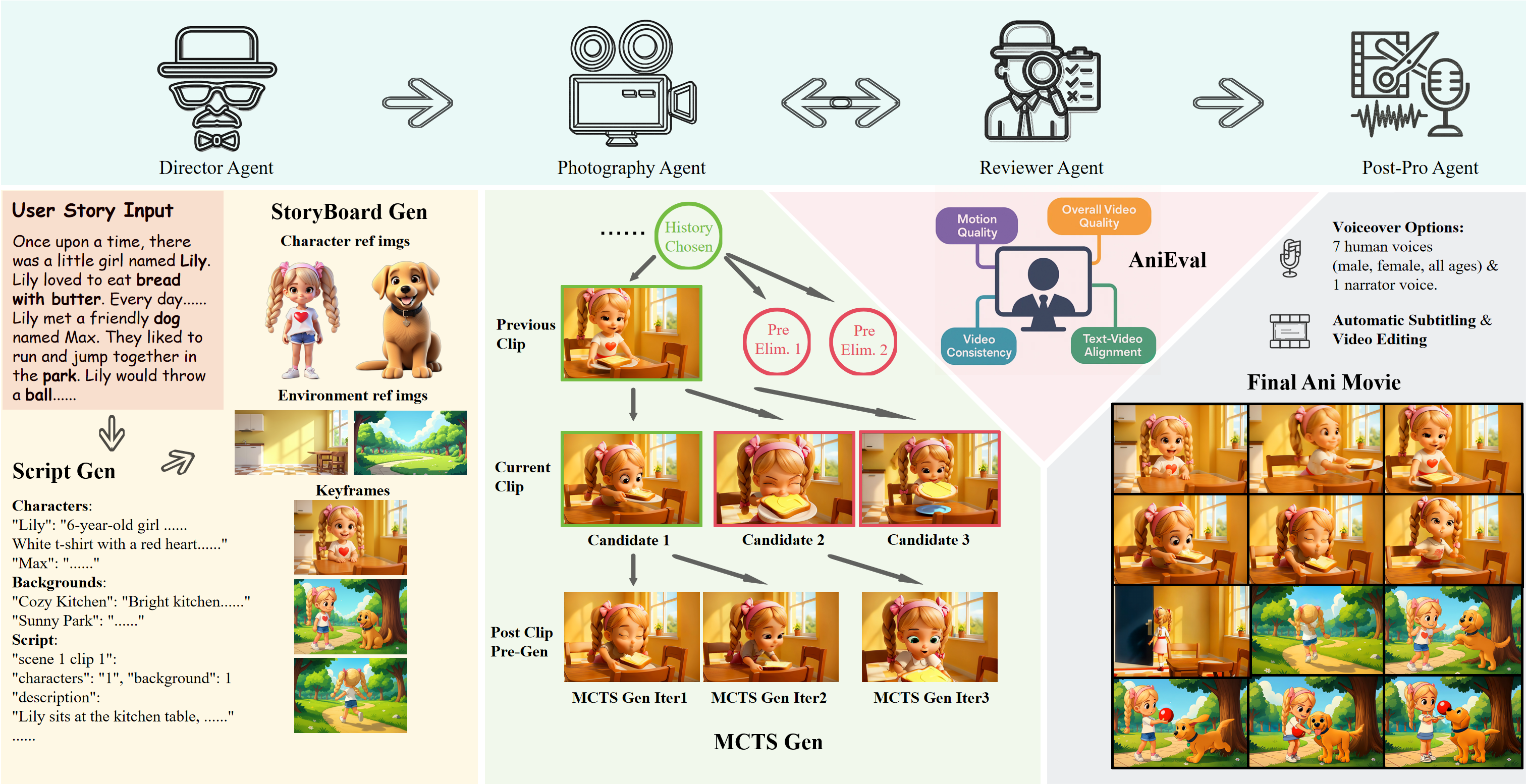
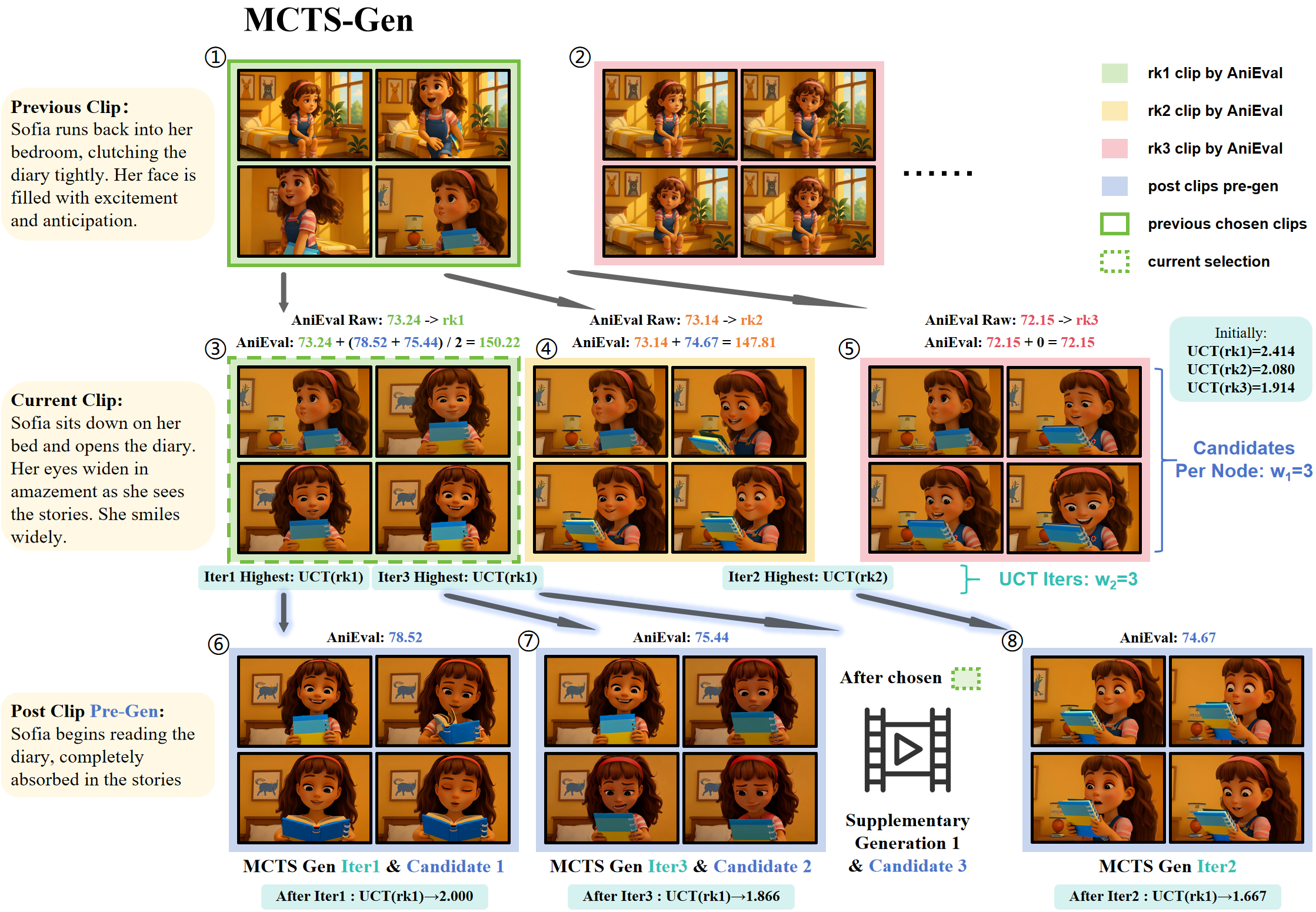
AniMaker: Automated Multi-Agent Animated Storytelling with MCTS-Driven Clip Generation
Abstract: Despite rapid advancements in video generation models, generating coherent storytelling videos that span multiple scenes and characters remains challenging. Current methods often rigidly convert pre-generated keyframes into fixed-length clips, resulting in disjointed narratives and pacing issues. Furthermore, the inherent instability of video generation models means that even a single low-quality clip can significantly degrade the entire output animation's logical coherence and visual continuity. To overcome these obstacles, we introduce AniMaker, a multi-agent framework enabling efficient multi-candidate clip generation and storytelling-aware clip selection, thus creating globally consistent and story-coherent animation solely from text input. The framework is structured around specialized agents, including the Director Agent for storyboard generation, the Photography Agent for video clip generation, the Reviewer Agent for evaluation, and the Post-Production Agent for editing and voiceover. Central to AniMaker's approach are two key technical components: MCTS-Gen in Photography Agent, an efficient Monte Carlo Tree Search (MCTS)-inspired strategy that intelligently navigates the candidate space to generate high-potential clips while optimizing resource usage; and AniEval in Reviewer Agent, the first framework specifically designed for multi-shot animation evaluation, which assesses critical aspects such as story-level consistency, action completion, and animation-specific features by considering each clip in the context of its preceding and succeeding clips. Experiments demonstrate that AniMaker achieves superior quality as measured by popular metrics including VBench and our proposed AniEval framework, while significantly improving the efficiency of multi-candidate generation, pushing AI-generated storytelling animation closer to production standards.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Practical Applications
