- The paper introduces T²-RAGBench as a benchmark to rigorously evaluate RAG models on mixed text and table data from financial documents.
- It details a dual-phase task that first retrieves appropriate context and then extracts answers, employing metrics like MRR and Number Match.
- Experimental results show that while Hybrid BM25 improves performance, significant retrieval bottlenecks remain for state-of-the-art models.
T2-RAGBench: Text-and-Table Benchmark for Evaluating Retrieval-Augmented Generation
Introduction
The paper introduces T2-RAGBench, a novel benchmark designed to evaluate Retrieval-Augmented Generation (RAG) methods specifically in the context of mixed text and table data. Unlike traditional QA datasets that assume an oracle-context setting, T2-RAGBench requires models to retrieve and reason over contexts that are not pre-specified. This benchmark comprises 32,908 question-context-answer triples extracted from real-world financial documents, emphasizing context-independent question formulation to provide a rigorous evaluation of RAG capabilities.
Current RAG methods typically handle either purely textual data or rely on context-specific datasets, which limits their efficacy in documents comprising text and tables. Such documents are common in financial reporting and require robust systems capable of processing both modalities effectively. Existing datasets in the financial sector, like FinQA and ConvFinQA, often suffer from context-dependent questions which hinder comprehensive evaluation of RAG methods. T2-RAGBench closes this gap by providing a context-independent and numerically challenging dataset.
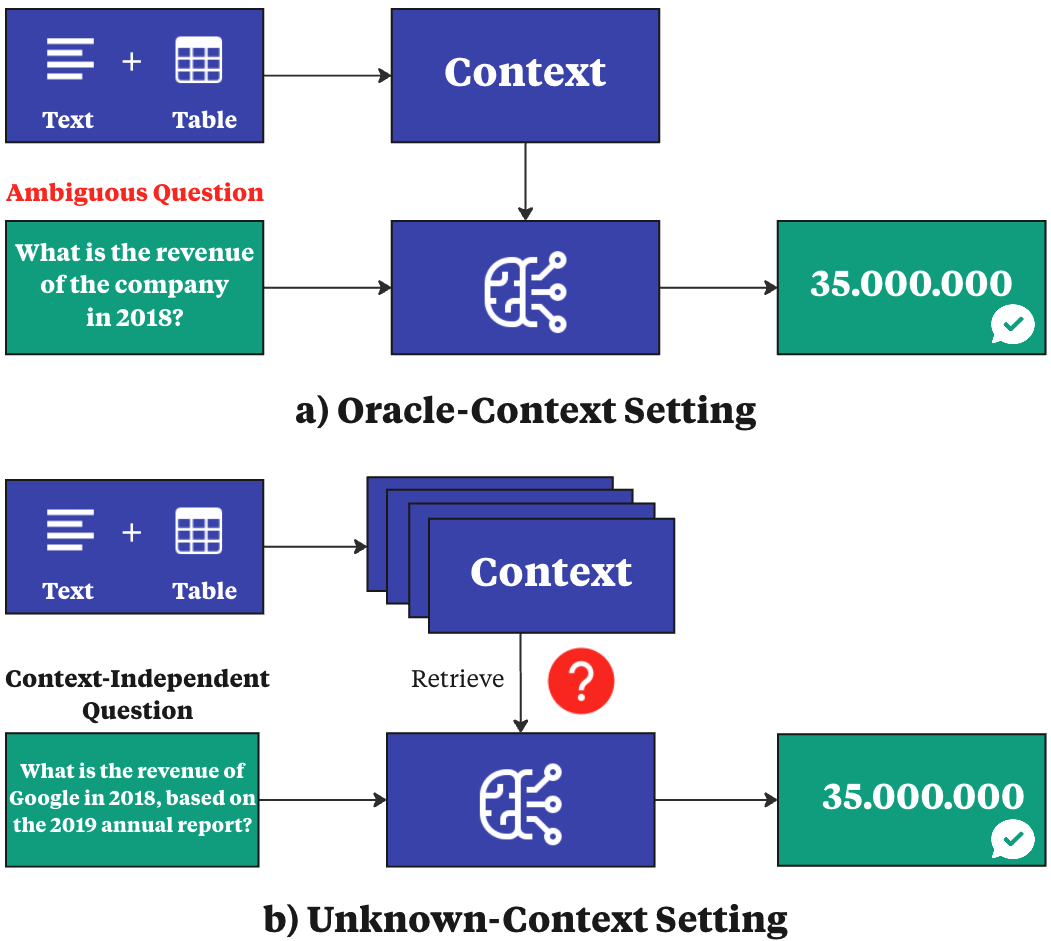
Figure 1: Overview of current SOTA approaches with a focus on the unknown-context setting of T2-RAGBench.
Benchmark Composition and Data Preparation
T2-RAGBench integrates subsets from existing datasets, including FinQA, ConvFinQA, VQAonBD, and TAT-DQA. Each subset underwent rigorous preprocessing to ensure question reformulation yielded context-independent queries. This involved using LLMs to reformulate questions, ensuring each had a single, unambiguous answer, verified through both automated and manual validation processes.
Task Definition
The benchmark challenges models with a dual-phase task: first, they must retrieve the appropriate context from the corpus using a function f, and then extract the correct answer using a model M. The evaluation employs metrics like Mean Reciprocal Rank (MRR) to measure retrieval effectiveness and a novel Number Match metric for assessing numerical reasoning accuracy.
Evaluation of RAG Methods
A comprehensive evaluation was conducted on popular RAG methods. It was found that Hybrid BM25, which combines dense and sparse vectors, outperformed other methods on text-and-table data, though T2-RAGBench remained challenging even for SOTA models.
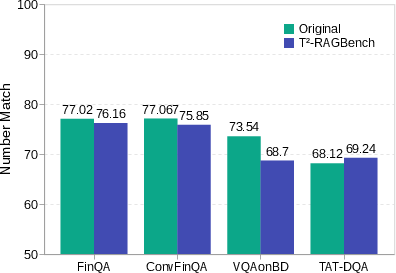
Figure 2: Human agreement on questions showing the shift from context-dependent to context-independent queries.
Despite performance improvements with Hybrid BM25, a notable gap remains compared to oracle contexts, highlighting ongoing challenges in effectively retrieving mixed-modality data. Ablation studies revealed modest gains from using advanced embedding models, indicating that retrieval remains a bottleneck in text-and-table tasks.
Conclusion and Future Directions
T2-RAGBench sets a new standard for evaluating RAG systems on text-and-table data, with significant implications for financial document analysis. Future work could explore expanding the benchmark to include a wider range of document types and assessing methods that leverage multi-modal data interactions further. This benchmark encourages advancements in RAG methodologies to better handle the complexities of mixed-modality information retrieval and generation.
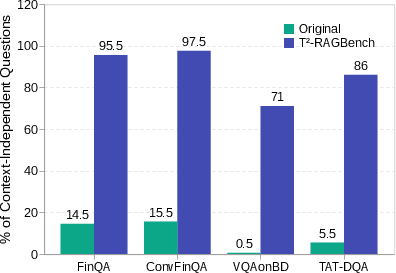
Figure 3: MRR@3 performance across different subsets showing the retrieval challenge in T2-RAGBench.