- The paper introduces a drawing-to-reason-in-space paradigm enabling LVLMs to interleave language and visual drawing operations for improved spatial reasoning.
- It proposes a three-stage training framework including supervised learning, reflective rejection sampling, and reinforcement learning with structure-aware rewards.
- ViLaSR achieves notable accuracy gains—such as 98.2% on MAZE—demonstrating robust spatial tracking and geometric reasoning across multiple benchmarks.
Reinforcing Spatial Reasoning in Vision-LLMs with Interwoven Thinking and Visual Drawing
Motivation and Limitations of Text-Centric Multimodal Reasoning
Current LVLMs achieve high performance on tasks such as image perception and basic VQA but fundamentally underperform in spatial reasoning, which requires explicit tracking of spatial relations, continuous geometric manipulations, and temporal or multi-view integration. State-of-the-art LVLMs—including models augmented with chain-of-thought or least-to-most reasoning—largely restrict their reasoning to text, even when grounded in visual modalities. This assumption of perfect translation from visual to textual space does not hold for complex geometric reasoning, leading to information loss and inherent limitations on spatial reasoning accuracy.
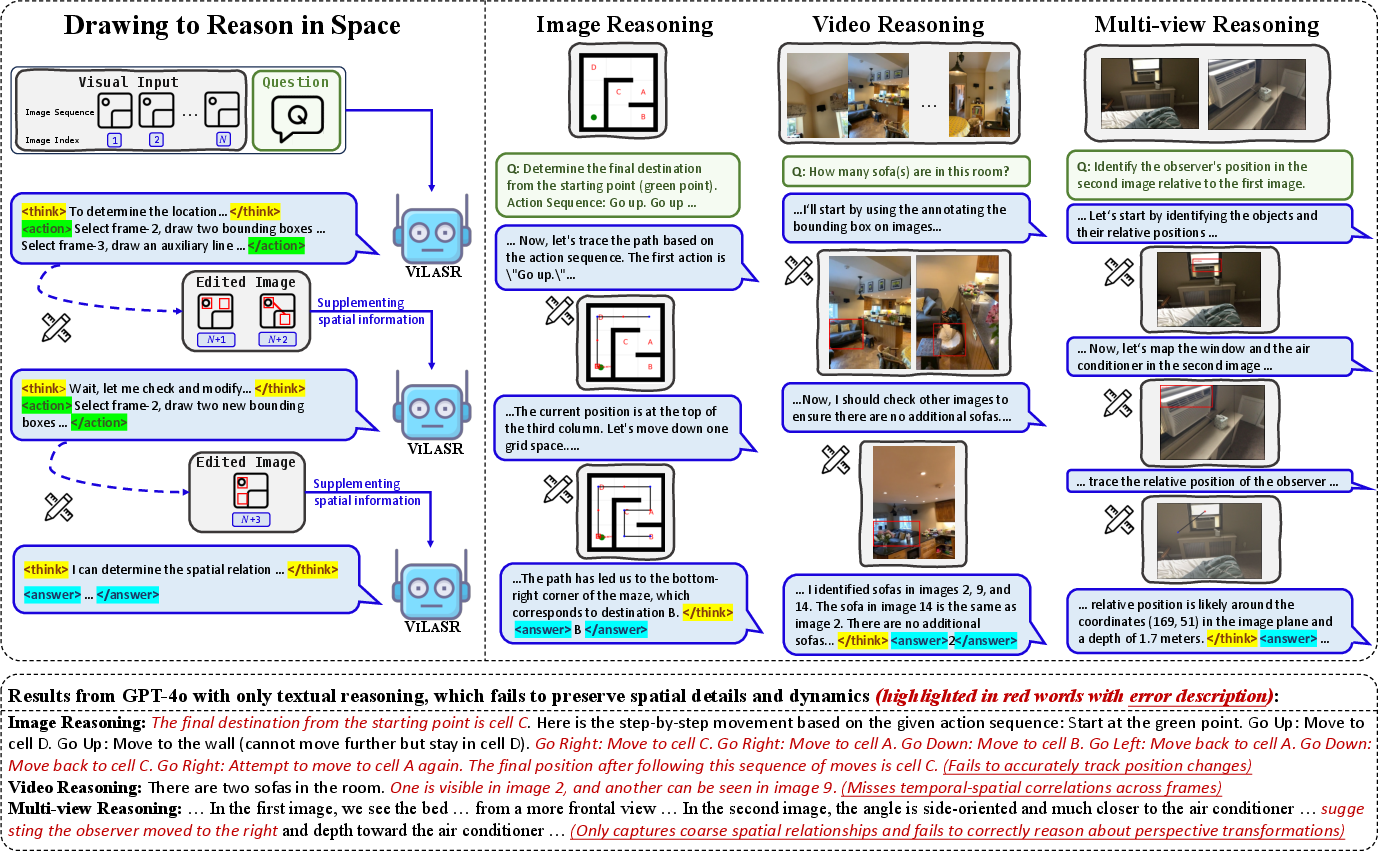
Figure 1: Illustration of the "drawing to reason in space" paradigm, with ViLaSR decomposing complex spatial reasoning into interpretable visual steps and comparison to GPT-4o’s solely textual reasoning.