Practical Applications of AniMaker’s Findings, Methods, and Innovations
Below, we translate the paper’s contributions (multi-agent pipeline, MCTS-Gen search for candidate clips, and AniEval for multi-shot evaluation) into concrete, real-world applications across sectors. Each bullet notes sector(s), potential tools/products/workflows, and assumptions/dependencies impacting feasibility.
Immediate Applications
These can be deployed with today’s models and infrastructure, leveraging the paper’s multi-agent framework, MCTS-Gen, and AniEval largely as-is.
- Studio and indie previsualization (previs) and animatics
- Sectors: film/TV/animation, gaming
- Tools/workflows: “Director Agent” for script-to-storyboard, “Photography Agent” with MCTS-Gen for multiple candidate shots, “Reviewer Agent” (AniEval) to select best takes; integrations with ShotGrid, Adobe Premiere/After Effects, Blender/Unreal for previs
- Assumptions/dependencies: access to LMMs and video generators (e.g., GPT-4o/Gemini/Wan), clear art direction assets (Character/Background Banks), GPU budget for multi-candidate search, IP clearance of assets
- Marketing and ad creative at scale (A/B/C testing via Best-of-N)
- Sectors: advertising, e-commerce
- Tools/workflows: MCTS-Gen for budgeted exploration of variants; AniEval to rank narratives for coherence and motion; Post-Production Agent for rapid voiceover/subtitle localization
- Assumptions/dependencies: brand asset libraries and approvals, voice licensing, content moderation and safety filters
- One-click “script-to-short” for creators and social media teams
- Sectors: creator economy, media platforms
- Tools/products: SaaS “Story-to-Animation” web app; preset character/background packs; “Continuity Guard” (AniEval preset thresholds) for platform-ready QC
