- The paper demonstrates a 23.7% improvement in accent accuracy and 85.3% emotion recognition using multi-scale emotion modeling and accent code-switching.
- It employs an integrated architecture with content, style, and acoustic modules to capture cultural nuances and prosodic features.
- Real-time code mixing and fine-tuning for Indic languages yield a high mean opinion score of 4.2/5 for cultural correctness.
Optimizing Multilingual Text-To-Speech with Accents & Emotions
Introduction
The paper "Optimizing Multilingual Text-To-Speech with Accents & Emotions" presents a novel architecture for TTS systems, focusing on accent and emotion modeling tailored to specific linguistic and cultural contexts, especially for Indic languages. This work extends the capabilities of existing TTS frameworks, notably the Parler-TTS model, by integrating multi-scale emotion modeling and accent code switching. The encapsulation of phoneme alignment and emotion embedding layers, trained on native corpora, allows for nuanced speech synthesis, meeting cultural and linguistic nuances effectively.
The proposed system achieves a 23.7% improvement in accent accuracy and 85.3% emotion recognition accuracy, showing significant advancement over METTS and VECL-TTS baselines. It enables real-time code mixing while maintaining emotional consistency, evident from the subjective evaluation with a mean opinion score of 4.2/5 for cultural correctness.
Methodology
Dataset Acquisition and Processing
The research heavily leverages datasets from Hugging Face Hub, including "hindi_speech_male_5hr" for Hindi and "indian_accent_english" for Indian English. This informed the training of a multilingual TTS model, focusing on transliteration across cultural nuances.