The Drawing-to-Reason-in-Space Paradigm
To directly address the inadequacies of text-dominant multimodal reasoning, the paper introduces the drawing-to-reason-in-space paradigm. This framework allows LVLMs to interleave language-based explanations with elementary visual drawing operations—specifically, bounding box annotations and auxiliary line drawings. Each step in the reasoning chain can reference and manipulate visual context, with outputs modifying the visual modality itself and subsequent reasoning steps building on these updated images.
The resultant multi-step reasoning trajectory R={(rt,et,ot)}t=1T integrates natural language reasoning rt, visual tool operations et, and output images or overlays ot at each stage. This explicit visual grounding of abstract relations enables transparent decomposition of spatial problems, step-wise execution, and error correction that mimics human cognitive processes for spatial reasoning.
Three-Stage Training Framework for Visual Spatial Reasoning
To realize the proposed paradigm, the authors design a three-stage training protocol that progressively cultivates spatial reasoning capacity in LVLMs:
- Cold-start Supervised Training: Models are bootstrapped for visual drawing operations using synthetic data with curated annotation and reasoning trajectories across both single-image and video regimes.
- Reflective Rejection Sampling: To induce self-correction and reflection behaviors, the model is finetuned exclusively on samples that both yield correct answers and exhibit reflectivity—i.e., revisiting and revising prior annotations or chains.
- Reinforcement Learning with Structure-Aware Rewards: Finally, RL is applied with a composite reward signal that combines answer correctness and reasoning format validity, using the GRPO algorithm for policy optimization.
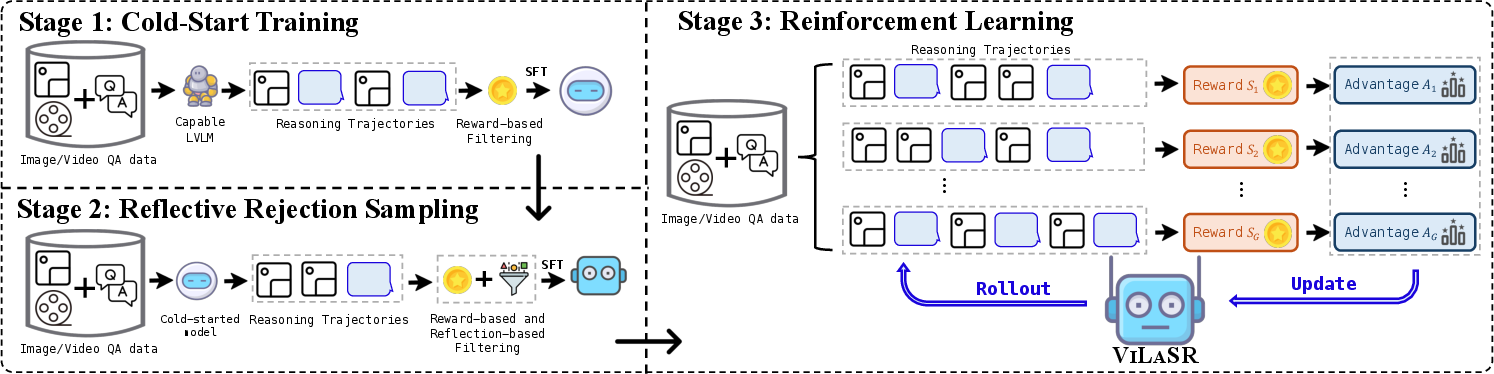
Figure 2: The three-stage ViLaSR training pipeline, encompassing supervised, reflective, and reinforcement learning phases.
