- The paper presents PBHC, a framework that combines a two-stage physics-based motion processing pipeline with an adaptive tracking mechanism to achieve agile and expressive humanoid motions.
- It utilizes an asymmetric actor-critic RL architecture with reward vectorization and domain randomization, ensuring robust performance both in simulation and on the Unitree G1 robot.
- Experimental results validate that the adaptive reward mechanism significantly reduces tracking error and enhances sim-to-real transfer for dynamic tasks like martial arts and dance.
Physics-Based Humanoid Whole-Body Control for Highly-Dynamic Skill Learning
Introduction
The paper presents PBHC (Physics-Based Humanoid motion Control), a reinforcement learning (RL) framework for whole-body humanoid control, targeting the imitation of highly-dynamic human motions such as martial arts and dance. The approach addresses the limitations of prior RL-based methods, which are typically constrained to smooth, low-speed motions due to physical infeasibility and lack of adaptive reward mechanisms. PBHC introduces a two-stage pipeline: physics-based motion processing to ensure reference motions are physically plausible, and an adaptive motion tracking mechanism that dynamically tunes tracking reward tolerance via bi-level optimization. The framework is validated both in simulation and on the Unitree G1 robot, demonstrating stable, expressive, and agile behaviors.
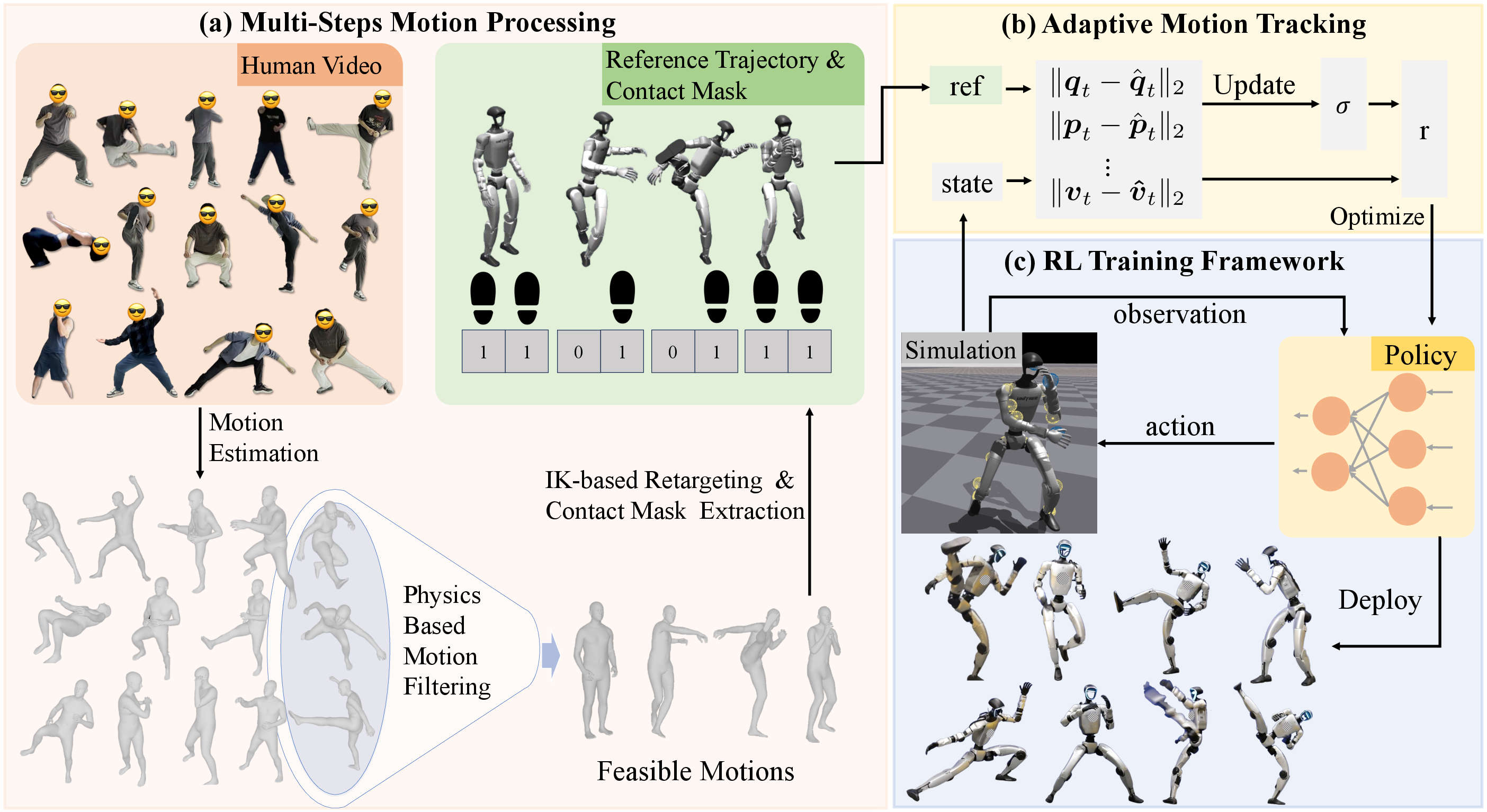
Figure 1: Overview of PBHC, illustrating motion extraction and processing, adaptive tracking, RL training, and sim-to-real deployment.
Physics-Based Motion Processing Pipeline
PBHC's motion processing pipeline consists of four sequential steps:
- SMPL-format Motion Estimation: Human motions are extracted from monocular videos using GVHMR, which aligns reconstructed poses with gravity and mitigates foot sliding artifacts.
- Physics-Based Filtering: Motions are filtered by evaluating the proximity of the center of mass (CoM) and center of pressure (CoP), enforcing dynamic stability. Frames violating stability thresholds are excluded, and only sequences with acceptable instability gaps are retained.