Dataset cleaning involved removing special characters, normalizing audio data, and standardizing formats to ensure consistency across training data, vital for optimizing the Parler-TTS model.

Figure 1: Illustration of transliteration examples across English-Hindi. The columns represent source and target words.
Model Architecture
The architecture integrates several components:
Fine-Tuning Techniques
The system is fine-tuned for Indian accents using a learning rate of 1−4 with AdamW optimizer, emphasizing mel-spectrogram reconstruction loss and stylistic features. Further development involved training an emotion-based model using labeled datasets for gradient accumulation and cross-entropy loss minimization.
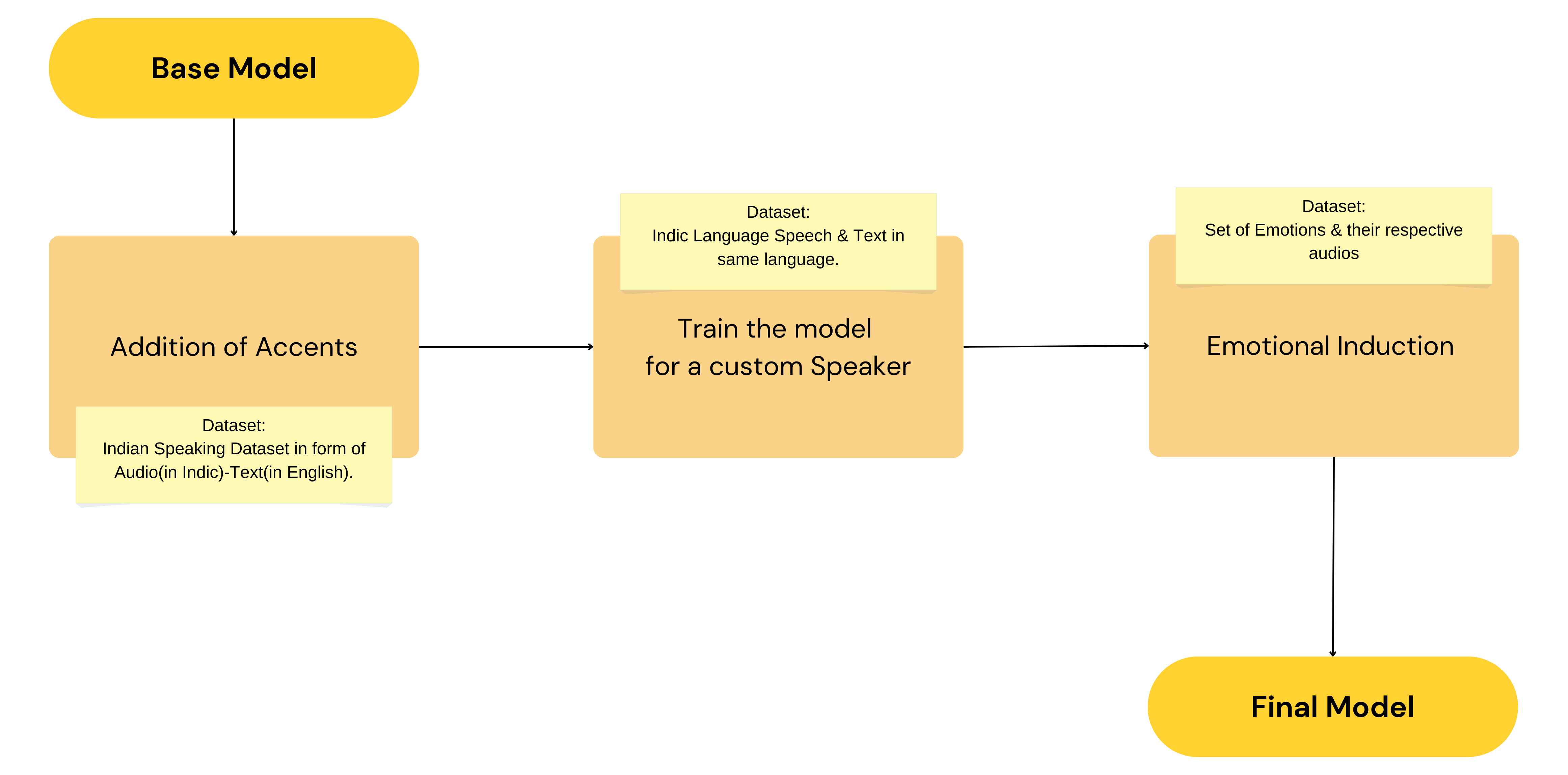