This design ensures the model not only learns visual tool affordances and their use in spatial tasks, but also internalizes behaviors for iterative self-verification and efficient, interpretable spatial manipulation.
Empirical Results and Numerical Analysis
ViLaSR, constructed atop Qwen2.5-VL-7B, demonstrates substantial advances over both proprietary and open-source baselines across a comprehensive suite of spatial reasoning benchmarks: MAZE (path planning), SpatialEval-Real (object and scene spatial relations), VSI-Bench (temporal-spatial video reasoning), SPAR-Bench, and MMSI-Bench (multi-image, multi-view integration). Key results include:
- Average accuracy improvement of 18.4% over previous best open-source methods.
- On MAZE navigation, ViLaSR achieves 98.2% accuracy, a 64.5% absolute increase over the base model.
- On VSI-Bench video reasoning, ViLaSR outperforms competitive open-source LVLMs by 12.7%.
Notably, ablation studies underscore the critical roles of each training stage: removal of reflective sampling drastically reduces self-correction and results in impaired performance on tasks requiring object localization or measurement. RL further optimizes response efficiency and measurement precision, particularly for numerical queries; its absence causes noticeably more verbose, inefficient reasoning chains and reduces measurement accuracy.
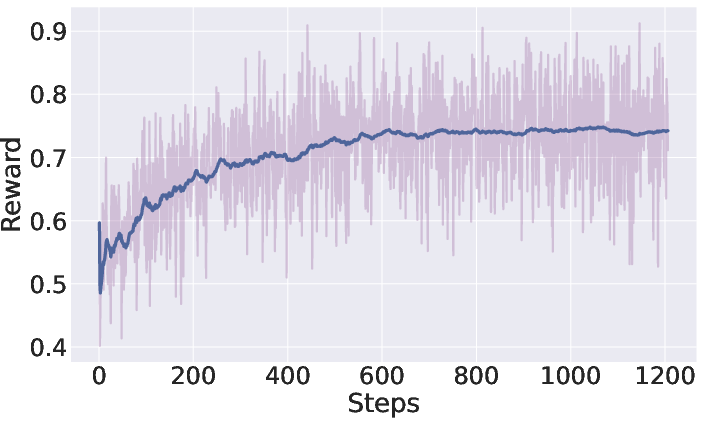
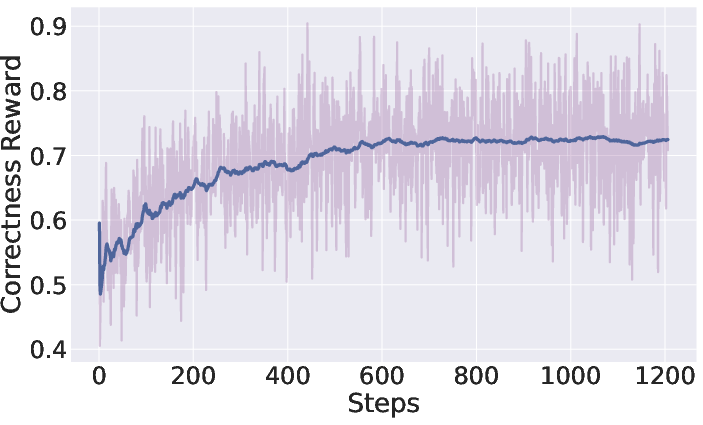
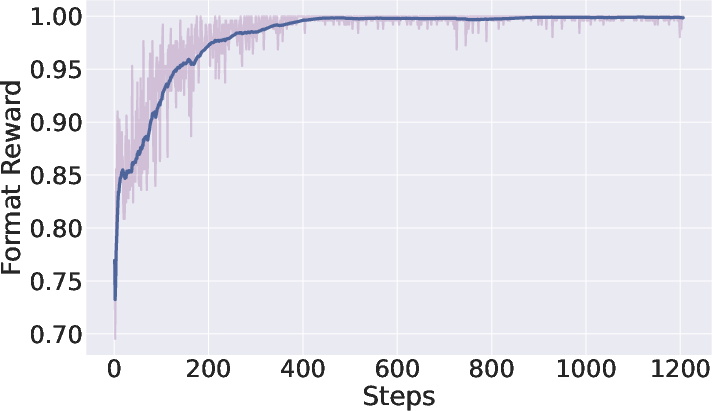
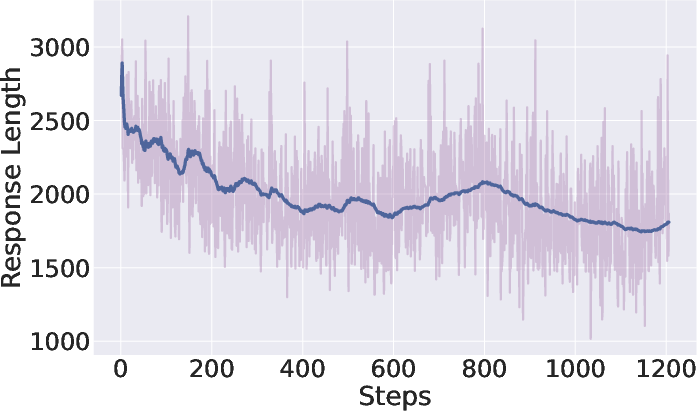
Figure 3: Reward and behavioral dynamics for ViLaSR during reinforcement learning—the model achieves increased reward while reducing redundant chain length, reflecting improved efficiency.