- Assumptions/dependencies: platform ToS compliance (e.g., synthetic media disclosure), compute quotas, default moderation pipelines
- Corporate learning and development (scenario-based training)
- Sectors: enterprise L&D, compliance
- Tools/workflows: templates for safety, DEI, and compliance narratives; character-consistent training series; AniEval-driven QA to ensure cross-module continuity
- Assumptions/dependencies: legal review for regulated domains; accuracy alignment with policy; version control over scripts and updates
- K–12 and higher-ed explainers and micro-lectures
- Sectors: education
- Tools/products: teacher avatar packs, curriculum-aligned storyboard templates; multilingual TTS via Post-Production Agent; LMS plug-ins (SCORM/xAPI export)
- Assumptions/dependencies: factual accuracy checks (human-in-the-loop), age-appropriate content filters, accessibility standards (captions, transcripts)
- Cutscene and quest-line pre-production for games
- Sectors: gaming
- Tools/workflows: “Storyboard-to-Cutscene” pipeline; MCTS-Gen to explore cinematic beats; AniEval to maintain character and action consistency across multi-shot sequences
- Assumptions/dependencies: engine integration (Unreal/Unity), asset style alignment, IP/lore constraints
- Automated localization and dubbing for multi-language distribution
- Sectors: media localization, education, marketing
- Tools/workflows: Post-Production Agent for TTS/VO, subtitle generation and sync; batch pipelines for multi-market delivery
- Assumptions/dependencies: lip-sync is approximate unless paired with additional tools; language coverage and voice quality vary by TTS model
- QA and continuity checking for AI videos and UGC
- Sectors: platforms, studios, post-production houses
- Tools/products: “AniEval QA Dashboard” (plugins for Premiere/Davinci); batch validation for multi-shot coherence, character/face consistency, object count stability
- Assumptions/dependencies: calibrating AniEval thresholds per style (anime vs realistic); retraining Face Consistency for non-anime domains
