- The paper introduces RePO, which integrates off-policy replay data to enhance policy optimization in reinforcement learning for large language models.
- Experiments on benchmarks like GSM8K and AMC23 show that RePO consistently outperforms GRPO, delivering notable accuracy gains.
- RePO boosts data efficiency by increasing effective optimization steps by 48% with only a 15% rise in computational overhead.
Replay-Enhanced Policy Optimization: An Essay
Introduction
The paper "RePO: Replay-Enhanced Policy Optimization" introduces a novel approach in reinforcement learning (RL) to enhance the performance of LLMs on complex reasoning tasks. The Replay-Enhanced Policy Optimization (RePO) methodology aims to overcome the limitations of Group Relative Policy Optimization (GRPO) by incorporating off-policy data to improve data efficiency and diversity in training samples. This essay will explore the theoretical underpinnings, implementation details, and empirical evaluations presented in the paper.
Methods
The core idea of RePO is to extend GRPO by leveraging a replay buffer to integrate off-policy data into the RL framework. Unlike GRPO, which solely relies on on-policy samples for advantage estimation, RePO utilizes previously sampled outputs to enrich the data diversity. The replay buffer plays a critical role by storing outputs from past iterations, allowing the model to optimize its policy using a combination of on-policy and off-policy samples.
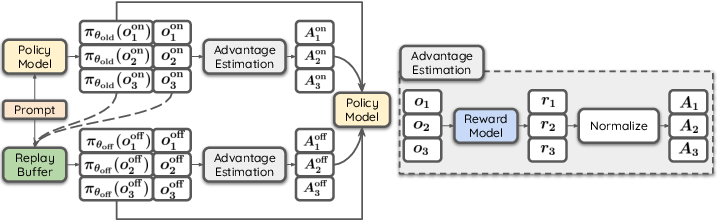
Figure 1: Demonstration of RePO. The policy is updated using both on-policy samples and off-policy samples retrieved from a replay buffer. Advantage estimation is performed separately for on-policy and off-policy updates.
The RePO objective function is formulated by combining both on-policy and off-policy terms, which allows for a more extensive set of outputs per prompt and better data efficiency. By integrating different replay strategies, such as recency-based or reward-oriented strategies, RePO can selectively retrieve samples that maximize the policy's learning potential.
Experiments and Results
RePO was evaluated against GRPO across multiple open-source LLMs, specifically targeting mathematical reasoning benchmarks such as GSM8K, Minerva, and AMC23. The experimental results demonstrate that RePO consistently outperforms GRPO, achieving significant absolute average performance gains across different model scales and tasks (Figure 2).
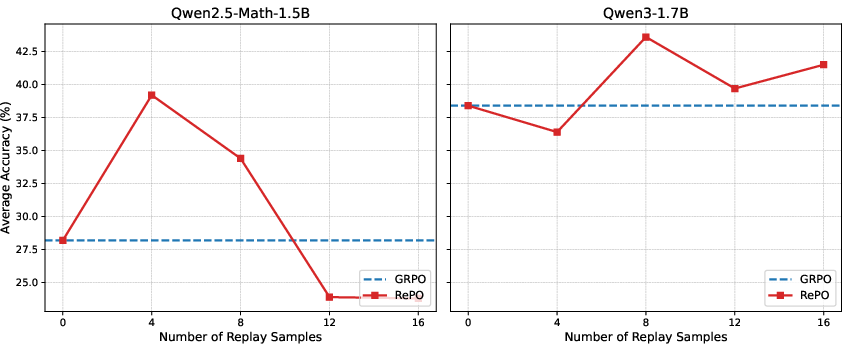
Figure 2: Comparison of average accuracy between GRPO and RePO under varying numbers of off-policy (Replay) samples across seven math reasoning benchmarks: GSM8K, MATH-500, Olympiad, Minerva, AIME24, AIME25, and AMC23, using Qwen2.5-Math-1.5B (left) and Qwen3-1.7B (right) with 8 on-policy samples.
In addition to performance improvement, RePO offers a computationally efficient solution. For instance, when applied to Qwen3-1.7B, RePO increased computational overhead modestly by 15% but significantly raised the number of effective optimization steps by 48%. This demonstrates not only its effectiveness but also its efficiency relative to the computational resources required.
Analysis and Discussion
Several factors contribute to the success of RePO. The diversity in replay strategies ensures that the most informative samples, particularly those aligning closely with the current policy or yielding high rewards, are prioritized. This strategic sampling mitigates common RL issues such as vanishing gradients, which are prevalent in models solely relying on on-policy data.
Furthermore, RePO's robust advantage estimation approach, which splits the calculation for on-policy and off-policy experiences, minimizes potential interference.
The paper also identifies limitations related to RePO's implementation on larger models and the exploration of hyperparameters. These limitations point to opportunities for further research, potentially broadening RePO's applicability and effectiveness.
Conclusion
The proposed Replay-Enhanced Policy Optimization significantly advances the RL optimization framework by addressing GRPO's limitations through the innovative use of off-policy samples. RePO effectively enhances the reasoning capabilities of LLMs, validating its potential for improving data efficiency and reducing overfitting. As LLMs continue to evolve, methods like RePO will be instrumental in driving future innovations in RL optimization.