- The paper introduces EAM, merging DRL with GA to enhance exploration and solution quality in Neural Combinatorial Optimization.
- It employs genetic operations like crossover and mutation alongside an autoregressive policy to overcome local optima and improve search efficiency.
- Experiments on TSP, CVRP, and related benchmarks demonstrate accelerated convergence and robust solution improvements.
Synergizing Reinforcement Learning and Genetic Algorithms for Neural Combinatorial Optimization
Introduction
This paper proposes the Evolutionary Augmentation Mechanism (EAM), merging Deep Reinforcement Learning (DRL) with Genetic Algorithms (GAs) to address challenges in Neural Combinatorial Optimization (NCO). It tackles the limitations of DRL, such as limited exploration and susceptibility to local optima, by integrating the global search capabilities of GAs. EAM is positioned as a model-agnostic module that can be integrated with state-of-the-art DRL solvers, promising enhanced exploration and accelerated convergence. The approach is tested against benchmark combinatorial optimization problems like TSP, CVRP, PCTSP, and OP, showing significant improvements.
Evolutionary Augmentation Mechanism
Overview
EAM integrates the learning efficiency of DRL with the exploratory capabilities of GAs. As illustrated in the framework (Figure 1), the mechanism involves generating initial solutions from the DRL policy, refining them through genetic operations like crossover and mutation, and reinjecting evolved solutions into the policy training loop.
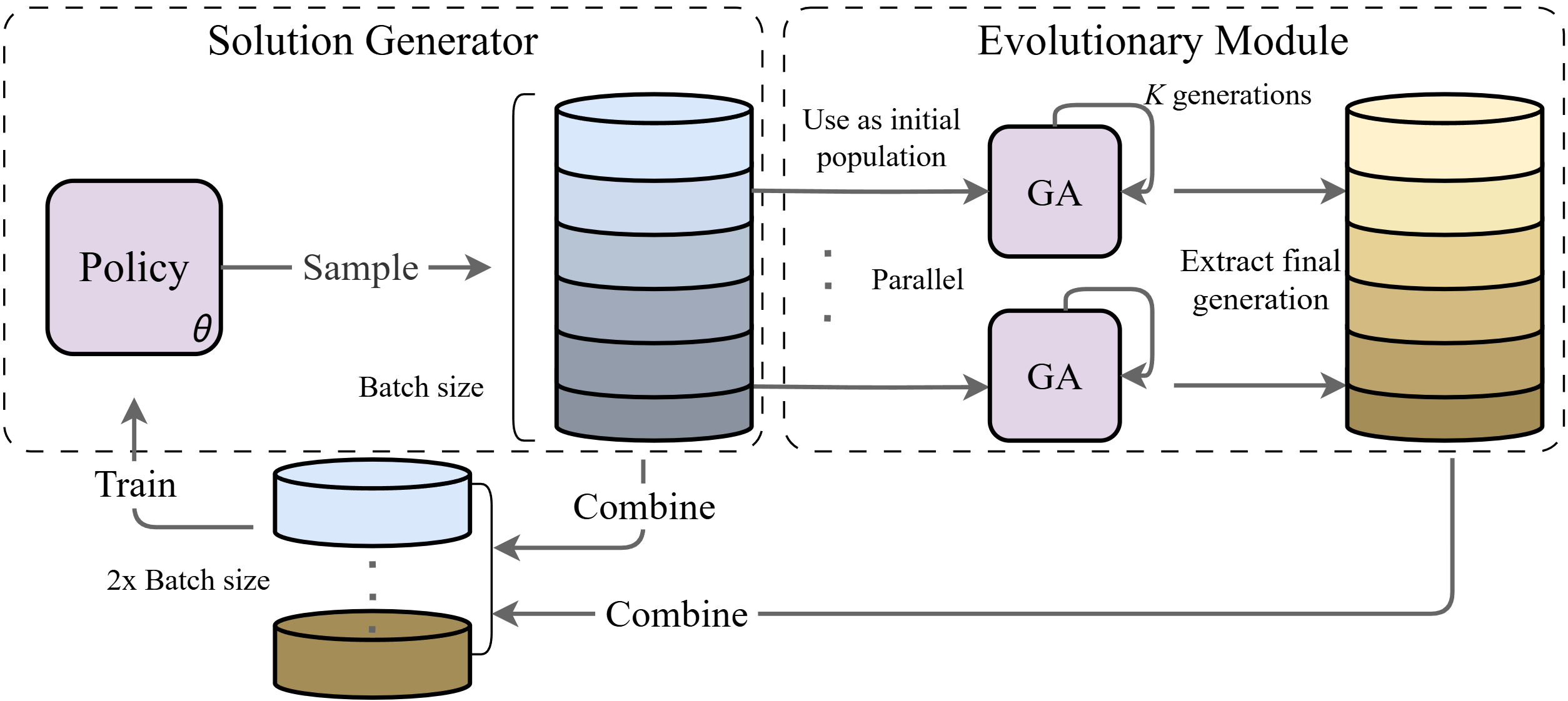
Figure 1: An overview of the proposed Evolutionary Augmentation Mechanism (EAM). Policy-sampled solutions are used to initialize the population of the Genetic Algorithm. The evolved solutions are then merged with the original samples and jointly used to train the policy network, forming a closed-loop learning and evolutionary framework.
