- The paper introduces PathGenIC, which integrates multimodal in-context learning for enhanced histopathology report generation accuracy.
- It employs a vision language model with a ViT-L encoder and transformer-based context integration, resulting in superior BLEU and METEOR scores.
- The framework uses nearest neighbor retrieval and feedback loops to iteratively refine generated reports for clinical relevance.
Histopathology Image Report Generation by Vision LLM with Multimodal In-Context Learning
Introduction
The task of generating medical reports from histopathology images is critical yet challenging, demanding comprehensive visual analysis and integration with domain-specific knowledge. This paper introduces PathGenIC, a novel framework emphasizing multimodal in-context learning (ICL) for enhanced report generation. Inspired by expert pathologists' practices, PathGenIC retrieves semantically similar whole slide image (WSI)-report pairs for context, integrating adaptive feedback to refine the process. Evaluated on the HistGen benchmark, it sets a new standard in performance, indicating promising avenues for AI-driven solutions in clinical settings.
Methodology
Framework Overview
PathGenIC builds upon a vision LLM (VLM) refined for histopathological applications. The model enhances its visual encoder with Vision Transformer Large (ViT-L), extensively pre-trained using DINOv2 techniques, to process WSIs into feature representations. These features are then contextualized through transformer blocks, allowing a holistic view of the WSI before report generation with a text-prompted VLM (Figure 1).

Figure 1: Overview of the proposed framework. WSI patch features Fpatch and learnable tokens Q are processed by a transformer to form complete WSI features H. These are used with text prompts Ptext in a VLM to generate reports Ygen.
In-Context Learning Mechanisms
Nearest Neighbor Retrieval
PathGenIC utilizes the nearest neighbor approach to bolster report accuracy by retrieving similar WSI-report pairs from the training set. Cosine similarity guides the selection process, providing a relevant textual context to enhance report generation precision.
Category Guidance and Feedback
Recognizing that diagnostic accuracy varies with the disease category, PathGenIC employs GPT-4o to craft a representative report guideline from existing reports within the same category. Additionally, feedback loops are implemented where the model assesses its own outputs against ground truth, incorporating reflective contextual insights to iteratively improve report generation.
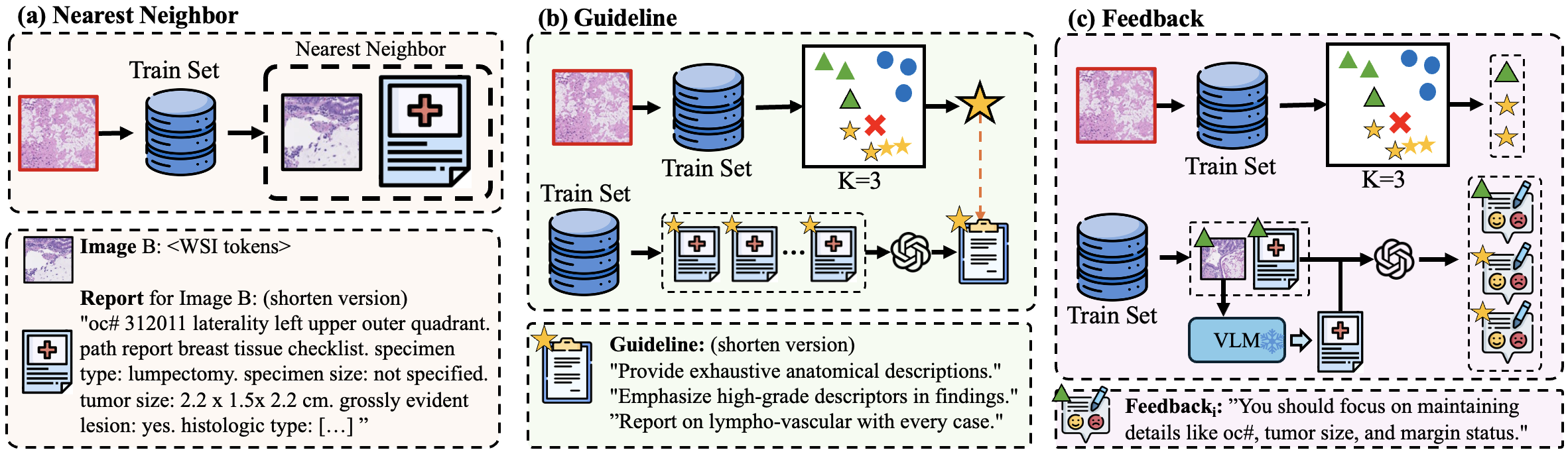
Figure 2: Illustrations of three different clues for in-context learning.