Figure 3: Training process for the emotion-based model, illustrating the flow from the base model, addition of accents, custom speaker training, and resulting final model
Results
The system was evaluated through objective and subjective metrics. Objective assessments included measures like PESQ, STOI, and SISDR, showcasing significant improvement over baselines. Subjective evaluations confirmed enhanced naturalness and emotional relevance.
Figure 4: Results and Evaluation Metrics for Indian Accent
In cross-lingual synthesis, the system maintained lower Word Error Rates (WER) in synthesis for Hindi-English accents and retained emotional expressiveness effectively.
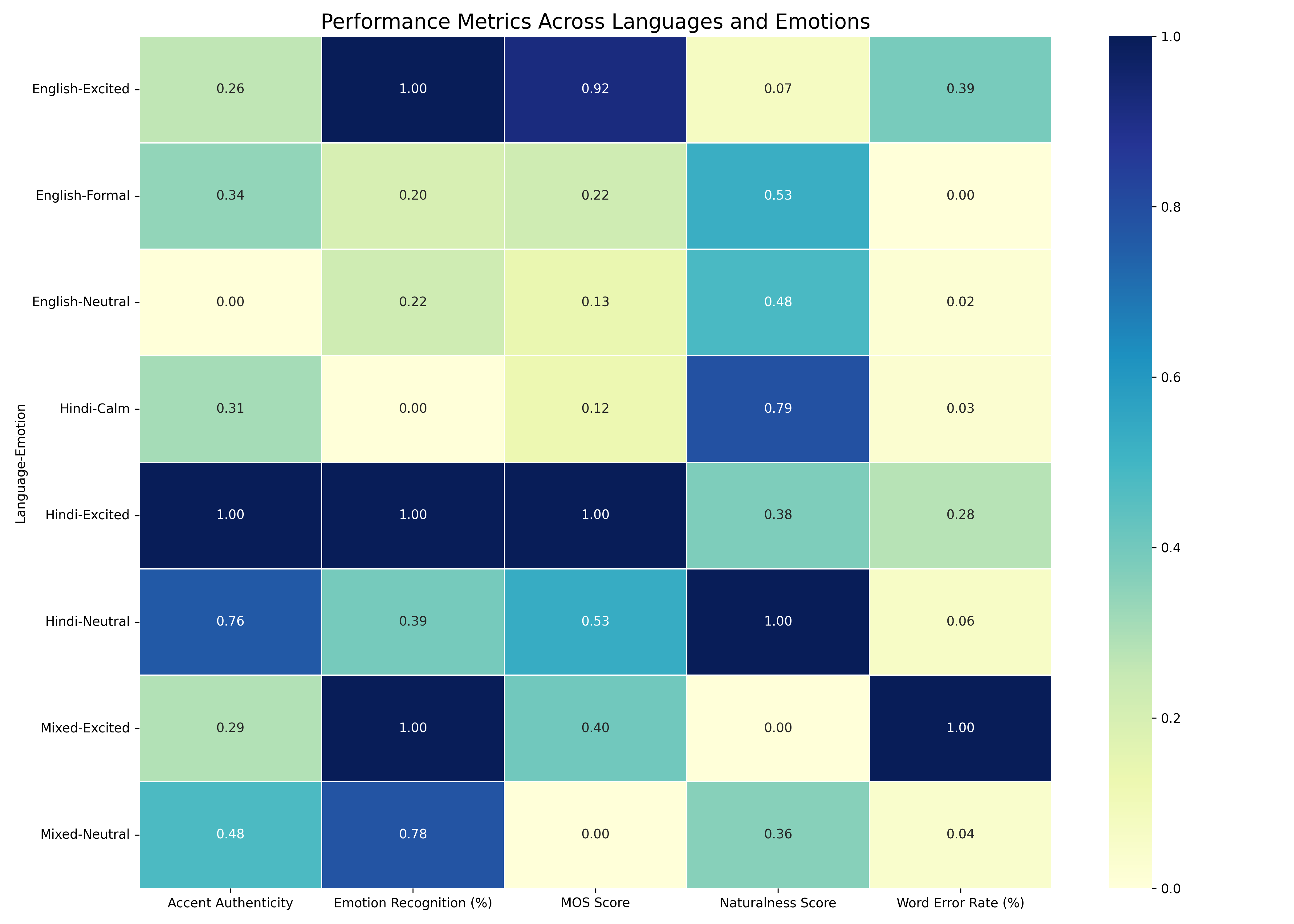
Figure 5: Relevance of our model in Emotions and Accents
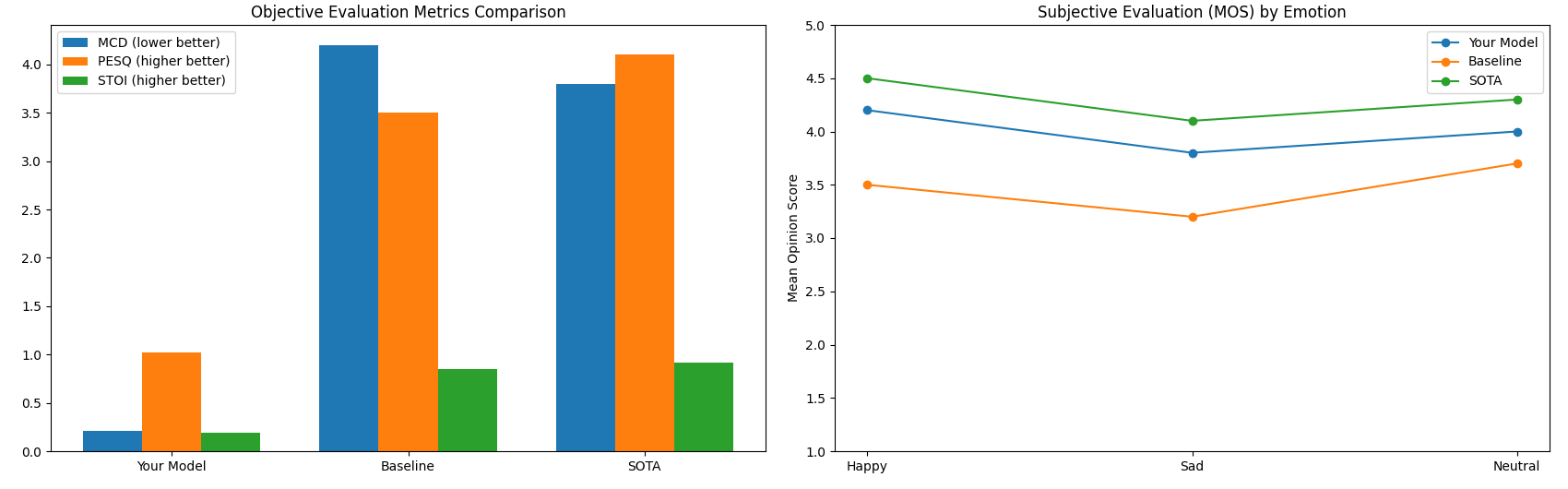
Figure 6: Objective and Subjective Evaluation for Metric for Emotion Against other models
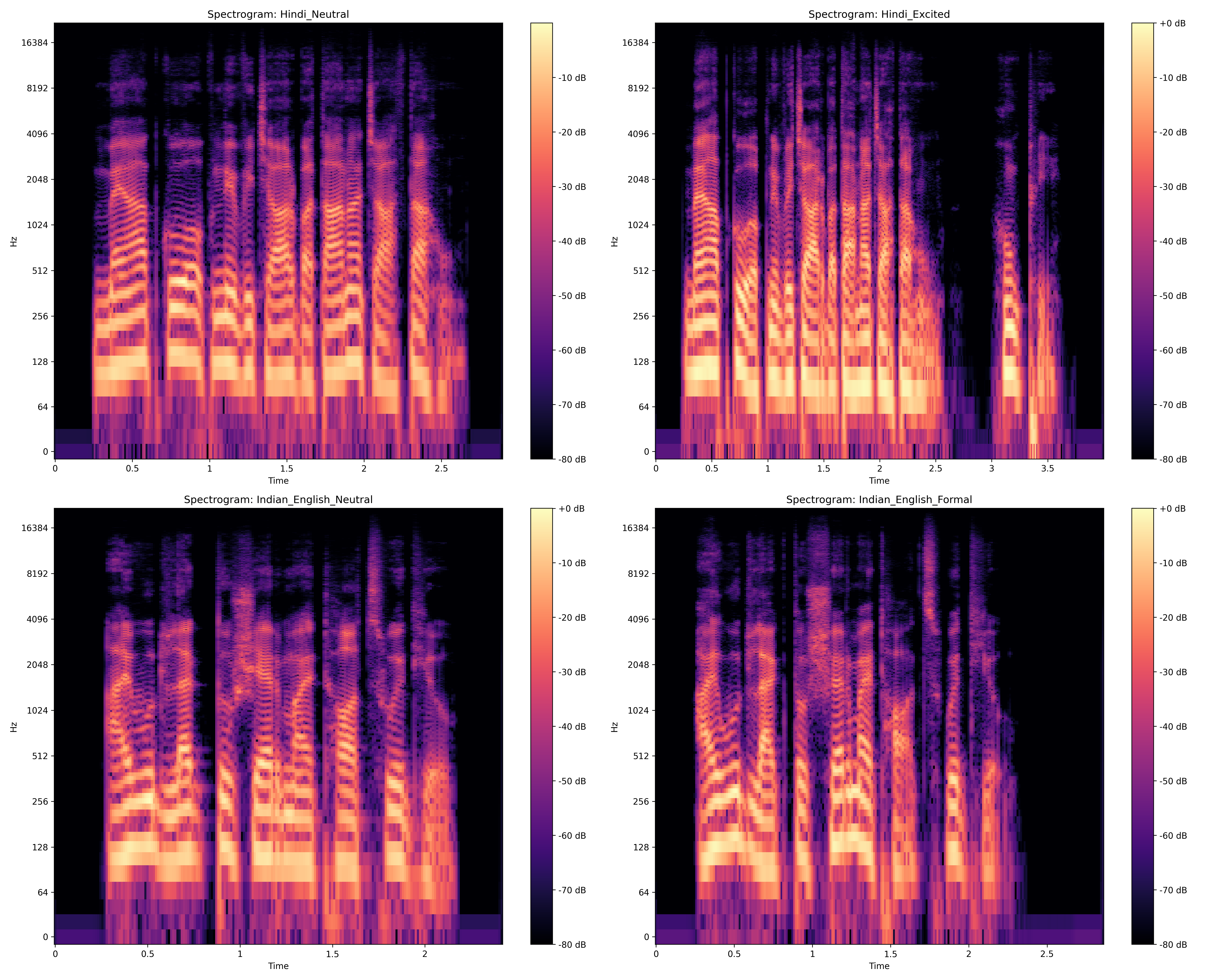