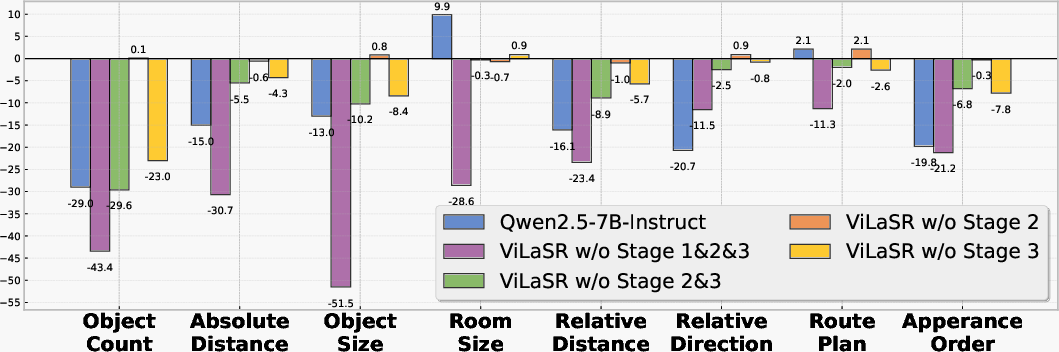
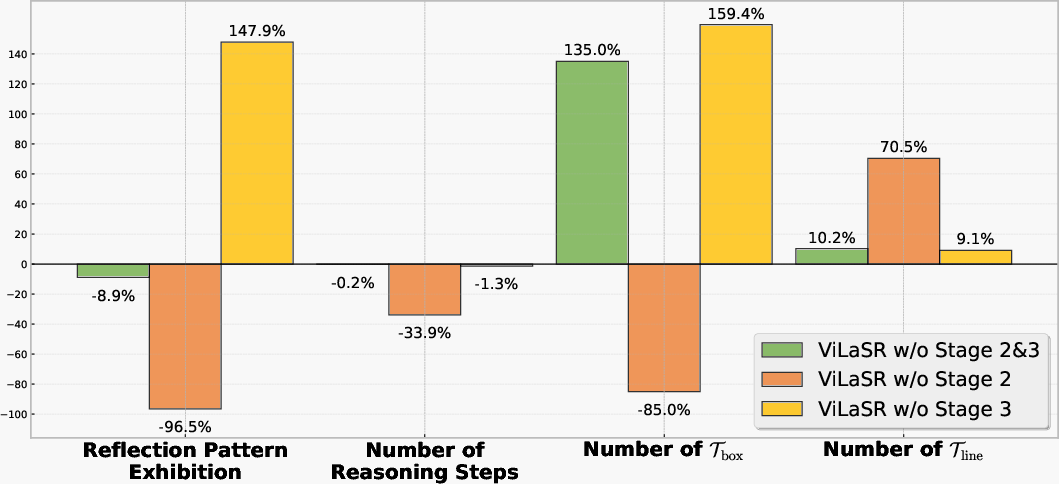
Figure 4: Impact of training stages on sub-tasks in VSI-Bench demonstrates reflection and RL are necessary for high accuracy, especially in measurement-centric reasoning.