- Compute budget optimization for generative pipelines
- Sectors: cloud/AI ops, studios, SaaS
- Tools/workflows: “MCTS-Gen Scheduler” to allocate generations to promising branches; per-shot w1/w2 settings; telemetry for cost/quality tradeoffs
- Assumptions/dependencies: operator expertise to tune exploration-exploitation; predictable API costs and rate limits
- Synthetic video data generation for CV/ML research
- Sectors: academia, software/AI
- Tools/workflows: data factory producing multi-shot, multi-character, labeled sequences (actions, objects); AniEval as QC gate before dataset release
- Assumptions/dependencies: domain gap to real-world footage; licensing clarity for generated data; reproducible seeds and metadata capture
- Benchmarks and evaluation research
- Sectors: academia, standards
- Tools/products: AniEval as an open-source library to complement VBench for multi-shot tasks; leaderboards for story coherence, action completion
- Assumptions/dependencies: publicly released code/models; community adoption; careful metric validation to avoid overfitting to scores
- Public information and NGO campaigns (low-cost explainers)
- Sectors: public sector, NGOs
- Tools/workflows: templated PSAs; multilingual voiceovers; quick-turn production for health/safety messaging
- Assumptions/dependencies: human review for factuality; cultural sensitivity; policy compliance for synthetic media labeling
- Personalized children’s storytelling
- Sectors: consumer/daily life, edtech
- Tools/products: parent-friendly app for bedtime stories; user-provided character photos converted to consistent avatars; safe-mode content filters
- Assumptions/dependencies: strict safety policies, content controls, privacy-by-design for child data
Long-Term Applications
These require further research, scaling, or improved model capabilities (e.g., physical realism, real-time or on-device generation, domain-tuned metrics).