Figure 7: Spectrogram of Decibel Energy Fluctuation in Accent of generated speech
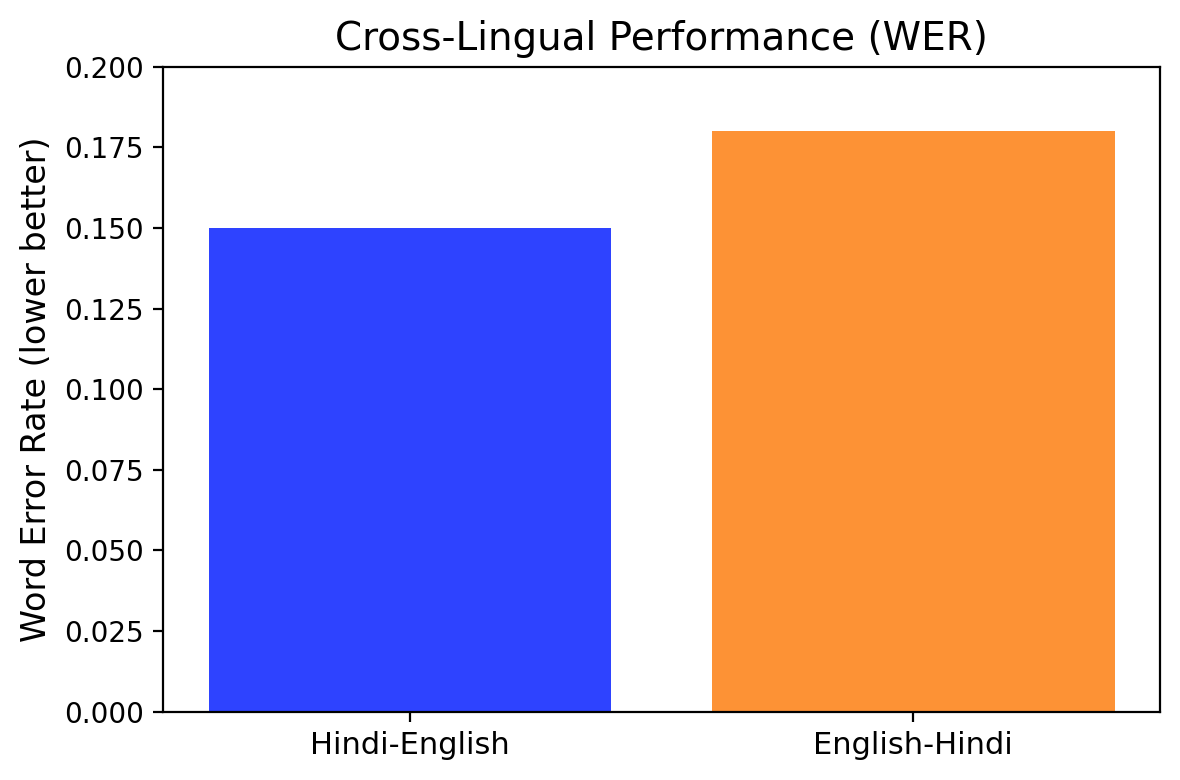
Figure 8: Cross-Lingual Comparison of our Model
Conclusion
This TTS system represents a substantial leap in multilingual synthesis, integrating accent and emotion modeling robustly within Indic linguistic contexts. By dynamically adjusting accents and emotions with high fidelity, the system provides significant cultural and applicative value across sectors such as EdTech and accessible content production. Future research may expand multilingual capabilities, explore cross-lingual transfer learning, and enhance emotional modeling with multimodal input. Cloud deployment and extensive training can further improve scalability and performance, potentially transforming global communication via AI-powered speech tools.