Feature Engineering for Agents: An Adaptive Cognitive Architecture for Interpretable ML Monitoring
Abstract: Monitoring Machine Learning (ML) models in production environments is crucial, yet traditional approaches often yield verbose, low-interpretability outputs that hinder effective decision-making. We propose a cognitive architecture for ML monitoring that applies feature engineering principles to agents based on LLMs, significantly enhancing the interpretability of monitoring outputs. Central to our approach is a Decision Procedure module that simulates feature engineering through three key steps: Refactor, Break Down, and Compile. The Refactor step improves data representation to better capture feature semantics, allowing the LLM to focus on salient aspects of the monitoring data while reducing noise and irrelevant information. Break Down decomposes complex information for detailed analysis, and Compile integrates sub-insights into clear, interpretable outputs. This process leads to a more deterministic planning approach, reducing dependence on LLM-generated planning, which can sometimes be inconsistent and overly general. The combination of feature engineering-driven planning and selective LLM utilization results in a robust decision support system, capable of providing highly interpretable and actionable insights. Experiments using multiple LLMs demonstrate the efficacy of our approach, achieving significantly higher accuracy compared to various baselines across several domains.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple Explanation of the Paper
Overview
This paper introduces a smart helper system, called CAMA, that keeps an eye on ML models after they’ve been deployed in the real world. Its goal is to turn confusing monitoring numbers into clear, easy-to-understand reports that help people decide what to do next, like retrain a model or fix a data pipeline.
Think of it like a coach that watches a team (the ML model), studies game stats (monitoring tools), and writes a clear game summary with practical advice.
Key Objectives
The paper asks three main questions:
- Can we use modern AI (LLMs, or LLMs) to explain ML monitoring results in plain, useful language?
- Can we make those explanations more reliable by organizing the information better before the AI analyzes it?
- Does this approach work well across different kinds and sizes of AI models and in different problem areas?
Methods and Approach
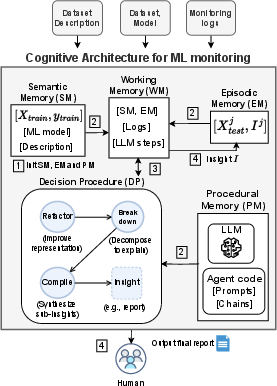
The authors build an “adaptive cognitive architecture” — basically, a structured way for an AI agent to think — and apply feature engineering ideas to the agent’s process. Feature engineering is the practice of cleaning and organizing data so models can understand it better. Here, they use it to help the AI agent understand monitoring outputs better.
They focus on two parts:
The memory modules
The system uses four kinds of “memory,” similar to how people remember things:
- Procedural Memory: The “how-to” instructions and code the agent uses.
- Episodic Memory: Notes from past monitoring sessions, like test data and previous reports.
- Semantic Memory: General knowledge about the training data, the ML model, and tools (like what features mean).
- Working Memory: The “scratchpad” for whatever the agent is currently analyzing.
This setup helps the agent stay organized, avoid noise, and remember what matters.
The 3-step decision procedure
To turn raw monitoring outputs into a clear report, the agent follows three steps:
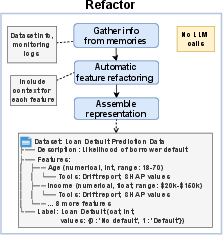
- Refactor: Reorganize the information so important parts stand out and irrelevant details are minimized. Think of it like tidying a messy desk before you start homework.
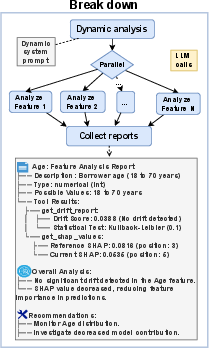
- Break Down: Analyze each feature or signal separately and in parallel. It’s like looking at every part of a bike to see which piece is squeaking.
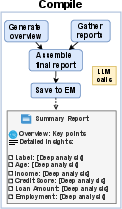
- Compile: Combine all the mini-insights into one clear report with summaries and actionable recommendations.
