- The paper introduces SyncTalk++, which uses a Dynamic Portrait Renderer with Gaussian Splatting to achieve precise synchronization of identity, lip movements, expressions, and head poses at 101 FPS.
- It integrates an OOD Audio Expression Generator and a Torso Restorer to robustly manage out-of-distribution audio by generating matched facial expressions and repairing head-torso artifacts.
- Experimental evaluations employing metrics like PSNR, LPIPS, and FID demonstrate state-of-the-art performance, making the method suitable for digital assistants, VR, and filmmaking.
SyncTalk++: High-Fidelity and Efficient Synchronized Talking Heads Synthesis Using Gaussian Splatting
This paper introduces SyncTalk++, a novel approach to speech-driven talking head synthesis that leverages 3D Gaussian Splatting (3DGS) for high-fidelity and efficient rendering. The method addresses the critical challenge of synchronization among subject identity, lip movements, facial expressions, and head poses, identified as a key factor for realistic talking head generation. The paper emphasizes enhancements in rendering speed, visual quality, and robustness to out-of-distribution (OOD) audio through the introduction of several key modules.
Core Contributions
The paper's main contributions are threefold:
- High Synchronization via Gaussian Splatting: SyncTalk++ employs a Dynamic Portrait Renderer with Gaussian Splatting, achieving high synchronization across identity, lip movements, expressions, and head poses. This leads to improved visual quality and a rendering speed of 101 frames per second.
- Robustness to Out-of-Distribution Audio: The method enhances robustness to OOD audio by incorporating an Expression Generator and a Torso Restorer. These modules generate speech-matched facial expressions and seamlessly repair artifacts at head-torso junctions.
- State-of-the-Art Performance: Comparative experiments demonstrate that SyncTalk++ outperforms existing state-of-the-art methods in both qualitative and quantitative evaluations, making it suitable for practical deployment.
Methodological Details
SyncTalk++ consists of five main components designed to address specific aspects of talking head synthesis.

Figure 1: The proposed SyncTalk++ uses 3D Gaussian Splatting for rendering. It can generate synchronized lip movements, facial expressions, and more stable head poses, and features faster rendering speeds while applying to high-resolution talking videos.
Face-Sync Controller
The Face-Sync Controller is responsible for synchronizing lip movements and facial expressions. It uses an audio-visual encoder trained on the LRS2 dataset and a 3D facial blendshape model to capture and control expressions via semantically meaningful facial coefficients. The audio-visual encoder is trained with a lip synchronization discriminator to ensure extracted audio features are aligned with lip movements, using both reconstruction loss (Lrecon) and synchronization loss (Lsync). A facial animation capturer module uses 52 blendshape coefficients (B) to model the face, focusing on seven core coefficients to control key facial regions. A facial-aware masked-attention mechanism reduces interference between lip and expression features during training, using masks Mlip and Mexp to focus attention on respective regions.
Head-Sync Stabilizer
The Head-Sync Stabilizer maintains stable head poses by employing a two-stage optimization framework. A head motion tracker extracts sparse 2D landmarks and estimates corresponding 3D keypoints using the Basel Face Model (BFM), refining expression parameters (αexp), pose parameters (R,T), and focal length (f) while keeping identity parameters (αid) fixed. Optical flow estimation tracks facial keypoints (K), and a semantic weighting module reduces the weight of unstable points (e.g., eyebrows, eyes) to improve tracking accuracy. Bundle adjustment refines 3D keypoints and head pose jointly, minimizing the alignment error (Lsec).