Extensive case-study visualizations on maze, multi-view, and temporal video benchmarks further validate ViLaSR’s ability to make interpretable, visual, stepwise deductions unmet by text-only models.
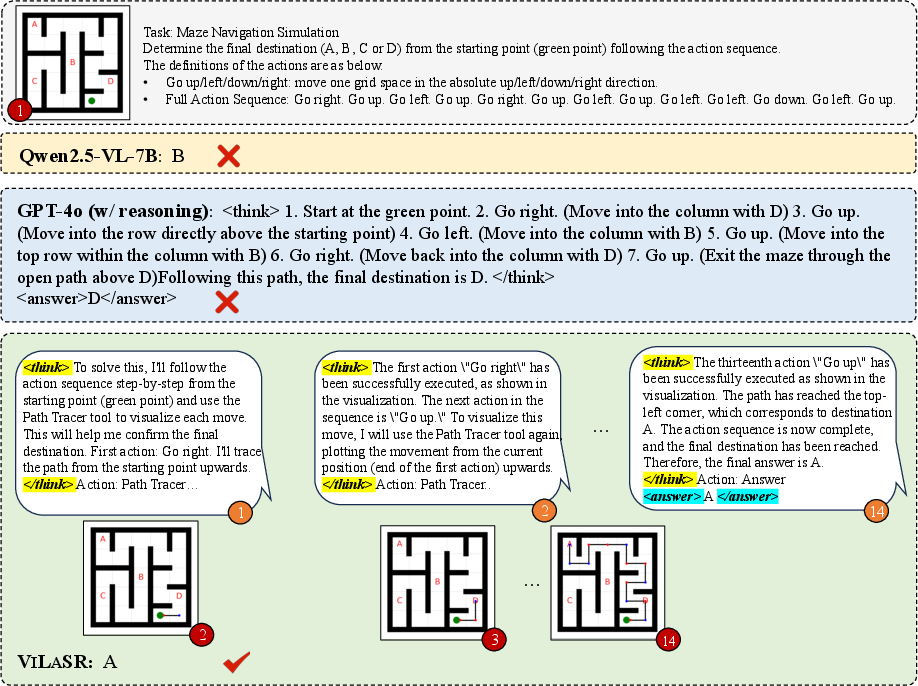
Figure 5: Comparison of stepwise spatial tracing in MAZE between Qwen2.5-VL-7B, GPT-4o, and ViLaSR; only ViLaSR reliably tracks and visualizes spatial state transitions.

Figure 6: Multi-view SPAR-Bench: ViLaSR leverages object annotation and path tracing, yielding correct perspective reasoning in contrast to baseline errors.

Figure 7: VSI-Bench example: ViLaSR exhibits explicit reflection behavior, revising and rechecking spatial annotations, leading to robust measurement and answer accuracy.
Theoretical and Practical Implications
By enabling LVLMs to express, verify, and revise spatial relationships and operations in a visual modality, ViLaSR overcomes the intrinsic ceiling imposed by language-only reasoning on spatial tasks. This paradigm offers direct benefits for downstream applications in embodied AI, robotics, AR/VR systems, and any domain where spatial/temporal visual reasoning is paramount.
Methodologically, the interleaving of visual tool-use and language, coupled with reward-driven consolidation of efficient reasoning patterns, sets a new best practice for developing open-source LVLMs competitive with proprietary models on advanced spatial intelligence.
The observed strong gains in tasks involving measurement, dynamic spatial tracking, and multi-view integration indicate the approach is especially suited for real-world decision-making, planning under uncertainty, and spatial information fusion scenarios. The framework’s modularity lends itself to further extensions with additional visual tools—such as semantic segmentation, 3D annotation, or real-world manipulation affordances—and future work may also generalize to multi-agent or distributed reasoning contexts.
Conclusion
ViLaSR introduces a theoretically principled and empirically validated paradigm for spatial reasoning in LVLMs, founded on iterative interwoven drawing and thinking. By training models to reflectively edit and ground their reasoning in visual space, the model achieves state-of-the-art results and demonstrates behaviors crucial for robust, interpretable spatial intelligence. The drawing-to-reason-in-space framework provides a clear path for further research in multimodal reasoning architectures and for bridging the gap between current LVLMs and human-level visual-geometric cognition (2506.09965).