This flow reduces the need for the AI to “make up” planning steps and makes its analysis more consistent and understandable.
What They Tested
The team ran experiments using different LLMs (from small to large) and three datasets that represent real-world situations where data can change over time (called “distribution drift”):
- Loan Default Prediction (easy)
- Eligibility Simulation (medium)
- Chronic Condition Prediction (hard)
They used standard monitoring tools (like drift scores and SHAP values, where SHAP scores tell you how much each input feature affected a model’s prediction) and compared their method against popular prompting strategies (like Chain of Thought, Reflection, ReAct, and more).
They measured:
- Accuracy: How often the agent’s report matched the ground truth.
- Unknown ratio: How often the agent said “I don’t know.”
- Tokens: How long the reports were.
- Time: How long it took to generate the reports.
Main Findings and Why They Matter
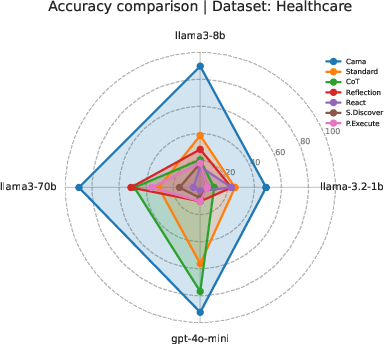
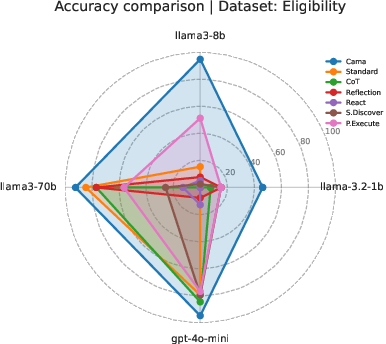
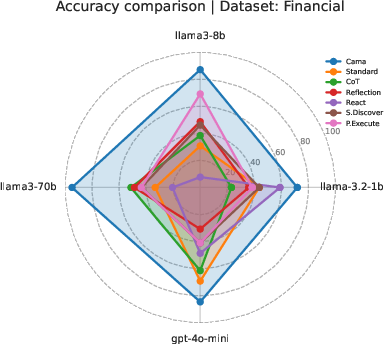
The results show that CAMA consistently produced more accurate, more complete, and more useful reports than other methods, across different model sizes and datasets.
Highlights:
- With a large model (llama3-70b), CAMA reached about 92% accuracy, while the next best method was around 59%.
- With a medium model (llama3-8b), CAMA hit about 91% accuracy, far above the others.
- Even with a small model (llama-3.2-1b), CAMA did much better than the alternatives.
- CAMA had very low “I don’t know” rates, meaning it gave confident, informative answers.
They also did an “ablation study” (removing parts to see what breaks) and found all three steps (Refactor, Break Down, Compile) are necessary. Taking out any step caused big drops in accuracy, especially removing Refactor or Break Down.
Why this matters:
- Teams can trust the monitoring summaries more.
- Reports are easier to understand, so decisions like “retrain now” or “collect new data” become clearer.
- The system works well even with smaller, cheaper models, which is useful in limited-resource settings.
Implications and Potential Impact
This approach can make day-to-day ML monitoring faster, clearer, and more reliable. It helps:
- Reduce the workload for engineers and data scientists who currently need to interpret complex metrics.
- Catch problems earlier when data in the real world changes over time (drift), which can prevent bad predictions.
- Support multi-agent setups where one agent detects a problem and another suggests fixes.
Limitations and future work:
- The tests used specific datasets and tools, so more testing across different domains would be helpful.
- It can take longer and use more tokens than simpler methods; future improvements could make it faster and more efficient.
Overall, CAMA offers a practical, LLM-agnostic way to turn technical monitoring outputs into understandable advice, helping organizations keep their ML models healthy and trustworthy.
Collections
Sign up for free to add this paper to one or more collections.