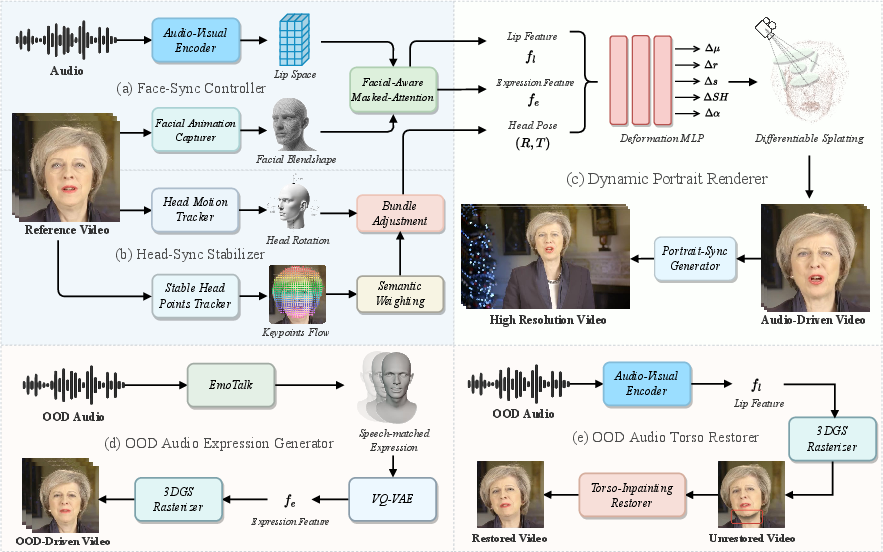
Figure 2: Overview of SyncTalk++. Given a cropped reference video of a talking head and the corresponding speech, SyncTalk++ can extract the Lip Feature fl, Expression Feature fe, and Head Pose (R,T) through two synchronization modules (a) and (b). Then, Gaussian Splatting is used to model and deform the head, producing a talking head video. The OOD Audio Expression Generator and Torso Restorer can generate speech-matched facial expressions and repair artifacts at head-torso junctions.
Dynamic Portrait Renderer
The Dynamic Portrait Renderer handles high-fidelity facial rendering using 3D Gaussian Splatting. Canonical Gaussian fields utilize a triplane representation to encode 3D head features, processed by MLPs to yield canonical parameters. During point-based rendering, 3D Gaussians are transformed into camera coordinates and projected to the image plane. A multi-perspective approach reconstructs canonical 3D Gaussians, and a deformation module modifies these Gaussians based on audio input, predicting offsets for each Gaussian attribute. The triplane representation uses three orthogonal 2D feature grids to ensure consistency across multiple viewpoints.
OOD Audio Expression Generator
The OOD Audio Expression Generator addresses mismatches between facial expressions and spoken content when using out-of-distribution audio. A Transformer-based VQ-VAE model, including an encoder (E), a decoder (D), and a codebook (Z), captures characteristic distributions of different identities and generates blendshape coefficients tailored to the target character's facial features. The codebook Z contains embedding vectors zk, and a quantization function Q maps latent representations to the nearest codebook entry.
OOD Audio Torso Restorer
The OOD Audio Torso Restorer repairs gaps at the junction between the head and torso, using a lightweight U-Net-based inpainting model. The Torso-Inpainting Restorer integrates the rendered facial region with the torso, ensuring visual coherence. The inpainting process is represented as I(MFsource,(1−M−δran)Fsource,θ)=F^source, where I is the inpainting process and θ represents learnable parameters.
Experimental Validation
The method was evaluated using well-edited video sequences, including English and French. The implementation used similar settings to previous NeRF-based methods. A comprehensive set of metrics, including PSNR, LPIPS, MS-SSIM, FID, NIQE, BRISQUE, LMD, AUE, and LSE-C, were used to assess image quality, synchronization, and efficiency. Baselines included 2D generation-based methods (Wav2Lip, VideoReTalking, DINet, TalkLip, IP-LAP) and 3D reconstruction-based methods (AD-NeRF, RAD-NeRF, GeneFace, ER-NeRF, TalkingGaussian, GaussianTalker).
The results showed that SyncTalk++ achieves state-of-the-art performance in head reconstruction, with superior image quality and lip synchronization. Ablation studies confirmed the contribution of each module to the overall performance. User studies further validated the perceptual quality of the generated talking heads, with SyncTalk++ achieving high scores across lip-sync accuracy, expression-sync accuracy, pose-sync accuracy, image quality, and video realness.
Ethical Considerations
The paper acknowledges the potential for misuse of talking head synthesis technology and suggests several mitigation strategies, including improving deepfake detection algorithms, protecting real talking-head videos, ensuring transparency and consent, and restricting the application of deepfake technology.
Conclusion
The paper presents SyncTalk++, an advanced framework for generating realistic speech-driven talking heads. By leveraging Gaussian Splatting and addressing the critical issue of synchronization, the method achieves high rendering speed, improved visual quality, and robustness to OOD audio. Experimental results and user studies demonstrate that SyncTalk++ outperforms existing state-of-the-art methods. The advancements reported in this paper contribute to more immersive applications in digital assistants, virtual reality, and filmmaking.