Key Components and Process
- Solution Generation: The policy network, based on an autoregressive model, generates initial solutions. This initial population is fundamental for further GA-based refinement.
- Genetic Operations:
- Selection: An elitist strategy ensures that only the top-performing individuals undergo genetic operations, safeguarding computational efficiency while focusing on high-quality solutions.
- Crossover and Mutation: Genetic diversity is injected primarily via Order Crossover and task-specific mutation operations, which adapt to the structural characteristics of the problem space.
- Closed-loop Integration: EAM creates a feedback loop where the GA evolves solutions that improve the policy's exploration capability, and the policy accelerates GA by providing well-structured initial solutions.
Theoretical Considerations
The integration demands analyzing potential biases introduced by GA perturbations into the DRL policy. The paper introduces a theoretical framework based on KL divergence to quantify this effect, ensuring that the integration does not compromise on policy stability. Through detailed mathematical modeling, upper bounds are established, ensuring that even evolved solutions remain in close proximity to the DRL policy distribution, thereby preserving the integrity of training updates.
Experimental Evaluation
Extensive experiments across multiple COPs demonstrate EAM's proficiency. The method consistently enhances solution quality and accelerates convergence across all tested scenarios, including variations of TSP and CVRP across different scales.
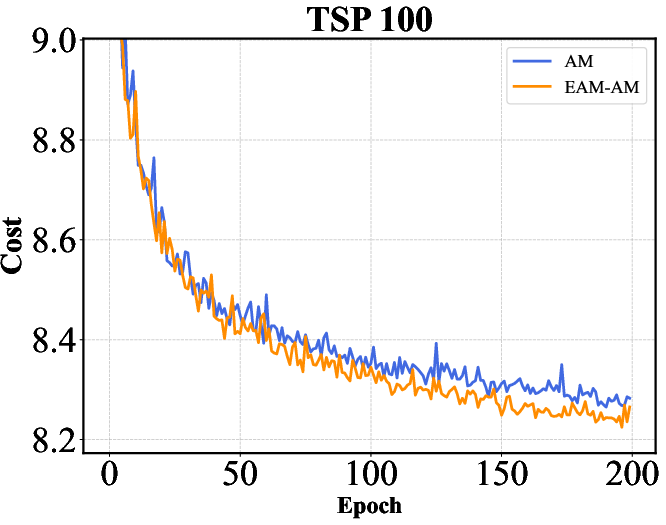
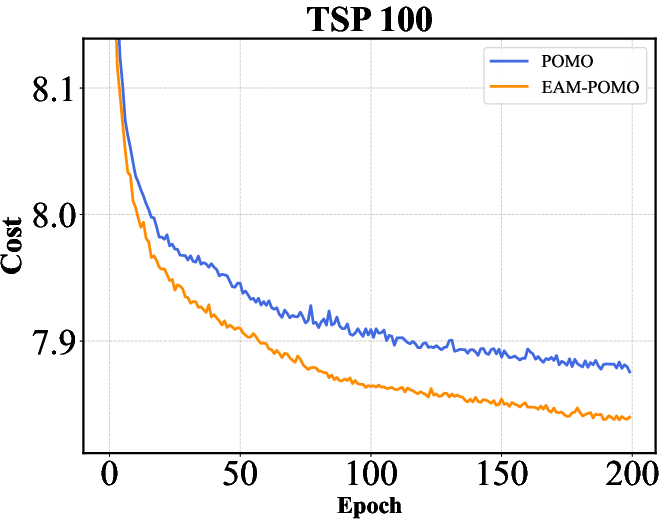
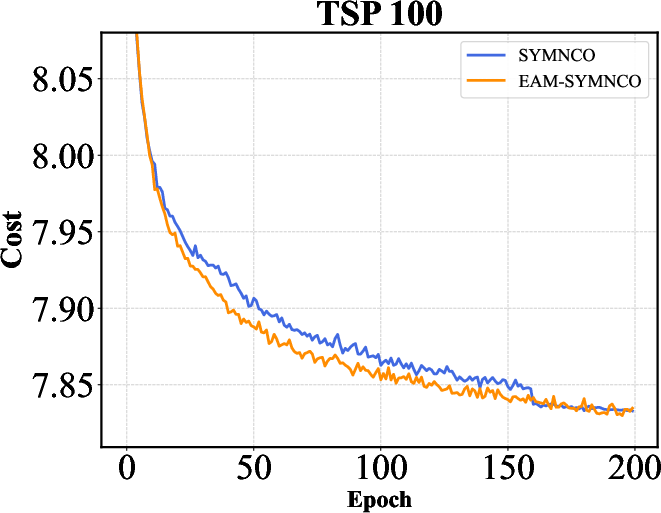
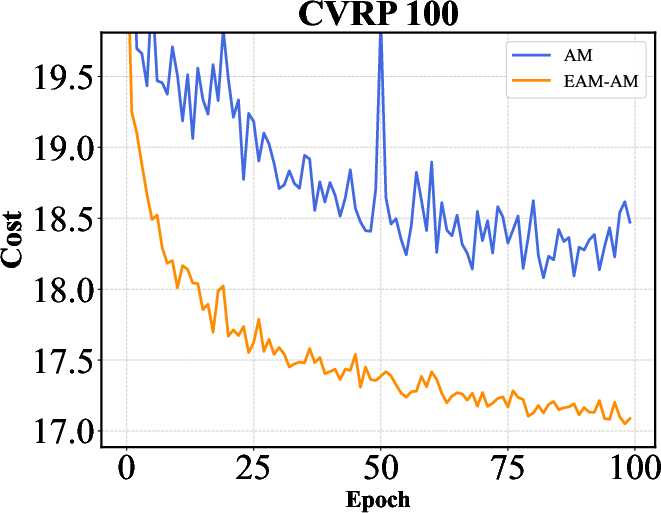
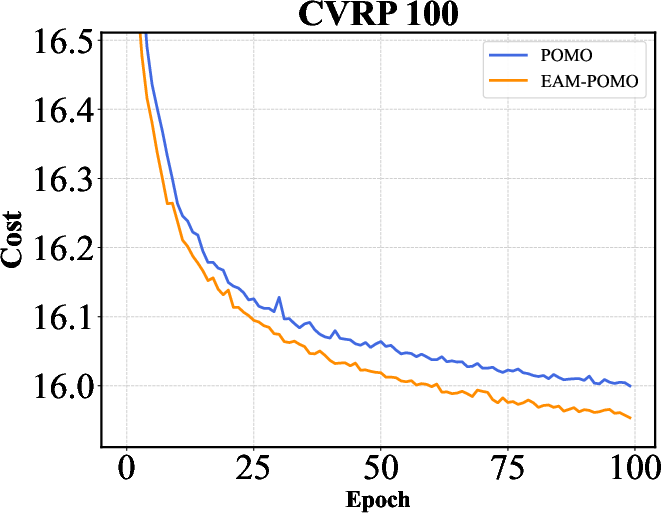
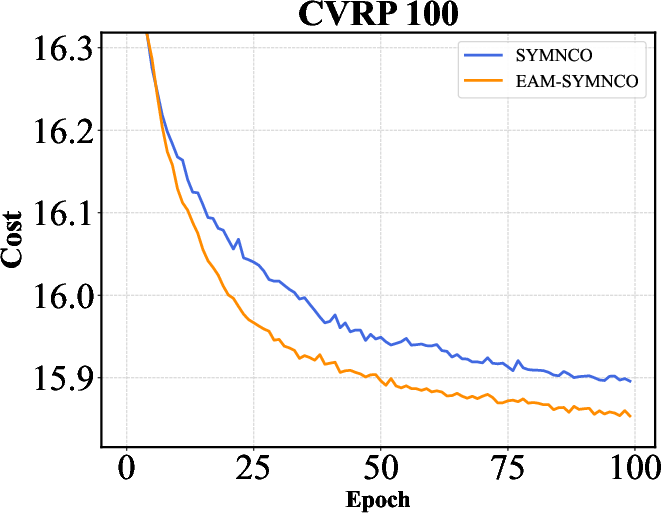
Figure 2: Training curves of AM, POMO, and Sym-NCO with and without EAM on TSP-100 and CVRP-100. EAM consistently accelerates convergence across different backbones and problem settings, highlighting its ability to improve training efficiency in addition to final solution quality.
The results indicate that EAM not only optimizes performance metrics like solution quality and computation time but also ensures robustness across different network architectures.
Implications and Future Directions
EAM's ability to seamlessly augment DRL solvers, enhancing both exploration and training efficiency, positions it as a versatile tool for solving NP-hard combinatorial problems. Future research could extend EAM to various other COPs outside the routing domain, each with unique structural constraints. Further exploration into dynamic evolutionary hyperparameter adjustments based on task-specific feedback could also enhance the framework's adaptability and performance.
Conclusion
The Evolutionary Augmentation Mechanism presents an innovative pathway for addressing the intrinsic limitations of DRL in solving NCO problems. By leveraging the complementary strengths of DRL and GAs, EAM achieves marked improvements in both solution quality and training efficiency, underscoring its potential as a transformative tool in combinatorial optimization research and applications.