Experimental Evaluation
PathGenIC's efficacy was rigorously tested on the HistGen dataset, incorporating BLEU, METEOR, and ROUGE-L metrics as performance indicators. The results demonstrate clear superiority over existing models, underscoring its ability to handle diverse report lengths and disease categories. Additional metrics such as Exact Entity Match Reward (factENT) further substantiate its proficiency in capturing domain-specific entities.
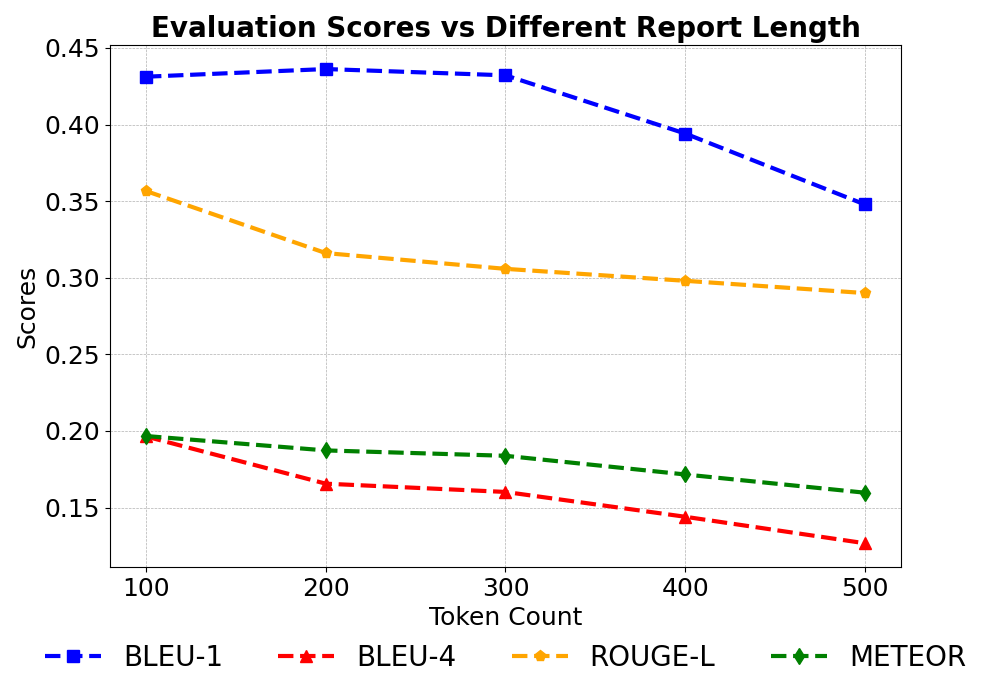
Figure 3: Performance across varying sequence lengths (100 to 500 tokens).
Results and Discussion
Table 1 illustrates PathGenIC's superior performance in comparison to prior frameworks. Notably, it achieves higher BLEU and METEOR scores, reflecting enhanced lexical similarity and semantic relevance. This improvement is also observed across different report lengths, albeit with a slight decline as length increases due to the complexity of maintaining coherence in extended text.
