- The paper introduces CASE, a method that formulates exemplar selection as a top-m best arms identification problem using stochastic linear bandits.
- It significantly reduces computational cost by evaluating only a shortlist of candidate arms, achieving up to 7x runtime efficiency and 87% fewer LLM calls.
- The approach provides provable PAC guarantees and enables efficient prompt caching and exemplar reusability for scalable in-context learning.
Sample Efficient Demonstration Selection for In-Context Learning
The paper "Sample Efficient Demonstration Selection for In-Context Learning" (2506.08607) introduces CASE, a novel strategy for selecting optimal few-shot exemplars to maximize the efficacy of LLMs in in-context learning tasks.
Introduction to In-Context Learning
ICL allows LLMs to perform tasks conditioned on a context comprising demonstration examples without additional fine-tuning, making it an adaptable methodology. A key challenge is selecting effective few-shot examples within context-length constraints. Conventional strategies often rely on heuristics or computationally intensive methods.
The authors present exemplar selection as a top-m best arms identification problem, faced with an exponentially large number of arms. Utilizing stochastic linear bandits, the paper frames the task as selecting subsets that maximize validation accuracy under a predefined evaluation metric. This setup introduces a principled sampling approach, balancing exploration and exploitation.
CASE: Challenger Arm Sampling Strategy
CASE uses a selective exploration mechanism maintaining a shortlist of "challenger" arms. By reducing the sample complexity through selective exploration, only promising arms are evaluated, significantly decreasing LLM inference costs while preserving performance.
Challenger Arm Sampling:
Counter intuitively, rather than evaluating all possible exemplars, a shortlist approach significantly trims the candidate set, maintaining efficiency with theoretically grounded sampling.
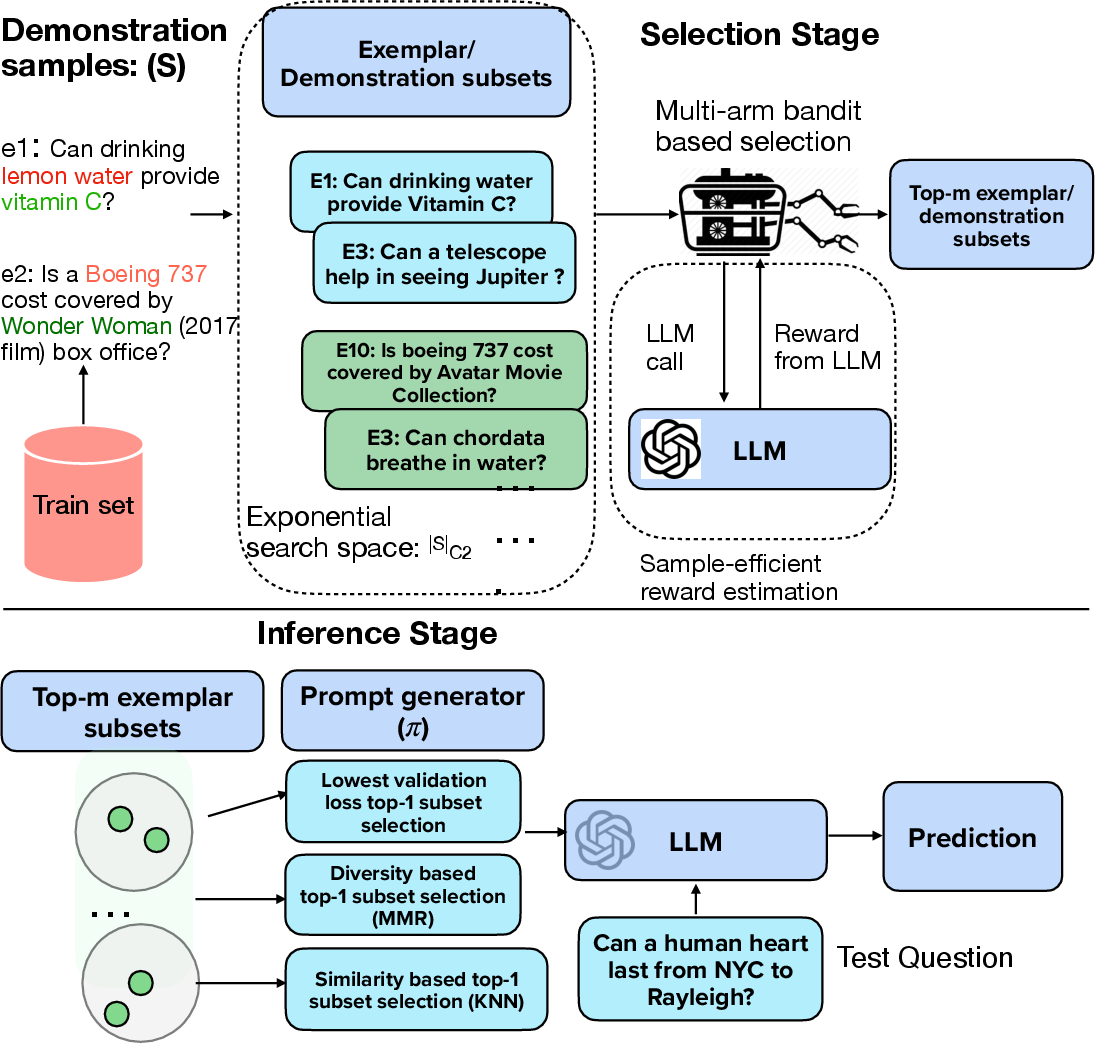
Figure 1: Overview of CASE for selection of top-m best exemplar subsets (arms).
Implementation Highlights
Algorithm Design
The paper describes a bespoke iterative selection procedure:
- Sample candidate arms and estimate parameters using efficient linear bandits methods.
- Employ adaptive sampling to update the list of top-m arms, iteratively refining the exemplar set.
- Utilize a gap-index and regret measurement to guide the sampling process for selecting promising exemplars with reduced computational overhead.
Computational Efficiency
CASE achieves up to 7x efficiency gains in runtime and 87% reduction in LLM calls compared to previous methods, making it viable for real-world applications on black-box LLMs.
- Reduced computational burden: Significantly fewer LLM calls translate into resource savings.
- Task performance: Maintains competitive results with state-of-the-art methods while offering substantial efficiency gains.
Theoretical Analysis:
Underpinned by PAC guarantees, CASE demonstrates robust performance with provable sample complexity bounds, ensuring top-m arms are reliably identified.
Practical Implications
The proposed method notably enhances the practical deployment of ICL:
- Prompt Caching: The static exemplar selection permits efficient prompt caching, reusing attention states beneficially in modular attention models.
- Exemplar Reusability: Exemplar selection from smaller models transfers well to larger LLMs, enhancing cost-effectiveness.
Future Prospects
Upcoming research could focus on extending CASE's application to adaptive retrieval environments or exploring robust prompt methodologies for complex QA scenarios.
Conclusion
CASE stands out in the field of exemplar-based in-context learning, advancing efficient strategies without compromising performance, thus paving the way for scalable implementation of LLMs in varied AI applications.