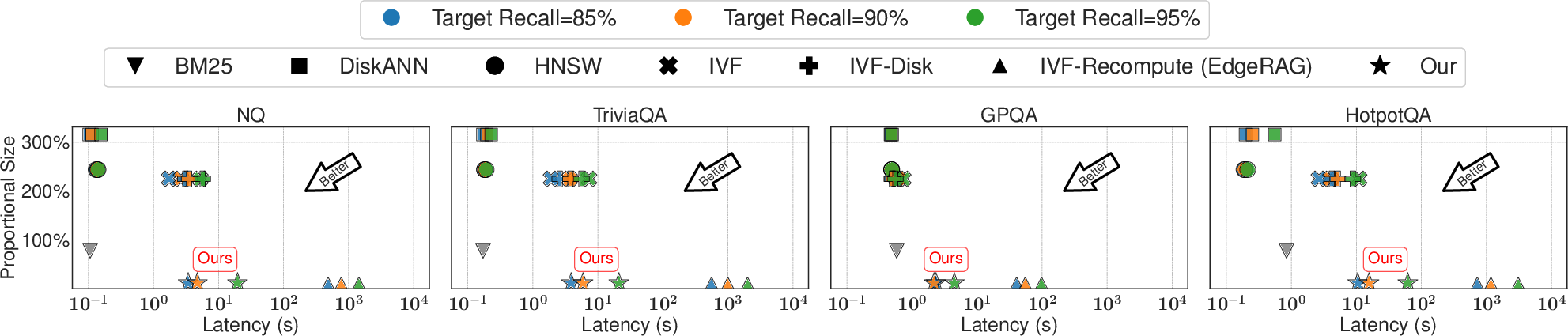

Figure 4: A10.
Ablation Studies
Detailed ablation experiments highlight the contribution of each component to LEANN's performance, particularly the impact of the graph pruning strategy and dynamic batching on latency and storage requirements.
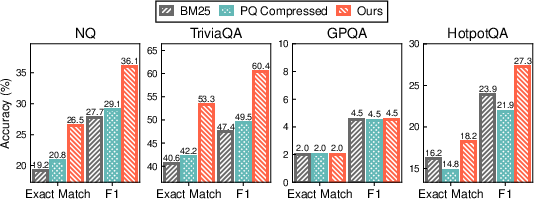
Figure 5: [Main Result]: Comparison of Exact Match and F1 scores for downstream RAG tasks across three methods: keyword search (BM25), PQ-compressed vector search, and our proposed vector search system. Our method is configured to achieve a target recall of 90%, while the PQ baseline is given extended search time to reach its highest possible recall. Here we use Llama-3.2-1B as the generation model.
Conclusion
LEANN presents a novel solution to the pressing challenge of storage-efficient vector search on personal devices. By integrating compact graph structures, on-the-fly recomputation, and tailored traversal algorithms, LEANN significantly lowers storage overhead while retaining high retrieval quality. As such, it opens new avenues for embedding-based search applications on edge devices, enabling personalized and responsive query handling even in resource-constrained environments. Future work could explore expanding these methodologies to other graph-based indices, further optimizing latency, and understanding the broader implications of these techniques in distributed scaling.