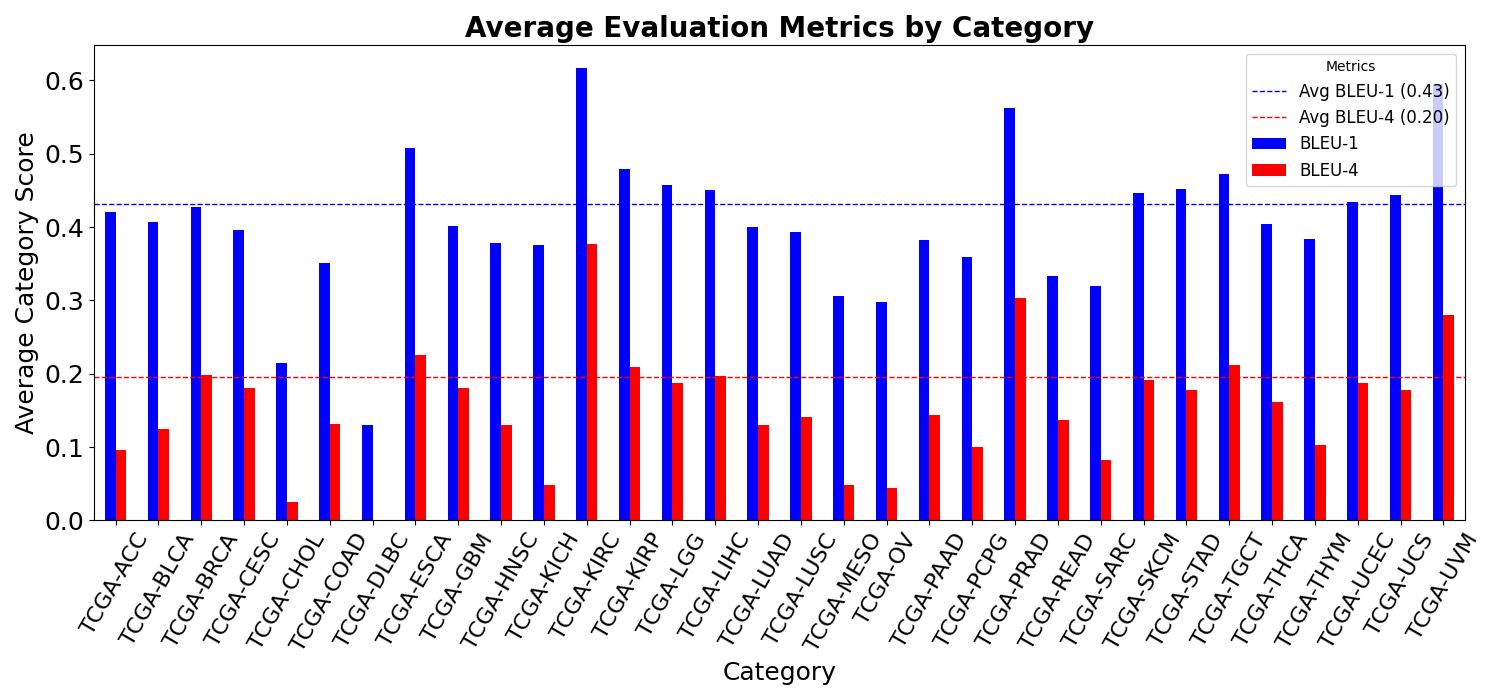
Figure 4: BLEU scores across the 32 disease categories.
Contribution of In-Context Learning
The integration of additional contextual information such as nearest neighbor cues, category guidelines, and feedback significantly improves PathGenIC's report generation capabilities. Ablation studies confirm that each component positively impacts performance, with maximal gains achieved through their combined application.
Conclusion
PathGenIC offers a robust framework for advancing automated histopathology report generation by integrating multimodal in-context learning mechanisms. Future research should consider larger-scale evaluations and refinements in ICL techniques, potentially expanding the framework's applicability to broader clinical tasks. This work forms a foundational step towards sophisticated AI-driven diagnostic tools that effectively integrate visual and textual data in medical imaging contexts.