- The paper demonstrates an entropy-based advantage shaping method that improves exploratory reasoning in LLMs by integrating a clipped, gradient-detached entropy term.
- It reveals key correlations between high token entropy and critical reasoning actions such as logical connectors and reflective error corrections.
- Experimental results show enhanced Pass@K performance on challenging mathematical benchmarks compared to standard RL approaches.
Reasoning with Exploration: An Entropy Perspective on Reinforcement Learning for LLMs
This paper presents a method to improve the reasoning capabilities of LLMs by incorporating an entropy-based advantage shaping technique into reinforcement learning (RL) training. The method encourages exploration during training, leading to enhanced performance on reasoning tasks.
Entropy and Exploratory Reasoning in LLMs
The paper begins by empirically investigating the relationship between entropy and exploratory reasoning in LLMs. Token-level entropy is visualized in LLM responses to mathematical reasoning tasks, revealing correlations between high-entropy regions and exploratory reasoning actions. Specifically, three key findings are presented:
- Pivotal tokens, such as logical connectors (e.g., first, because, thus), exhibit higher entropy. These tokens guide the flow and structure of reasoning.
- Reflective actions, such as self-verification and error correction, tend to emerge under high-entropy conditions.
- Rare or under-explored solutions during RL training coincide with elevated entropy, indicating a link between semantic novelty and predictive uncertainty.
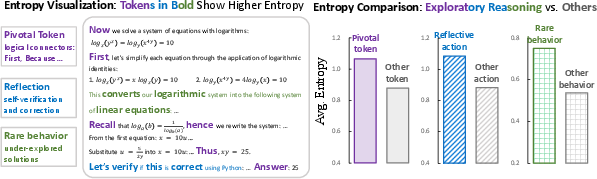
Figure 1: Entropy visualization of exploratory reasoning, categorizing tokens based on their role in the reasoning process.
These findings suggest that entropy can be a valuable signal for recognizing exploratory reasoning behaviors in LLMs.
Entropy-Based Advantage Shaping
Based on the observed correlations, the paper proposes a method to encourage exploratory reasoning during RL training by incorporating entropy as an auxiliary term. Unlike traditional maximum entropy methods that promote exploration by increasing uncertainty, this approach aims to balance exploration and exploitation by introducing a clipped, gradient-detached entropy term into the advantage function of standard RL algorithms (Figure 2).
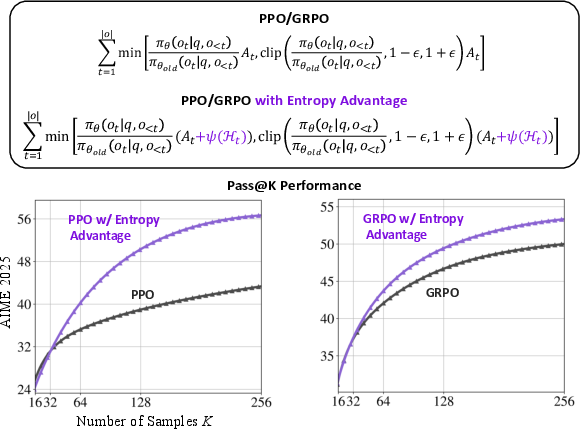
Figure 2: Illustration of augmenting the advantage in PPO or GRPO with a minimal per-token entropy-based term.
The entropy-based advantage term is defined as:
ψ(Ht)=min(α⋅Htdetach,κ∣At∣),
where Ht is the entropy of the policy at token t, At is the original advantage, α is a scaling coefficient, and κ is a clipping threshold. The clipping operation ensures that the entropy term does not dominate the advantage or reverse its sign, thus preserving the original optimization direction. The gradient detachment ensures that the entropy term acts as a fixed offset, adjusting the magnitude of the update without altering the gradient flow. This shaping method can be seamlessly integrated into existing RL training pipelines with a single line of code.
The paper argues that this method avoids over-encouragement due to the intrinsic tension between entropy and confidence. As the model gains confidence during training, the entropy-based advantage gradually diminishes, preventing reward hacking. This is in contrast to methods that directly reward the frequency of reasoning-like tokens, which can lead to the model generating such tokens without performing actual reasoning.
Experimental Results
The proposed method is validated on mainstream RLVR algorithms, GRPO and PPO, using the Qwen2.5-Base-7B and Qwen2.5-Math-Base-7B models. The experiments are conducted on mathematical reasoning tasks from the AIME 2025/2024, AMC 2023, and MATH500 datasets. The results demonstrate that the method consistently outperforms the baselines across benchmarks and RL algorithms, achieving superior average performance.
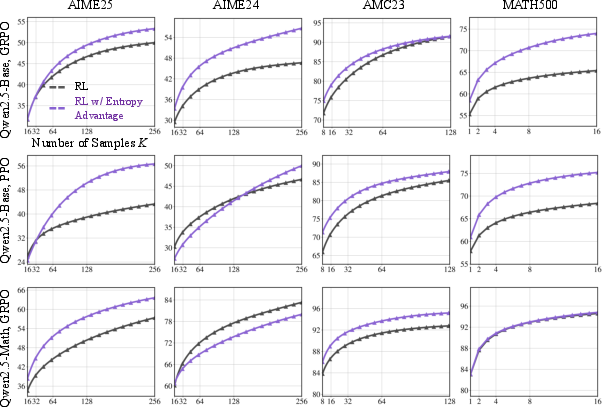
Figure 3: Pass@K performance of LLMs with different RL algorithms, demonstrating improvements even at large K values.
Notably, the method shows improvements on the Pass@K metric, which estimates the reasoning capacity of LLMs. Even at large K values, where most baselines plateau, the proposed method continues to deliver significant improvements. For example, on AIME2025, the method not only outperforms the RL baselines but also exceeds the performance of the base model.
Analysis of Training Dynamics
A detailed analysis of the RL training process reveals that the entropy-based advantage shaping encourages the generation of pivotal tokens and reflective actions, leading to increased model confidence in these regions. The method also sustains the upward trend in response length throughout training and maintains a repetition rate comparable to the RL baseline.
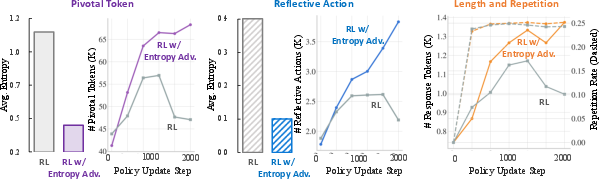
Figure 4: Comparison of pivotal tokens, reflection actions, and response length between the baseline RL algorithm and RL with entropy advantage.
A case study further illustrates that the proposed method leads to more accurate and mathematically rigorous solutions. The model exhibits a structured and persistent reasoning process, explicitly listing problem constraints, performing systematic case analysis, and dynamically adjusting its approach when initial attempts fail.
Comparison with Entropy Regularization
The paper distinguishes the proposed method from traditional entropy regularization, where an entropy term is added to the objective function. In contrast, the proposed method modifies the advantage function by adding a clipped, gradient-detached entropy term, preserving the original RL optimization dynamics. The experimental results show that the proposed method promotes more stable training and achieves better reasoning performance compared to entropy regularization.
Conclusion
This work presents a method to improve the reasoning capabilities of LLMs by incorporating an entropy-based advantage shaping technique into RL training. The method encourages exploration during training, leading to enhanced performance on reasoning tasks. The experimental results and analysis demonstrate the effectiveness of the approach in promoting longer and deeper reasoning chains while preserving the original policy optimization direction. This work highlights a promising direction for exploration-aware LLM training.