- The paper introduces a diffusion-guided autoencoder that integrates a stochastic diffusion process into the decoder, improving reconstruction quality under high compression ratios.
- It replaces standard ℓ2 loss with a denoising score-matching loss, ensuring stable training and enhanced recovery of high-frequency image details.
- Experimental results demonstrate that DGAE outperforms GAN-based models in image reconstruction, scalability, and convergence speed, particularly with reduced latent dimensions.
Diffusion-Guided Autoencoder for Efficient Latent Representation Learning
Introduction
The paper presents a novel approach for latent representation learning with autoencoders, introducing the Diffusion-Guided Autoencoder (DGAE). This model employs a diffusion process to enhance the expressiveness of the decoder, aiming to achieve high-quality reconstruction under high spatial compression ratios while maintaining a smaller latent space than existing methods. The main objective of DGAE is to reconcile the trade-off between spatial compression and reconstruction fidelity in autoencoders, a challenge that often leads to training instability with Generative Adversarial Networks (GANs).
Encoder and Decoder Design
The architecture of DGAE retains the convolutional encoder framework consistent with models like SD-VAE. However, the diffusion process is integrated into the decoder's operation, transitioning from traditional deterministic decoding approaches to a novel stochastic generation process from Gaussian noise.
The kernel of the diffusion model in DGAE is its ability to produce high-quality reconstructions through a denoising process conditioned on a latent space representation, enhancing the reconstruction of high-frequency details. Crucially, unlike previous GAN-based approaches, DGAE uses diffusion models to provide stable training dynamics, thus circumventing issues like mode collapse and sensitivity to hyperparameters.
Implementation Details
DGAE leverages a denoising score-matching loss to replace the standard ℓ2 reconstruction loss, inherently improving the model's capability to decode latent representations into detailed, high-fidelity images. The loss function, combining score-matching and perceptual similarity objectives, guides the training process to maximize data likelihood while maintaining perceptual quality.
The diffusion process refines the decoder's function by progressively removing noise from an image sampled from the latent distribution, effectively transferring the diffusion model's data modeling strengths into the autoencoder framework.
Experimental Evaluation
Reconstruction Performance:
DGAE demonstrates exceptional performance in maintaining high reconstruction quality even when both spatial and latent compressions are high. The empirical results reveal its capability in generating images with superior structural details and textures compared to GAN-based counterparts.

Figure 1: Reconstructed samples of DGAE and SD-VAE. DGAE shows better recovery of fine-grained details.
Scalability and Efficiency:
The architecture scales effectively with increased decoder capacity, thus allowing it to capture additional intricate details (Figure 2). Additionally, the diffusion-based approach enables efficient training, preserving computational resources and accelerating convergence, especially observable at reduced latent sizes.

Figure 2: Scalability Evaluation of DGAE.
Latent Diffusion Model:
When applied to latent diffusion models for image synthesis, DGAE substantially benefits models like DiT-XL by facilitating faster convergence and maintaining high generation quality with a reduced latent size (Figure 3).
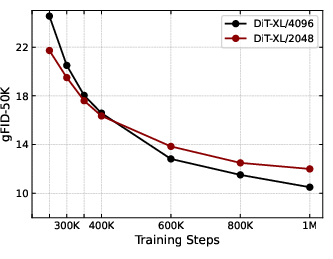
Figure 3: Convergence Curves of DiT-XL under Different Latent Sizes.
Conclusion
The introduction of Diffusion-Guided Autoencoder provides a robust framework for latent representation learning, addressing significant challenges in high-compression autoencoder applications. By leveraging the strengths of diffusion processes for decoder design, DGAE enhances training stability while improving the expressiveness of latent representations. Future research could extend this work by exploring further the hierarchical integration of diffusion processes to other aspects of visual data modeling, potentially broadening its applicability in diverse generative tasks.