- Contact-Aware Correction: Foot-ground contact masks are estimated via zero-velocity assumptions on ankle displacement. Vertical offsets are applied to correct floating artifacts, followed by exponential moving average smoothing to reduce jitter.
- Motion Retargeting: Processed SMPL motions are mapped to the robot via differentiable inverse kinematics, ensuring end-effector alignment and joint limit compliance.
This pipeline ensures that only physically feasible, well-annotated motions are used for policy training, improving downstream RL performance and sim-to-real transfer.

Figure 2: Example motions from the constructed dataset, with temporal progression indicated by opacity.
Adaptive Motion Tracking via Bi-Level Optimization
A central contribution is the adaptive motion tracking mechanism, which formulates the selection of the tracking reward tolerance (tracking factor σ) as a bi-level optimization problem. The reward for tracking is defined as r(x)=exp(−x/σ), where x is the tracking error. The optimal σ minimizes the accumulated tracking error of the converged policy over the reference trajectory.
The bi-level optimization is formalized as:
σmaxJex(x∗)s.t.x∗∈argxmaxJin(x,σ)+R(x)
where Jin is the accumulated exponential reward and R captures additional objectives. Under reasonable assumptions, the optimal tracking factor is shown to be the average tracking error:
σ∗=N1∑i=1Nxi∗
Since σ∗ and x∗ are coupled, PBHC employs an online adaptive mechanism: the tracking factor is updated via a non-increasing exponential moving average of the instantaneous tracking error, forming a closed feedback loop that tightens σ as the policy improves.
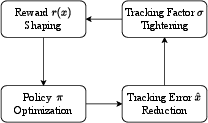
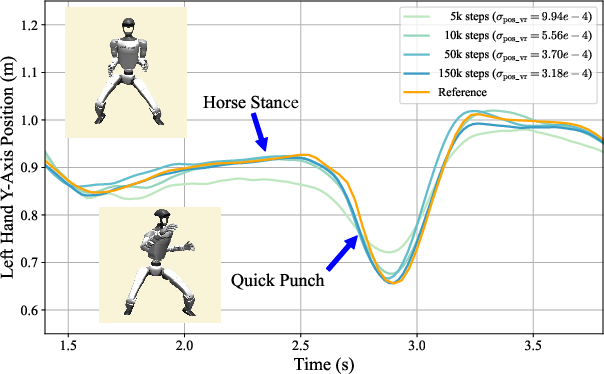
Figure 3: Closed-loop adjustment of the tracking factor in the adaptive mechanism.
This adaptive curriculum enables the policy to progressively increase tracking precision, outperforming fixed reward tolerance schemes, especially for motions with varying difficulty and quality.
RL Training Framework and Architecture
PBHC utilizes an asymmetric actor-critic architecture:
- Actor: Observes proprioceptive state and time phase variable, relying solely on local information.
- Critic: Receives privileged information, including reference motion, root velocity, and randomized physical parameters, enabling more accurate value estimation.
- Reward Vectorization: Multiple reward components are vectorized, with the critic network outputting independent value estimates for each, aggregated for advantage computation.
- Reference State Initialization (RSI): Robot states are initialized from reference motion states at random phases, facilitating parallel learning and improving sample efficiency.
- Domain Randomization: Physical parameters are randomized during training to enhance robustness and enable zero-shot sim-to-real transfer.
Experimental Results
Motion Filtering
Physics-based filtering effectively excludes untrackable motions, as evidenced by high episode length ratios (ELR) for accepted motions and frequent early terminations for rejected ones. This improves training efficiency and policy reliability.
PBHC achieves significantly lower tracking errors than OmniH2O and ExBody2 across all metrics and difficulty levels. MaskedMimic, while competitive, is not deployable for real robot control due to lack of physical regularization and partial observability constraints.
Adaptive Tracking Ablation
Ablation studies show that fixed tracking factors yield suboptimal performance on certain motions, while the adaptive mechanism consistently achieves near-optimal results across all motion types.
Real-World Deployment
PBHC policies are deployed on the Unitree G1 robot, demonstrating robust execution of complex skills including martial arts, acrobatics, and dance. Quantitative metrics for Tai Chi in the real world closely match simulation results, validating the sim-to-real transfer.
Implementation Considerations
- Computational Requirements: Training is performed on high-end GPUs (e.g., RTX 4090) with substantial memory and CPU resources. Each policy is trained for ~27 hours.
- Policy Specialization: Each policy is trained for a single motion, limiting generalization but maximizing dynamic performance.
- Sim-to-Real Transfer: Domain randomization and privileged critic observations are critical for robust transfer. No fine-tuning is required post-deployment.
- Limitations: The framework lacks environment awareness (e.g., terrain perception, obstacle avoidance) and does not support multi-motion generalization within a single policy.
Implications and Future Directions
PBHC advances the state-of-the-art in physics-based humanoid control, enabling expressive, agile, and stable whole-body behaviors. The adaptive tracking mechanism provides a principled approach to reward curriculum design, which can be extended to other RL domains with non-stationary or heterogeneous task difficulty. Future work should address policy generalization across diverse motion repertoires and incorporate environment perception for deployment in unstructured settings. Integration with large-scale motion datasets and foundation models may further enhance versatility and scalability.
Conclusion
PBHC demonstrates that physics-based motion processing and adaptive reward mechanisms are essential for learning highly-dynamic humanoid skills. The framework achieves superior tracking accuracy and robust sim-to-real transfer, validated both in simulation and on hardware. While limitations remain in generalization and environment interaction, the approach provides a solid foundation for future research in agile, expressive humanoid robotics.