- The paper introduces a novel AU-Net architecture that processes raw bytes using a hierarchical multi-level embedding scheme.
- It employs adaptive pooling and upsampling techniques to overcome limitations of static tokenization in traditional language models.
- Experimental results demonstrate that AU-Net excels in character-level tasks and low-resource language settings with scalable performance.
"From Bytes to Ideas: Language Modeling with Autoregressive U-Nets"
This essay provides an examination of the paper "From Bytes to Ideas: Language Modeling with Autoregressive U-Nets" (2506.14761). The paper introduces the Autoregressive U-Net (AU-Net) architecture as a novel approach to address the challenges posed by traditional tokenization methods in language modeling. The focus is on using a hierarchical model that processes raw bytes, thereby removing the constraints of predefined vocabularies.
Introduction
The paper addresses a key limitation in LLMs: the static nature of tokenization schemes like Byte Pair Encoding (BPE). Traditional tokenization freezes the granularity of input data and restricts how future predictions are made. The proposed AU-Net circumvents these limitations by directly embedding information from raw bytes and supporting multiple stages of splitting, forming a multi-level hierarchy of embeddings. This architecture allows the model to dynamically adjust its tokenization strategy, enabling it to adapt to character-level tasks and transfer knowledge across low-resource languages.
Autoregressive U-Net (AU-Net) Architecture
The AU-Net architecture is inspired by U-Net-like models, featuring both contracting and expanding paths with skip connections. It processes inputs at different scales, forming a hierarchy where deeper stages predict further into the future by focusing on broader semantic patterns. The contracting path compresses input sequences into progressively coarser representations, while the expanding path reconstructs them, integrating details from finer levels. The model achieves this using adaptive pooling and upsampling strategies.
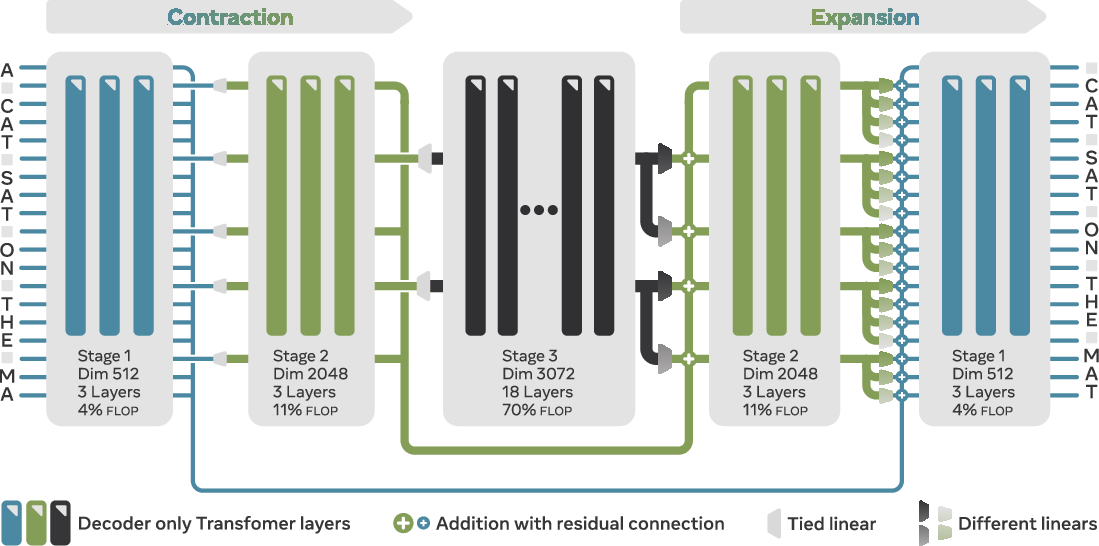
Figure 1: Three-stage Autoregressive U-Net (AU-Net).
The architecture operates in distinct, monolithic stages, each capable of global attention across inputs, unlike previous approaches that rely on local models. Pooling involves selecting vectors at specified positions, following a splitting function, while upsampling utilizes a Multi-Linear approach, applying position-specific linear projections to expand pooled representations.

Figure 2: Pooling and upsampling strategy in the AU-Net.
Methodology
Key contributions of the paper include the introduction of adaptive multi-level hierarchy for embeddings, eliminating the need for predetermined vocabularies and demonstrating strong performance scaling trends. The architecture allows for infinite vocabulary size by working directly with bytes, sidestepping memory-heavy embedding tables. Additionally, the paper discusses stable scaling laws for hyperparameters, crucial for optimizing performance across different compute budgets.
Experimental Results
In terms of downstream task performance, AU-Net generally performs on par with or exceeds BPE-based transformers, particularly as hierarchical depth increases. Notably, it exhibits superior performance in character-level tasks and shows promise for scaling in low-resource language settings.
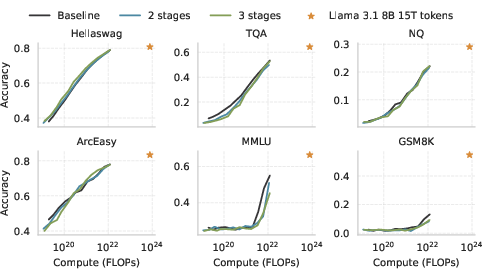
Figure 3: Downstream task performance scaling with compute.
The performance trends indicate that multi-stage AU-Net variants outperform BPE baselines for benchmarks like ARC and Hellaswag. However, it shows delayed improvements for tasks such as MMLU and GSM8K, which may require more extensive training data to fully harness hierarchical advantages.
Deployment and Challenges
Despite promising results, AU-Net faces challenges, particularly in supporting non-space-based languages and requiring predefined splitting functions, as its architecture is currently tailored to Latin scripts. Future work could explore learning splitting functions directly and optimizing model efficiency for higher parameter counts using strategies like Fully Sharded Data Parallelism (FSDP).
Conclusion
The AU-Net offers a flexible language modeling alternative by integrating tokenization into the learning process, providing insight into multi-scale patterns within sequences. The model's byte-level operation not only enhances performance on specialized tasks but also facilitates generalization across underrepresented languages, presenting a viable pathway for more adaptable LLMs. Further research could extend its application to non-Latin scripts, enhancing its universal applicability.