- Production-grade episodic animation with minimal human intervention
- Sectors: streaming, studios
- Tools/workflows: pipeline-wide automation (script, blocking, shots, edits, VO); automated retake proposals via MCTS-Gen; tight asset/version control
- Assumptions/dependencies: stronger physical plausibility and interactions; advanced scene graph control; legal/IP workflows; robust editorial oversight
- Real-time interactive and personalized storytelling (branched narratives)
- Sectors: edtech, entertainment, therapy
- Tools/products: live “choose-your-own-adventure” with on-the-fly generation; MCTS-Gen or bandit-style schedulers for branching options; adaptive VO
- Assumptions/dependencies: low-latency generation; streaming stateful evaluation; safety filters for open-ended inputs
- Dynamic in-game cinematics and NPC backstories generated on the fly
- Sectors: gaming
- Tools/workflows: integration with runtime engines; agentic story planners + MCTS-Gen for moment-to-moment beat selection; style-preserving synthesis
- Assumptions/dependencies: engine performance budgets; deterministic seeding and caching; live AniEval variants that are sufficiently fast
- XR/AR video companions and narrative overlays
- Sectors: XR, retail, museums
- Tools/products: spatially aware animated explainers; scene-conditioned story clips; hands-free localized narration
- Assumptions/dependencies: on-device or edge inference; accurate spatial/semantic understanding; privacy guardrails
- Standards and compliance: platform-level QA and provenance for synthetic video
- Sectors: policy, platforms, standards bodies
- Tools/workflows: AniEval-derived “Coherence/Continuity” gates; watermarking/provenance tags; age-suitability checks for kids’ content
- Assumptions/dependencies: cross-platform consensus, regulatory buy-in, interoperable metadata (e.g., C2PA-like standards)
- Multi-modal MCTS-Gen beyond video: music, comics, long-form text, code
- Sectors: creative software, developer tools
- Tools/products: “Search-aware Generators” that allocate compute across sections/movements/tests; evaluators (e.g., music structure, narrative arcs, unit tests)
- Assumptions/dependencies: domain-specific evaluators (AniEval analogs), controllable generative models per modality
- Healthcare and patient education animation at scale
- Sectors: healthcare, public health
- Tools/workflows: condition-specific explainer series; multilingual delivery; clinic-branded assets with consistent characters
- Assumptions/dependencies: clinical validation, regulatory approval (HIPAA/PHI considerations), rigorous fact-checking
- Investor relations and regulatory explainers
- Sectors: finance, RegTech
- Tools/products: quarterly highlights, compliance updates, scenario explainer animations
- Assumptions/dependencies: strict accuracy and legal review; data privacy; audit trails and provenance
- Synthetic video dataset factories for robotics/autonomous systems
- Sectors: robotics, AV
- Tools/workflows: multi-agent interaction videos for perception and planning; metric-driven QC (temporal semantics, action completion)
- Assumptions/dependencies: physics fidelity; bridging sim-to-real gaps; labeling automation
- Enterprise knowledge-to-video transformation
- Sectors: enterprise software, productivity
- Tools/products: “Doc-to-Animation” assistants turning SOPs, manuals, and meeting summaries into coherent videos; brand-compliant templates
- Assumptions/dependencies: information extraction quality; security and access control; continuous updates with document changes
- Asset management and continuity co-pilots
- Sectors: studios, agencies
- Tools/workflows: automated Character/Background Bank curation; continuity tracking across seasons/campaigns; change impact analysis on prior episodes
- Assumptions/dependencies: robust asset rights management; metadata standards; versioned style guides
- Education policy and curricula with AI-generated media
- Sectors: public policy, education
- Tools/workflows: frameworks for safe adoption, quality thresholds (AniEval-based), teacher training and review loops
- Assumptions/dependencies: stakeholder alignment; equitable access; bias and safety audits
Cross-Cutting Assumptions and Dependencies
- Model availability and licensing: Many examples use proprietary LMMs and video/TTS models (Gemini, GPT-4o, Wan, CosyVoice). Substitute open-source or licensed equivalents as needed.
- Compute/cost: Multi-candidate generation is compute-intensive; MCTS-Gen reduces cost but still needs GPU/API budgets and scheduler tuning (w1/w2/alpha).
- Domain adaptation of AniEval: Face Consistency currently trained on anime faces; adapters or retraining required for realistic faces, non-human characters, and domain-specific styles.
- Safety, moderation, and IP: Strong guardrails for kids’ content, branded assets, and user-submitted materials; provenance/watermarking recommended.
- Physical plausibility and interaction: Current limitations in physics and object interactions reduce suitability for some production-grade scenarios; incremental improvements expected with newer base models.
- Human-in-the-loop: Editorial review, fact-checking, and legal compliance remain essential, especially in regulated domains (healthcare, finance, education).
Collections
Sign up for free to add this paper to one or more collections.