- The paper demonstrates that mapping visual features to a fixed language space via a linear adapter enables effective cross-modal alignment.
- It uses sparse autoencoders to trace feature convergence, revealing significant reductions in reconstruction error in mid-to-late layers.
- Findings suggest that enhancing early layer alignment may optimize VLM architectures, opening new directions for multimodal research.
How Visual Representations Map to Language Feature Space in Multimodal LLMs
Introduction
The paper presents a comprehensive exploration into the alignment of visual and linguistic representations within multimodal LLMs (VLMs). This work introduces a systematic framework that restrains adaptation processes by freezing both the LLM and vision transformer (ViT), thereby focusing solely on a linear adapter that maps visual features directly onto the LLM’s language space. This approach is critical as it maintains the integrity of the LLM's feature space while requiring the adapter to learn effective cross-modal mappings. By employing sparse autoencoders (SAEs), the authors provide insights into how visual features gradually align with LLM features across layers, highlighting critical stages of convergence and potential misalignments in early layers.
Methodological Framework
The experimental setup is precisely controlled by freezing two principal components: the CLIP vision transformer and the Gemma LLM. This setup enforces a condition under which the linear adapter must learn to map visual inputs into the fixed language space without adapting the internal structure of the LLM itself. Sparse Autoencoders, used as a mechanistic interpretability tool, provide a lens through which the layer-wise progression of visual feature alignment can be observed.
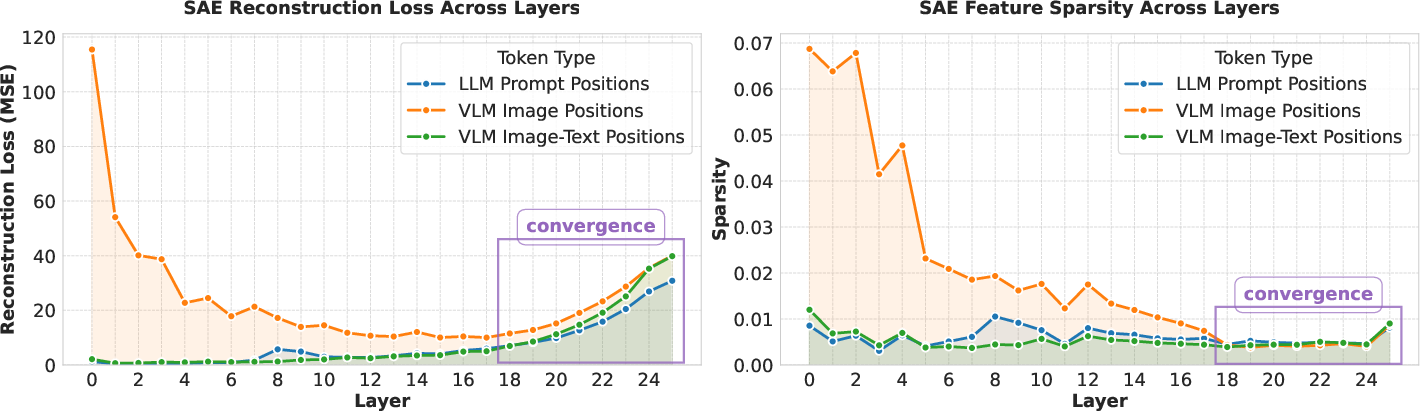
Figure 1: Layer-wise SAE reconstruction error and sparsity patterns. The y-axis shows the MSE reconstruction error (left) and the Sparsity of SAE feature activations as the fraction of non-zero activations (right).
Cross-Modal Representation Mapping
The results demonstrate significant findings, notably the convergence of visual and language features in mid-to-late layers. Analysis utilizing SAEs revealed a marked decline in reconstruction error and sparsity, signaling successful feature alignment. The findings from SAE semantic alignment further support this conclusion, showing that visual representations start mapping accurately to language features distinctly in later layers.
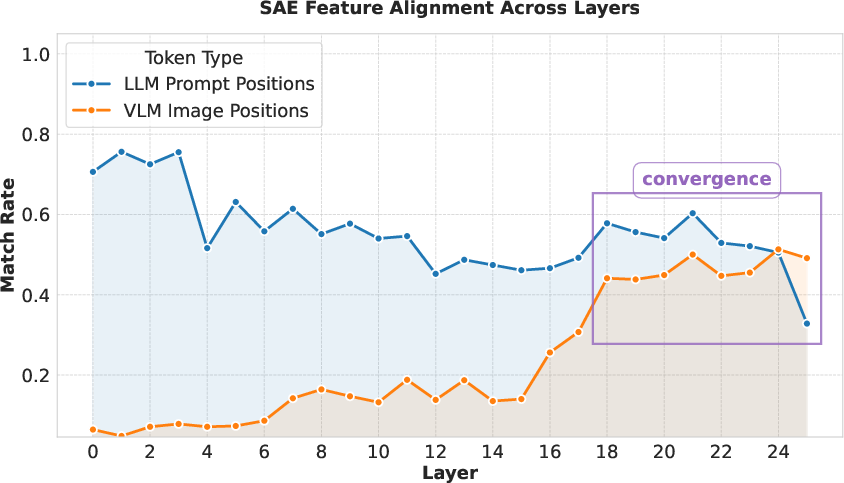
Figure 2: Semantic alignment of SAE feature descriptions across model layers. The y-axis shows the rate with which a visual SAE feature was found for each example. The x-axis shows the layer index.
Implications and Future Directions
The identification of middle-to-late layers as key zones for cross-modal integration informs potential architectural optimizations. This insight suggests that enhancing early layer alignment could improve overall VLM efficiency and performance. Future work may involve exploring this alignment in models trained with end-to-end fine-tuning approaches, providing further understanding of cross-modal representation strategies in unified training scenarios. Additionally, the research opens avenues for fine-tuning adapter configurations to optimize data representation across modalities.
Conclusion
This paper offers a detailed analysis of visual-to-language feature alignment in VLMs by using a rigorously controlled framework. It elucidates the gradual integration of visual features into linguistic feature space, highlighting essential convergence points while noting early layer misalignments. These findings enhance the understanding of multimodal integration dynamics and provide a foundation for future advancements in model architecture and interpretability strategies in AI research.

