- The paper introduces Avey, a novel architecture that decouples sequence length from context width for robust long-range dependency modeling.
- It employs a ranker to partition sequences and a specialized neural processor—eschewing attention and recurrence—to enhance efficiency.
- Empirical results on Needle-in-a-Haystack benchmarks highlight Avey's competitive performance and scalable potential for real-time applications.
Don't Pay Attention
Introduction
"Don't Pay Attention" introduces Avey, a novel architecture that diverges from the traditional self-attention and recurrence-based approaches predominantly used in language modeling. Avey is designed to excel at handling long-range dependencies by effectively decoupling sequence length from context width. The paper provides both theoretical foundations and empirical evidence showcasing Avey's superior capability in processing long sequences, demonstrating competitive performance on standard NLP benchmarks and excelling in long-range dependency tasks.
Avey Architecture
Avey comprises two main components: a ranker and an autoregressive neural processor. The ranker divides sequences into splits and selectively identifies the most relevant ones, enabling efficient processing. The neural processor, which is devoid of attention and recurrence mechanisms, is built to preserve and contextualize meaningful information across tokens with its sub-components: the enricher, contextualizer, and fuser.
Ranker
The ranker's primary function is to partition input sequences into splits and use the MaxSim operator to select the most relevant splits. The selected splits are weighted based on their normalized scores and contextualized together with the current split.
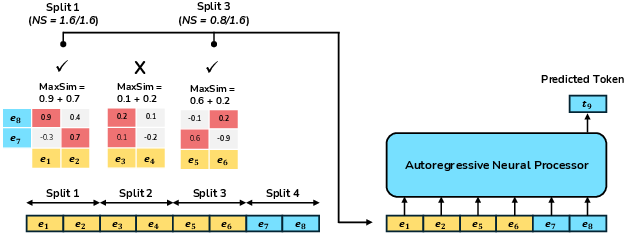
Figure 1: The ranker partitions input sequences and uses the MaxSim operator to select top-k relevant splits for contextualization.
Neural Processor
The neural processor eschews traditional attention mechanisms, opting for a pipeline consisting of an enricher for enhancing feature richness, a contextualizer allowing dynamic interactions among embeddings, and a fuser to integrate raw and processed features efficiently.
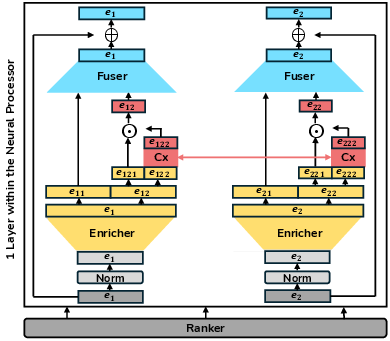
Figure 2: The neural processor showcases its components: enricher, contextualizer, and fuser, elaborating on their roles.
Empirical Validation
Avey's capability was tested using Needle-in-a-Haystack (NiaH) benchmarks, illustrating strong generalization beyond its trained context window.
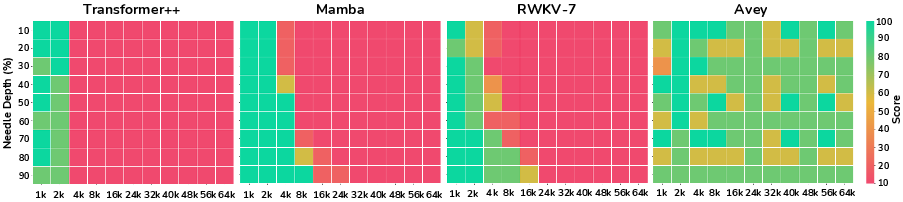
Figure 3: Performance comparison on the NiaH test demonstrating Avey's ability to generalize beyond training context window.
Implementation Considerations
- Architecture Efficiency: Avey operates with linear inference complexity per token, which makes it suitable for real-time applications.
- Extrapolation Capability: Despite trained with a limited context, Avey scales to handle sequences significantly longer than seen during training.
- Aesthetic Characteristics: The exclusion of attention and recurrence reduces complexity in architecture design, and dynamic parameterization improves output contextualization.
Comparison with Baselines
Avey is compared to Transformer++, Mamba, and RWKV-7 across short-range benchmarks. While underperforming slightly at larger model scales, Avey remains competitive, especially in long-context scenarios.
Conclusion
Avey presents a promising departure from the attention and recurrence paradigms, demonstrating strong potential for language modeling tasks. Its performance on benchmarks suggests a viable path for future research to explore more scalable and adaptable LLMs. The paper's implications imply further advancements in real-time applications and long-context language scenarios, offering a robust alternative to Transformer-centric architectures.